 弹吉他的兔子
弹吉他的兔子
1、什么是函数
- 函数用于执行一个任务
- go语言最少有一个main()函数,入口
- 你可以通过函数来划分不同的功能,逻辑上每个函数执行的是指定的任务
- 函数声明告诉编译器函数的名称、入参、返回类型
main函数是程序的入口,自上而下的顺序执行。
函数是一段代码的集合,是一种封装思维
函数声明格式:
func function_name([parameter list]) [return type] {
函数体
}
func main() {
fmt.Println("hello world")
fmt.Println(add(1, 2))
}
// func 函数名(参数1,参数2,...)函数调用后的返回值{
// 函数体
//}
func add(a, b int) int {
c := a + b
return c
}
func main() {
fmt.Println("hello world")
fmt.Println(add(1, 2))
x, y := swap("学相伴", "kuangshen")
fmt.Println(x, y)
// 匿名变量
m, _ := swap("hello", "world")
fmt.Println(m)
fun1(2,4)
}
// 无参无返回函数
func printlinfo() {
fmt.Println("printinfo")
}
// 有一个入参的函数
func myprint(msg string) {
fmt.Println(msg)
}
// 有两个入参一个出参的函数
func add(a, b int) int {
c := a + b
return c
}
// 有多个返回值的函数
func swap(x, y string) (string, string) {
return y, x
}
// 返回周长,面积,返回值可以命名
// return的结果值命名 和 定义函数返回值的命名无关 ,其他语言没有的特性
func fun1(len,wid float64) (zc float64,area float64) {
area = len * wid
zc = (len + wid) * 2
// return area,zc // 返回面积,周长 8 12
return // 返回周长,面积 与上面定义函数返回值的命名一致 12 8
}
// 更习惯这种,可读性更好, java
func fun2(len,wid float64) (float64,float64) {
area := len * wid
zc := (len + wid) * 2
return area,zc // 返回面积,周长
}
执行结果:
hello world
3
kuangshen 学相伴
world
2、形式参数和实际参数
func main() {
// 实际参数,1和2,调用函数时,传给形参的实际数据叫做实际参数
// 形参与实参要一一对应,顺序,个数,类型
result := max(1, 2)
}
// 形式参数:num1,num2,用来接收外部传入数据的参数,就是形式参数
func max(num1, num2 int) int {
var result int
if num1 > num2 {
result = num1
} else {
result = num2
}
// 返回值,调用处需要使用变量接收该结果
return result
}
3、可变参数
java支持可变参数,go也支持了,java的声明格式如下:
// 参数为可变参数,mybatisplus的querywarpper条件的in就是支持可变参数的
public static void element(Integer...args){}
// 参数为数组
public static void element(Integer[] args){}
一个函数的参数类型确定,但是个数不确定,就可以使用可变参数
func myfunc (arg ...int){
}
// arg ...int 告诉go这个函数接收不确定数量的参数,类型全部是int
例子,可变个参数求和
func main() {
getSum(1, 2, 3, 4, 5, 6, 7, 8, 100)
getSum() // 打印 sum = 0
}
// ... 可变参数
func getSum(nums ...int) {
fmt.Printf("nums的类型是%T\n",nums) // nums的类型是 []int
sum := 0
for i := 0; i < len(nums); i++ { // len()获取可变参数的长度
fmt.Println(nums[i]) // 根据下标取值
sum += nums[i]
}
//fmt.Printf("sum:%d", sum)
fmt.Println("sum:", sum)
}
执行结果:
nums的类型是[]int
1
2
3
4
5
6
7
8
100
sum:136
发现上面可变参数nums的数据类型是切片(动态数组,相当于java的ArrayList)
我们发现Println()函数也是支持可变参数的,点击源码
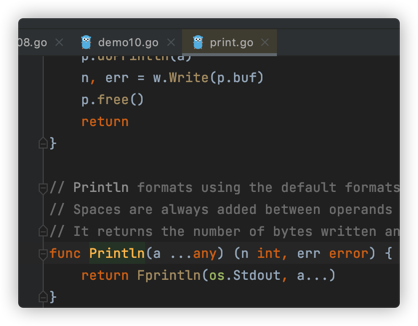

入参any是一个接口,它可以传任何值
// any is an alias for interface{} and is equivalent to interface{} in all ways.
type any = interface{}
注意:
- 如果一个函数的参数是可变参数,同时还有其他参数,可变参数必须要放在参数列表的最后
- 一个函数的参数列表最多只能有一个可变参数
4、参数传递
按照数据的存储特点来分:任何高级语言如java,c++都是这样子的
- 值类型的数据:操作的是数据本身,如int、string、bool、float、array,我理解就是复制了一份数据给形参(拷贝动作)
- 引用类型的数据:操作的是数据的地址 ,如 slice 切片类型、map、chan 通道
值传递
func main() {
// 值传递
// 定义一个数组,格式:[个数]类型
arr := [4]int{1, 2, 3, 4}
// 打印数组
fmt.Println(arr)
update(arr)
fmt.Println("调用修改后的数据:", arr)
// 值传递的核心:传递的是数据的副本,修改数据,对原始数据没有影响
// 基础类型 、array数组、struct结构体 都是值传递
}
func update(arr2 [4]int) {
fmt.Println("arr2接收的数据:", arr2)
arr2[0] = 100
fmt.Println("arr2修改后的数据:", arr2)
}
执行结果:
arr2接收的数据: [1 2 3 4]
arr2修改后的数据: [100 2 3 4]
调用修改后的数据: [1 2 3 4]
发现调用后的数组arr的值没有改变的,说明arr与arr2是两份不同的数据,调用update函数进行了拷贝动作将arr的数据复制给arr2,update函数对于原始数据arr没有影响
- 值传递的核心:传递的是数据的副本,修改数据,对原始数据没有影响
- 基础类型 、array数组、struct结构体 都是值传递
引用传递
引用类型的数据:操作的是数据的地址 ,如 slice 切片类型、map、chan 通道
切片,是可以扩容的数组,声明格式:
func main(){
s1:=[]int{1,2,3,4} // 切片没有指定数组大小
}
func main() {
// 切片
s1 := []int{1, 2, 3, 4}
fmt.Println("默认的数据:", s1)
update2(s1)
fmt.Println("调用后的数据:", s1)
}
func update2(s2 []int) {
fmt.Println("传递的数据", s2)
s2[0] = 100
fmt.Println("修改后的数据:", s2)
}
执行结果:
默认的数据: [1 2 3 4]
传递的数据 [1 2 3 4]
修改后的数据: [100 2 3 4]
调用后的数据: [100 2 3 4]
引用类型传递的是数据地址,值传递是数据副本
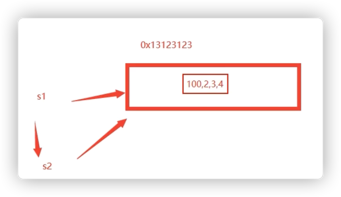

5、函数变量的作用域
作用域:变量可以使用的范围
- 局部变量:函数内部定义的变量
- 全局变量:函数外部定义的变量
局部 变量遵循就进原则
// 全局变量 num
var num = 100
func main() {
// 函数体内的局部变量 temp
temp := 100
if b := 1; b <= 10 {
// 语句内的局部变量 b
temp := 50
fmt.Println(temp) // 局部变量,就近原则
fmt.Println(b)
}
fmt.Println(temp)
fmt.Println(num)
}
func f1(){
fmt.Println(num)
}
变量的生命周期有三层:全局、函数体内的局部变量、语句内的局部变量,注意就近原则
6、递归函数
定义:一个函数自己调用自己
注意:递归函数需要有一个出口,逐渐向出口靠近,没有出口就形成死循环
递归深度不要过深,否则栈溢出,函数每递归调用自己就相当于压栈一次,占着内存,直到出口

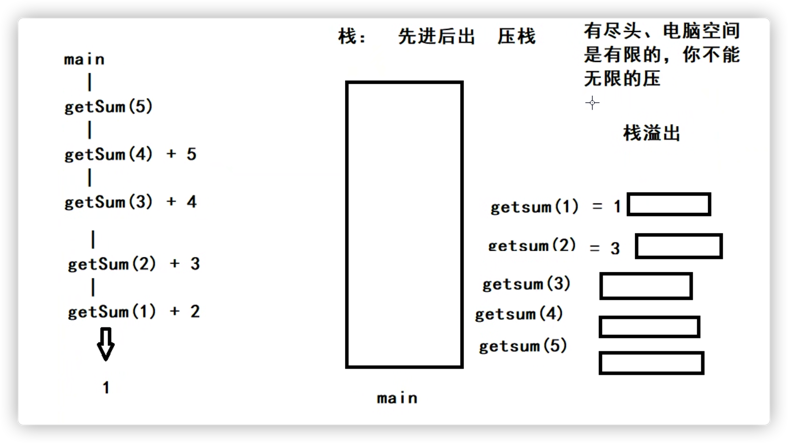

示例:
func main() {
sum := getSum(5)
fmt.Println(sum)
}
func getSum(n int) int {
if n == 1 {
return 1
}
return getSum(n-1) + n
}
执行结果:
15
递归实现斐波拉契数
斐波那契数:0,1,1,2,3,5,8,13
从第三项开始,等于前面两个数的和,也就是说第一项和第二项,有明确的值
func main() {
for i := 0; i < 8; i++ {
fmt.Println(feibo(i))
}
}
// 递归计算 费波那契数列 0,1,1,2,3,5,8,13
func feibo(n int) int{
if n == 0 {
return 0
} else if n==1 {
return 1
} else if n<0 {
return -1
}else {
return feibo(n-1) + feibo(n-2)
}
}
执行结果:
0
1
1
2
3
5
8
13
7、defer延迟函数执行
defer的语义:延迟
go语言中,使用defer关键字来延迟一个函数或者方法的执行
func main() {
f("1")
fmt.Println("2")
defer f("3")
fmt.Println("4")
}
func f(s string) {
fmt.Println(s)
}
执行结果:
1
2
4
3
发现最后才打印3
函数体内有多个defer语句会怎样?
-
函数中有多个defer语句,当函数执行到最后时,这些defer语句会按照逆序执行,最后函数返回
场景:当你进行一些打开资源操作时,遇到错误需要提前返回,在返回前你需要关闭相应的资源,就可以使用defer关键字,避免资源泄漏问题
所以:如果有多个调用defer,那么defer采用的是后进先出模式(栈)
func main() {
f("1")
fmt.Println("2")
defer f("3") // 会被延迟到最后执行,优先级3
fmt.Println("4")
defer f("5") // 会被延迟到最后执行,优先级2
fmt.Println("6")
defer f("7") // 会被延迟到最后执行,优先级1
fmt.Println("8")
}
func f(s string) {
fmt.Println(s)
}
执行结果:
1
2
4
6
8
7
5
3
defer调用函数的参数是什么时候传递进去,看一个例子:
// defer 常用于关闭操作,关闭网络,关闭文件
func main() {
a := 10
fmt.Println(a)
defer f(a) // 参数这时已经传递进去了,在最后执行
a++
fmt.Println("end a=", a)
}
func f(s int) {
fmt.Println("函数里面的a=", s)
}
执行结果:
10
end a= 11
函数里面的a= 10
发现最后执行f函数打印的a是10,说明在调用defer时,参数已经传递进去了,只是在最后才执行
总结:
defer的用法
-
对象.close() 临时文件的删除,就像java里的finally关键字,思想是一样的,只是使用上语法不一样
文件.open() defer.close() 读或写操作 -
go语言中关于异常的处理,使用panic()和recover()
- panic() 函数用于引发恐慌,导致程序中断执行
- recover() 函数用于恢复程序的执行,recover()语法上要求必须在defer中执行
8、函数的高阶使用
函数的数据类型
函数本身是func() 数据类型
func main() {
// f1 如果不加括号,函数就是一个变量
fmt.Printf("%T\n", f1) // func
fmt.Printf("%T\n", 10) // int
fmt.Printf("%T\n", "hello") // string
}
func f1() {
}
执行结果:
func()
int
string
func main() {
// f1 如果不加括号,函数就是一个变量
fmt.Printf("%T\n", f1) // func
fmt.Printf("%T\n", 10) // int
fmt.Printf("%T\n", "hello") // string
}
func f1(a, b int) int {
return a + b
}
执行结果:
func(int, int) int
int
string
函数本身是func() 数据类型,所以可以定义函数类型的变量
func main() {
// f1 如果不加括号,函数就是一个变量
fmt.Printf("%T\n", f1) // func
//fmt.Printf("%T\n", 10) // int
// fmt.Printf("%T\n", "hello") // string
// 定义函数类型的变量
var f5 func(int, int) = f1 // 引用类型传递
fmt.Println(f5)
fmt.Println(f1)
f5(1, 2)
}
// 声明一个函数,就是开辟一块内存空间,存储的是代码块
func f1(a, b int) {
fmt.Println(a, b)
}
执行结果:
func(int, int)
0x108eb60
0x108eb60
1 2
发现 f5与f1的内存地址是一样的,说明使用的同一个函数变量


函数的本质
函数在go语言中是复合类型,可以看做是一种特殊的变量
函数名() : 调用
函数名:指向函数体的内存地址,一种特殊类型的指针变量
匿名函数
func main() {
f1()
f2 := f1 // 函数本身就是一个变量
f2()
}
func f1() {
fmt.Println("我是f1函数")
}
执行结果:
我是f1函数
我是f1函数
func main() {
f1()
f2 := f1 // 函数本身就是一个变量
f2()
// 匿名函数赋值给一个变量,调用
f3 := func() {
fmt.Println("我是f3函数")
}
f3() // 调用
// 匿名函数自己调用
func() {
fmt.Println("我是f4函数")
}()
// 匿名函数传递参数
func(a, b int) {
fmt.Println(a, b)
fmt.Println("我是f5函数")
}(1, 2)
// 匿名函数返回值, 需要一个变量去接收
r1 := func(a, b int) int {
return a + b
}(1, 2)
fmt.Println(r1)
}
func f1() {
fmt.Println("我是f1函数")
}
执行结果:
我是f1函数
我是f1函数
我是f3函数
我是f4函数
1 2
我是f5函数
3
函数可以做为变量传递给函数的形参数,java的lambda表达式、函数式接口就是体现函数是一个变量,这就是函数式编程
- 将匿名函数作为另外一个函数的参数,回调函数
- 将匿名函数作为另外一个函数的返回值,可以形成闭包结构
Java支持回调函数,但是没有闭包结构的概念。
回调函数
使我想起java的CompleteableFuture异步执行回调 和 4大函数式接口,callback回调
高阶函数:可以将一个函数作为另外一个函数的参数
fun1(),fun2()
将fun1作为fun2这个函数的参数 ,即 fun1(fun2)
fun2函数:就叫做高阶函数,接收了一个函数作为参数的函数
fun1函数:就叫做回调函数,作为另外一个函数的参数
func main() {
r1 := add(1, 2)
fmt.Println(r1)
r2 := oper(3, 4, add)
fmt.Println(r2)
r3 := oper(8, 4, sub)
fmt.Println(r3)
// 使用匿名函数作为参数
r4 := oper(8, 4, func(a, b int) int {
if b == 0 {
fmt.Println("除数不能为0")
return 0
}
return a / b
})
fmt.Println(r4)
}
// 高阶函数,可以接收一个函数作为参数
func oper(a, b int, fun func(int, int) int) int {
// fmt.Printf("%T,%p\n", fun, fun)
r := fun(a, b)
return r
}
func add(a, b int) int {
return a + b
}
func sub(a, b int) int {
return a - b
}
执行结果
3
7
4
2
闭包结构
每次外层函数调用都会创建一个新的闭包结构,它不会随着外层函数的结束而销毁,它的生命周期是跟内层函数一致的,因为内层函数还在继续使用,那么内层函数对应的闭包结构就会继续使用
/*
一个外层函数中,有内层函数,该内层函数中,会操作外层函数的局部变量
并且该外层函数的返回结果就是这个内层函数
这个内层函数和外层函数的局部变量,统称为闭包结构
这个局部变量的生命周期就会发生改变,正常的局部变量会随着函数的调用而创建,随着函数的结束而销毁
但是闭包结构中的外层函数的局部变量并不会随着外层函数的结束而销毁,因为内层函数还在继续使用
*/
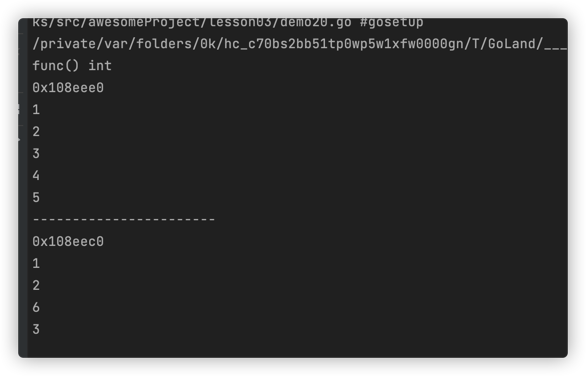
func main() {
r1 := increment() // 调用外层函数,创建闭包结构i
fmt.Printf("%T\n", r1)
fmt.Println(r1) // 打印内存地址0x108ef40
v1 := r1() // 内层函数调用
fmt.Println(v1) // 1
v2 := r1()
fmt.Println(v2) // 2
fmt.Println(r1()) // 3
fmt.Println(r1()) // 4
fmt.Println(r1()) // 发现闭包结构i会一直自增
fmt.Println("-----------------------")
r2 := increment() // 调用外层函数,创建闭包结构i
fmt.Println(r2) // 打印内存地址0x108ef20 与r1的内存地址不一致,说明两个不同的变量
v3 := r2() // 内层函数调用
fmt.Println(v3) // 1
fmt.Println(r2()) // 2
fmt.Println(r1()) // 6 内层函数r1的闭包结构依然存在
fmt.Println(r2()) // 2
}
// 自增,返回一个函数
func increment() func() int {
i := 0 // 这个局部变量就统称为闭包结构
fun := func() int {
i++
return i
}
return fun
}
执行结果:

我们未来分析开源框架的代码,会经常使用回调函数与闭包,所以要读懂
打印费波那契数列 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233……
func main() {
for i := 0; i < 8; i++ {
fmt.Println(feibo2(i))
}
}
// 闭包计算 费波那契数列 0,1,1,2,3,5,8,13
func feibo2(n int) int{
if n<0 {
return -1
}else{
f := feibonacci()
result := 0
for i := 0; i < n; i++ {
result = f()
}
return result
}
}
func feibonacci() func() int{
a,b:=0,1
return func() int {
a,b = b,a+b
return a
}
}
执行结果:
0
1
1
2
3
5
8
13