 弹吉他的兔子
弹吉他的兔子
1. 读写锁

读写分离,框架底层都是使用读写锁的
写锁:又叫独占锁,一次只能被一个线程占有 读锁:又叫共享锁,该锁可以被多个线程占有
理解下面的例子
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
public class ReadWriteLockDemo {
public static void main(String[] args) {
// MyCache myCache = new MyCache(); 不加读写锁
final MyCacheLock myCache = new MyCacheLock();
// 模拟线程
// 写
for (int i = 0; i <=5; i++) {
final int tempInt = i; // 这里有个知识点,线程内是拿不到外面的值,除非它是一个final常量(常量池)
new Thread(()->{
myCache.put(tempInt +"",tempInt+"");
}).start();
}
// 读
for (int i = 0; i <=5; i++) {
final int tempInt = i;
new Thread(()->{
myCache.get(tempInt+"");
}).start();
}
}
}
// 不加读写锁的资源类
// 资源类,读写
class MyCache{
// volatile 保证变量的可见性,线程对变量的修改对所有线程来说都是可见的,变量值的存取一定是
// 在共享内存中进行的。
private volatile Map<String,Object> map = new HashMap<String, Object>();
// 读
public void get(String key){
System.out.println(Thread.currentThread().getName()+"读取" + key);
Object o = map.get(key);
System.out.println(Thread.currentThread().getName()+"读取结果:"+o);
}
// 写 ,应该保证原子性,不应该被打扰
public void put(String key,Object value){
System.out.println(Thread.currentThread().getName()+"写入"+key);
map.put(key,value);
System.out.println(Thread.currentThread().getName()+"写入完成");
}
}
// 资源类,读写,模拟从数据库或者缓冲中获取数据
class MyCacheLock{
// volatile 保证变量的可见性,线程对变量的修改对所有线程来说都是可见的,变量值的存取一定是
// 在共享内存中进行的,不是在自己的栈内存进行
private volatile Map<String,Object> map = new HashMap<String, Object>();
// 读写锁有两把锁: 读锁 + 写锁
private ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
// 读 可以被多个线程同时读
public void get(String key){
// 锁一定要匹配,否则可能导致死锁
readWriteLock.readLock().lock();
try {
System.out.println(Thread.currentThread().getName()+"读取" + key);
Object o = map.get(key);
System.out.println(Thread.currentThread().getName()+"读取结果:"+o);
}catch (Exception e){
e.printStackTrace();
}finally {
// 要手动释放锁,不是Synchronized
readWriteLock.readLock().unlock();
}
}
// 写,保证原子性,独占
public void put(String key,Object value){
// 加写锁
readWriteLock.writeLock().lock();
try {
System.out.println(Thread.currentThread().getName()+"写入"+key);
map.put(key,value);
System.out.println(Thread.currentThread().getName()+"写入完成");
} catch (Exception e) {
e.printStackTrace();
} finally {
// 释放锁
readWriteLock.writeLock().unlock();
}
}
}
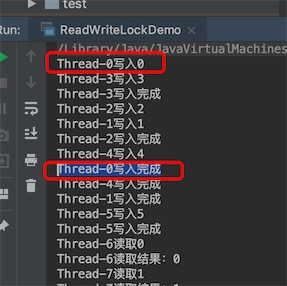
不加读写锁的MyCache执行结果:很明显写入不能保证原子性,Thread0在写入到写入完成,中间被插队了
ReadWriteLock其实是两把锁

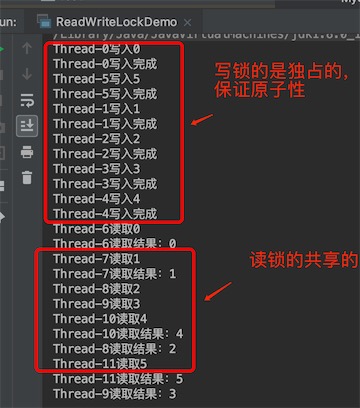
加了读写锁的MyCacheLock执行结果:很明显的保证了写的原子性,没有被打断,读却是共享的
2. 阻塞队列BlockingQueue
简介
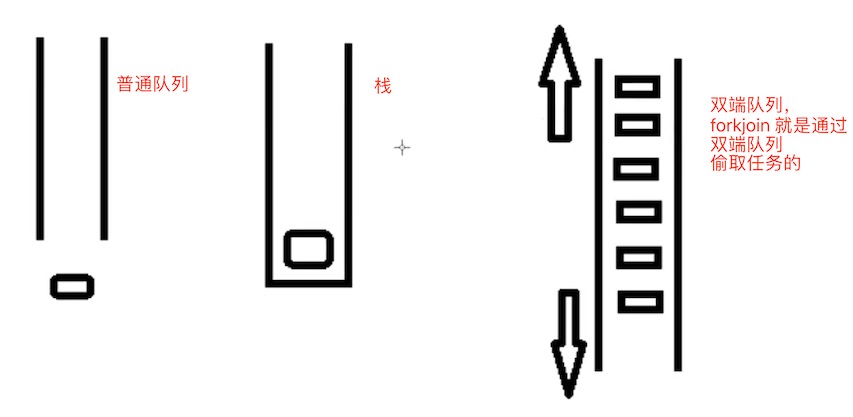
队列:FIFO,先进先出
栈:Stack,后进先出
1、为什么要用阻塞队列
在写多线程序的时候,如果不关心通过唤醒的方式实现线程间的通信,可以使用阻塞队列解决。应用场景:
-
使用场景生产者和消费者模型
生产者生产数据,放入队列,然后消费者从队列中获取数据,这个在一般情况下自然没有问题,但出现消费者速度远大于生产者速度,消费者在数据消费至一定程度的情况下,可以阻塞消费者来等待生产者,以保证生产者能够生产出新的数据;反之亦然
-
使用场景线程池,在线程池中,当提交的任务不能被立即得到执行的时候,线程池就会将提交的任务放到一个阻塞的任务队列中。
同样是写代码,但是有的人只会基础代码,记住,技多不压身
扩展阅读:https://www.cnblogs.com/NathanYang/p/11276428.html
2、什么情况队列会阻塞
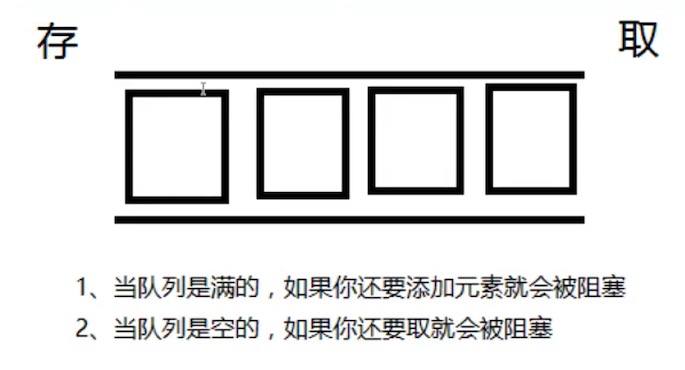
- 当队列是满的,你还要添加元素就会被阻塞;
- 当队列是空的,你还要取元素就会被阻塞;
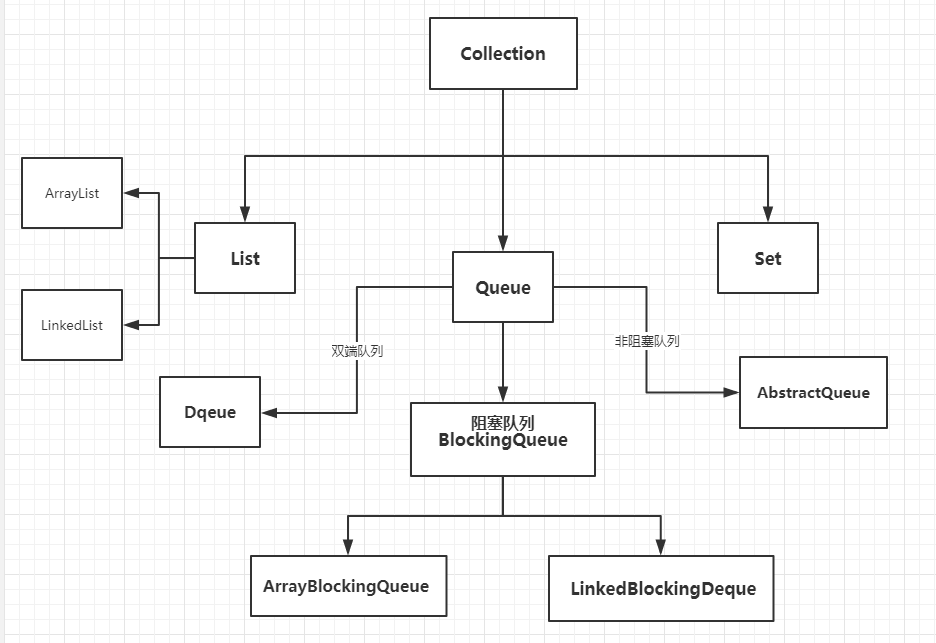
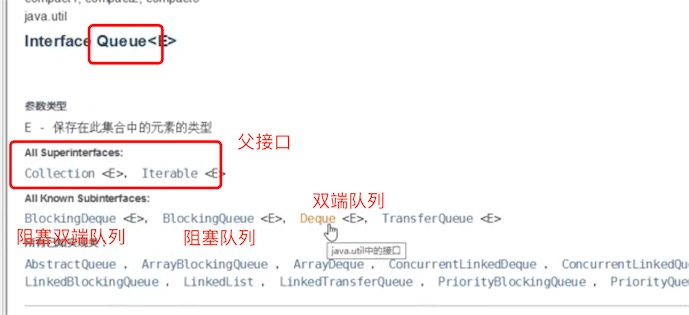
3、Collection家族
阻塞队列是一个新东西吗,跟List、set 一样,它们的父类都是Collection
四组API
| 方法 | 会抛异常 | 返回布尔值,不抛异常 | 延时等待 | 一直等 |
|---|---|---|---|---|
| 插入 | add(e) | offer(e) | offer(e, time) | put(e) |
| 取值 | remove() | poll() | poll(time) | take() |
| 检查 | element() | peek() |
建议add与remove一组,offer与poll一组
public class BlockingQueueDemo {
public static void main(String[] args) throws InterruptedException {
// 容量为3
ArrayBlockingQueue blockingQueue = new ArrayBlockingQueue(3);
// 1、第一组 add与remove
blockingQueue.add("a");
blockingQueue.add("b");
blockingQueue.add("c");
//blockingQueue.add("d"); // 队列满了,抛出异常:java.lang.IllegalStateException: Queue full
System.out.println(blockingQueue.remove()); // 取值
System.out.println(blockingQueue.element()); // 返回第一个元素,没有会抛异常
System.out.println(blockingQueue.peek()); // 返回第一个元素,没有返回null,不抛异常
// 2、第二组 offer与poll
System.out.println(blockingQueue.offer("a")); // 放入成功返回true
System.out.println(blockingQueue.offer("b"));
System.out.println(blockingQueue.offer("c"));
System.out.println(blockingQueue.offer("d",3, TimeUnit.SECONDS)); //延时等待3秒,放入失败返回false,不抛异常
System.out.println(blockingQueue.poll()); // 取值
System.out.println(blockingQueue.poll()); // 取值
System.out.println(blockingQueue.poll()); // 取值
System.out.println(blockingQueue.poll(3,TimeUnit.SECONDS)); //延时等待3秒,没有值返回null
// 3、第三组 put与take
blockingQueue.put("a");
blockingQueue.put("b");
blockingQueue.put("c");
System.out.println("准备放入第4个元素");
blockingQueue.put("d"); // 队列满了,一直等,并且会阻塞
System.out.println(blockingQueue.take());
System.out.println(blockingQueue.take());
System.out.println(blockingQueue.take());
System.out.println(blockingQueue.take()); // 队列空了,一直等,并且会阻塞
}
}
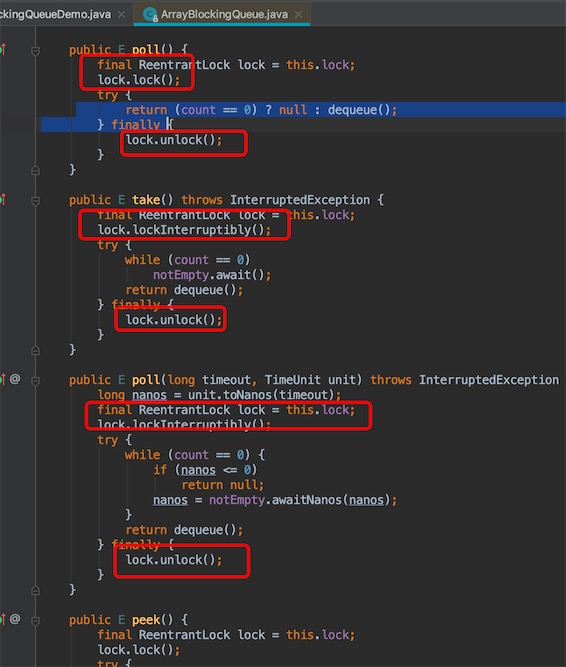
点进ArrayBlockingQueue的源码,发现底层都加了锁
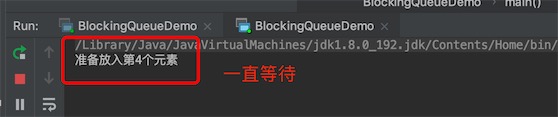
第三组put 的 执行结果:
队列满了,一直等,并且会阻塞;队列空了,一直等,并且会阻塞
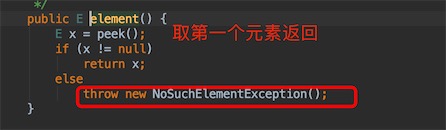
element()的底层源码
3. 同步队列SynchronousQueue
SynchronousQueue是BlockingQueue下的一个实现类,它是没有容量的。每一个put操作,就需要有一个 take操作!

应用场景:一对一的通信
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.SynchronousQueue;
import java.util.concurrent.TimeUnit;
public class SynchronousQueueDemo {
public static void main(String[] args) throws InterruptedException {
// 同步队列,特殊的阻塞队列,多态,只有一个容量
BlockingQueue<String> blockingQueue = new SynchronousQueue<>();
// A存
new Thread(()->{
try {
System.out.println(Thread.currentThread().getName() +"put a");
blockingQueue.put("a");
System.out.println(Thread.currentThread().getName() +"put b");
blockingQueue.put("b");
System.out.println(Thread.currentThread().getName() +"put c");
blockingQueue.put("c");
} catch (InterruptedException e) {
e.printStackTrace();
}
},"A").start();
// B取
new Thread(()->{
try {
TimeUnit.SECONDS.sleep(3); // 延时3秒,看到效果
System.out.println(Thread.currentThread().getName() + "take " +blockingQueue.take());
TimeUnit.SECONDS.sleep(3);
System.out.println(Thread.currentThread().getName() + "take " +blockingQueue.take());
TimeUnit.SECONDS.sleep(3);
System.out.println(Thread.currentThread().getName() + "take " +blockingQueue.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
},"B").start();
}
}
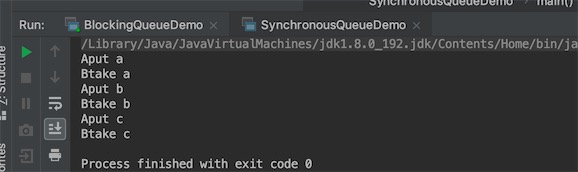
执行结果:
/*
目的:有两个线程:A B ,还有一个值初始为0,
实现两个线程交替执行,对该变量 + 1,-1;交替10次
*/
怎么用阻塞队列实现?想不到
4. 线程池
程序运行的本质:占用系统资源
为什么要用线程池的作用:线程复用,提高程序的效率。
阿里的开发手册
- 【强制】线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样
的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
说明:Executors 返回的线程池对象的弊端如下:
1)FixedThreadPool 和 SingleThreadPool:
允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM。2)CachedThreadPool 和 ScheduledThreadPool:
允许的创建线程数量为 Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM。
线程记住要点:三大方法、七大参数、4种拒绝策略
线程池的执行任务流程

Executors的三大方法
public class ThreadPoolDemo {
public static void main(String[] args) {
// 单例,只有一个线程
// ExecutorService threadPool = Executors.newSingleThreadExecutor();
// 固定的线程数
// ExecutorService threadPool = Executors.newFixedThreadPool(6);
// 可伸缩容量的线程池
// ExecutorService threadPool = Executors.newCachedThreadPool();
// 根据阿里巴巴开发手册,直接使用ThreadPoolExecuto创建线程池,
// 因为Executors的底层其实都是使用ThreadPoolExecuto创建线程池的。
ExecutorService threadPool = new ThreadPoolExecutor(2,5,3,TimeUnit.SECONDS
,new LinkedBlockingDeque<>(3),new ThreadPoolExecutor.AbortPolicy());
// 使用线程池
try {
for (int i = 0; i < 10; i++) {
threadPool.execute(()->{
System.out.println(Thread.currentThread().getName() + " ok");
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 关闭线程池
threadPool.shutdown();
}
}
}
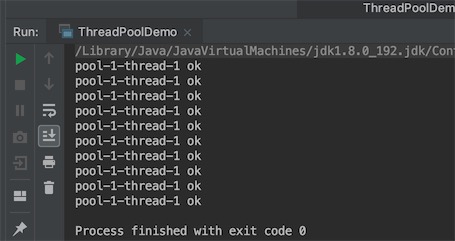
单例线程池的执行结果,池子里只有一个线程:
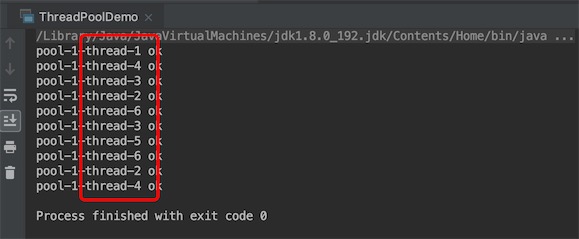
固定的线程数的线程池的执行结果,
可伸缩容量的线程池,线程数量根据服务器cpu性能动态调整
阿里巴巴为什么不允许使用 Executors 去创建线程池,而是通过 ThreadPoolExecutor 的方式?查看三个方法的源码



-
SingleThreadExecutor 单线程线程池
当一个任务提交时,首先会创建一个核心线程来执行任务,如果超过核心线程的数量,将会放入队列中,因为LinkedBlockingQueue是长度为Integer.MAX_VALUE的队列,可以认为是无界队列,因此往队列中可以插入无限多的任务,在资源有限的时候容易引起OOM异常,同时因为无界队列,maximumPoolSize和keepAliveTime参数将无效,压根就不会创建非核心线程
-
FixedThreadPool 固定核心线程数线程池
因为LinkedBlockingQueue是长度为Integer.MAX_VALUE的队列,因此往队列中可以插入无限多的任务,在资源有限的时候容易引起OOM异常
-
newCachedThreadPool
看newCachedThreadPool的源码,发现使用的同步队列 new SynchronousQueue,同步队列是一个不存储元素的队列,可以理解为你放一个任务给线程池,必须创建一个线程去从队列里拿出来执行。
当一个任务提交时,corePoolSize为0不创建核心线程,SynchronousQueue是一个不存储元素的队列,可以理解为队里永远是满的,因此最终会创建非核心线程来执行任务。对于非核心线程空闲60s时将被回收。因为Integer.MAX_VALUE非常大,可以认为是可以无限创建线程的,在资源有限的情况下容易引起OOM异常
七大参数
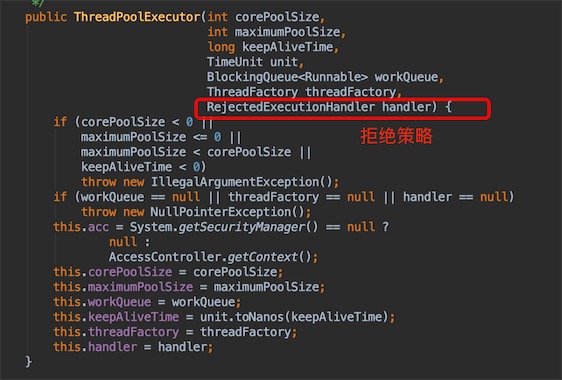
public ThreadPoolExecutor(
int corePoolSize, // 核心池线程数大小 (常用)
int maximumPoolSize, // 最大线程数大小 (常用)
long keepAliveTime, // 空闲线程等待任务的超时时间,超过则线程关闭 (常用)
TimeUnit unit, // 时间单位 (常用)
BlockingQueue<Runnable> workQueue, // 阻塞队列(常用)
ThreadFactory threadFactory, // 线程工厂
RejectedExecutionHandler handler // 拒绝策略(常用)) {
....
}
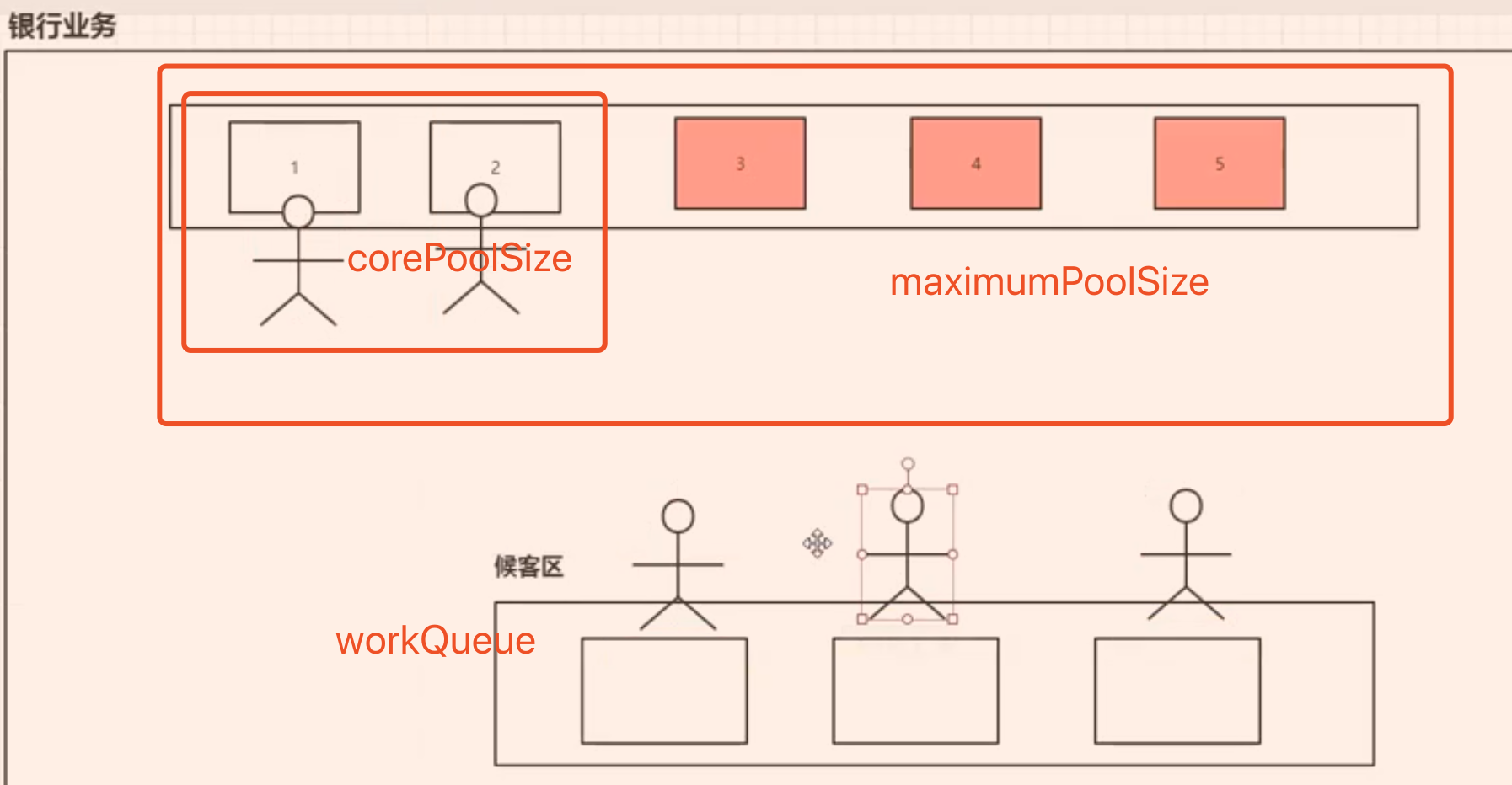
银行就是我们生活中的线程池例子
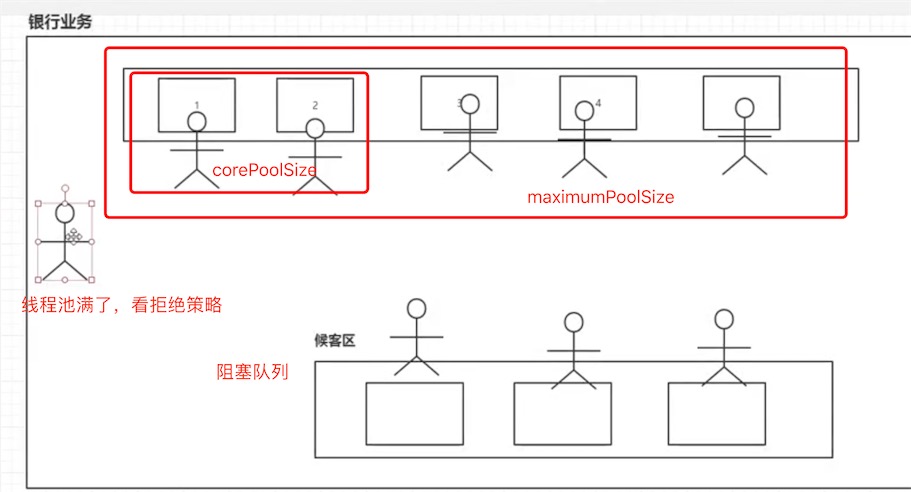
如果空闲线程等待超过keepAliveTime,就会把3、4、5线程关闭
用代码实现这个银行例子
public class ThreadPoolDemo {
public static void main(String[] args) {
ExecutorService threadPool = new ThreadPoolExecutor(
2,5,3, TimeUnit.SECONDS
,new LinkedBlockingDeque<>(3) // 容量为3的双端队列
,Executors.defaultThreadFactory() // 创建线程的工厂
,new ThreadPoolExecutor.AbortPolicy()); // 默认的拒绝策略
// 使用线程池
try {
for (int i = 0; i < 5; i++) {
threadPool.execute(()->{
System.out.println(Thread.currentThread().getName() + " ok");
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 关闭线程池
threadPool.shutdown();
}
}
}
执行结果:
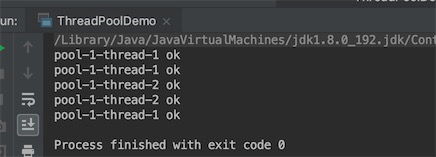
为什么开启2个线程就可处理5个任务,因为有3个任务在双端队列等待着,银行的例子相当于有3个人在侯客区等着
任务数调到6
for (int i = 0; i < 6; i++) {
threadPool.execute(()->{
System.out.println(Thread.currentThread().getName() + " ok");
});
}
执行结果:开启了第3个线程,银行的例子相当于开启了第3个窗口
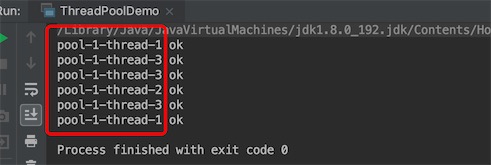
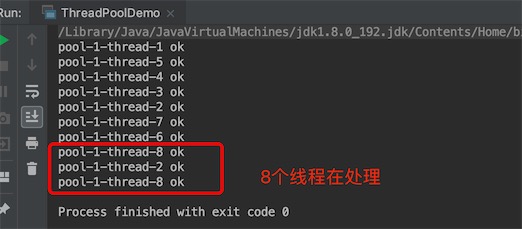
任务数调到8,5个线程满了
for (int i = 0; i < 8; i++) {
threadPool.execute(()->{
System.out.println(Thread.currentThread().getName() + " ok");
});
}
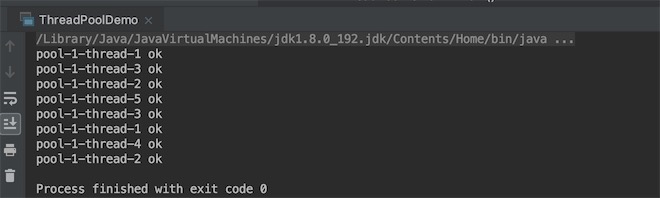
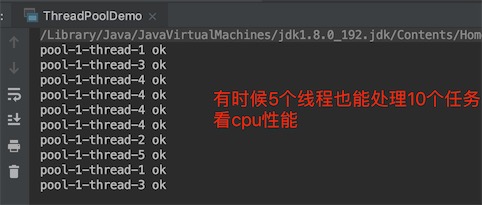
任务数调到10,5个线程满了,根据默认的拒绝策略ThreadPoolExecutor.AbortPolicy,就会丢弃任务,抛出异常,发现不一定,因为有时候线程处理的快,刚好腾出新的cpu资源给新的线程,看cpu的调度,如下
for (int i = 0; i < 10; i++) {
threadPool.execute(()->{
System.out.println(Thread.currentThread().getName() + " ok");
});
}

4种拒绝策略
点进ThreadPoolExecutor的源码
RejectedExecutionHandler是一个接口,点进源码看它的实现类
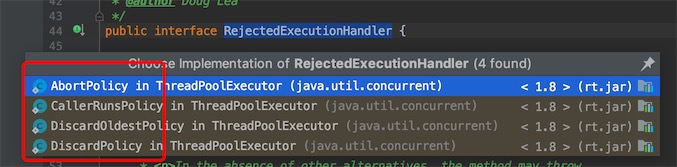
-
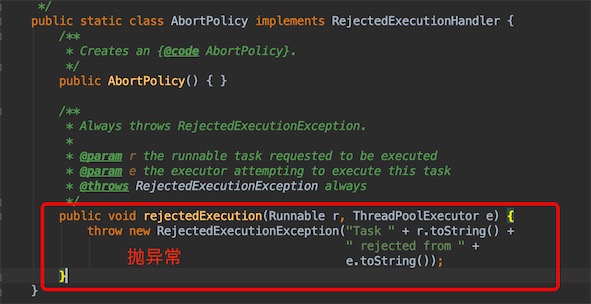
ThreadPoolExecutor.AbortPolicy(): 抛出异常,丢弃任务,默认的拒绝策略
-
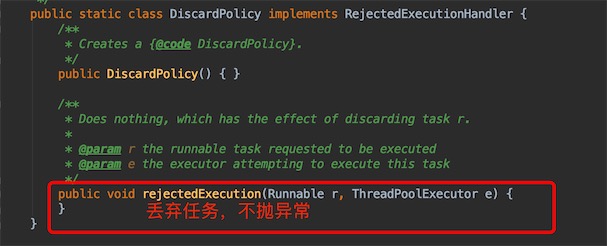
ThreadPoolExecutor.DiscardPolicy():不抛出异常,丢弃任务
-
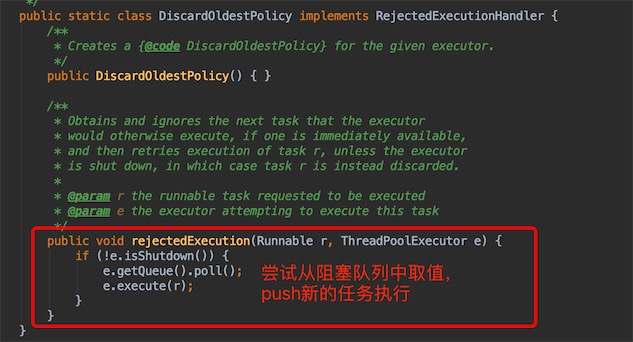
ThreadPoolExecutor.DiscardOldestPolicy():尝试获取任务,不一定执行!
-
ThreadPoolExecutor.CallerRunsPolicy():找调用方的线程去执行任务, 哪来的去哪里找对应的线程执行!此时主线程将在一段时间内不能提交任何任务,从而使工作线程处理正在执行的任务。此时提交的线程将被保存在TCP队列中,TCP队列满将会影响客户端,这是一种平缓的性能降低
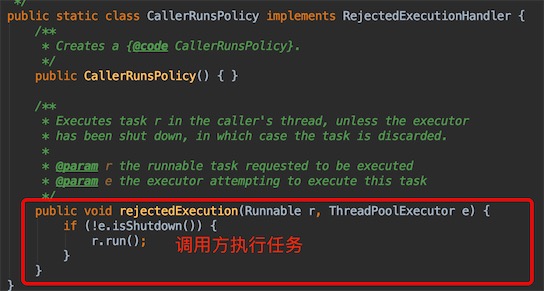
比如上面的代码是main函数调用线程池执行任务的,则线程池满了后会找main线程执行任务,看下面结果:
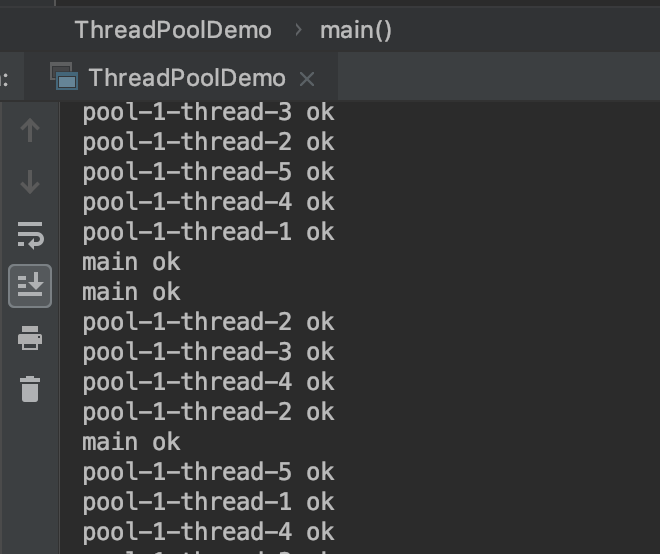
自定义拒绝策略,只需要实现RejectedExecutionHandler接口即可
可以通过使用Semaphore 信号量对任务的执行进行限流也可以避免出现OOM异常。
最大线程池数该如何设置?
并发:多个线程操作同一个资源,交替执行的过程
并行:多个线程同时执行,只有在多核CPU下才能完成
什么是最高效率:所有CPU同时执行
看任务类型是CPU密集型还是IO密集型
-
CPU密集型任务,比如:非常复杂的调用,循环次数很多,或者递归调用层次很深等
根据CPU的处理器数量来定,保证最大效率
如何服务器的cpu核数,通过JVM的Runtime运行时获取
// Returns the number of processors available to the Java virtual machine // 获取jvm可用的cpu处理器数量 System.out.println(Runtime.getRuntime().availableProcessors());执行结果:
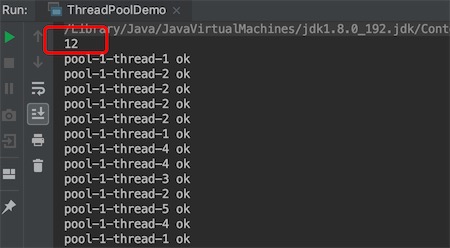
CPU密集型配置线程数经验值是:N + 1,其中N代表CPU核数,看上面获取N值。
-
IO密集型任务,比如:频繁读取磁盘上的数据,或者需要通过网络远程调用接口。
当进程操作大IO资源, 比较耗时,可以线程池稍微调大些。
IO密集型配置线程数经验值是:2N,其中N代表CPU核数。
-
使用有界阻塞队列避免资源耗尽的情况发生
-
最佳线程数算法
最佳线程数目 = ((线程等待时间+线程CPU时间)/线程CPU时间 )* CPU数目很显然线程等待时间所占比例越高,需要越多线程。线程CPU时间所占比例越高,需要越少线程。
虽说最佳线程数目算法更准确,但是线程等待时间和线程CPU时间不好测量,实际情况使用得比较少,一般用经验值就差不多了。再配合系统压测,基本可以确定最适合的线程数。
5. 四个函数式接口
在Java.util.function包下,核心的有4个接口:Consumer 、Function、Supplier、Predicate,其他的都是变体
我们都接触过函数式接口,Runnable 接口
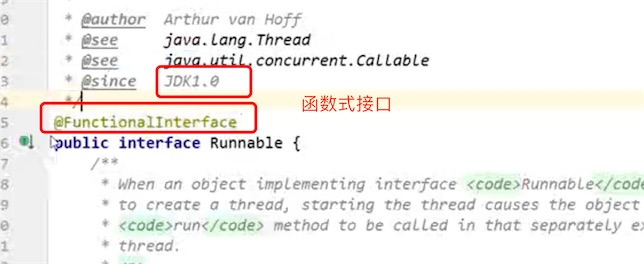
/**
- 函数式接口是我们现在必须要要掌握且精通的
- 4个!
- Java 8 *
- Function<T,R> : 有一个输入参数有一个输出参数
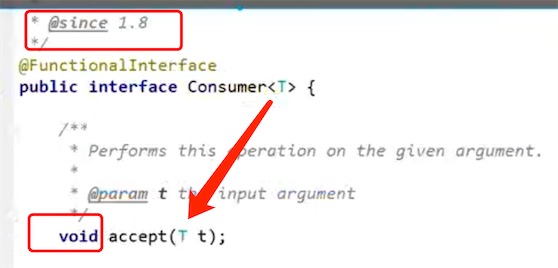
- Consumer
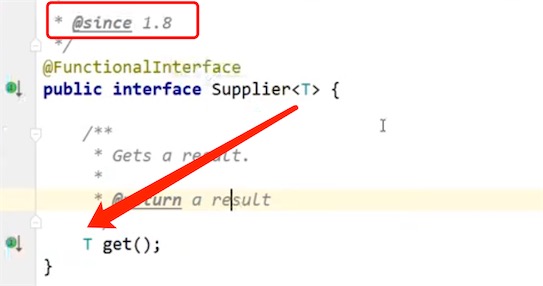
:有一个输入参数,没有输出参数 - Supplier
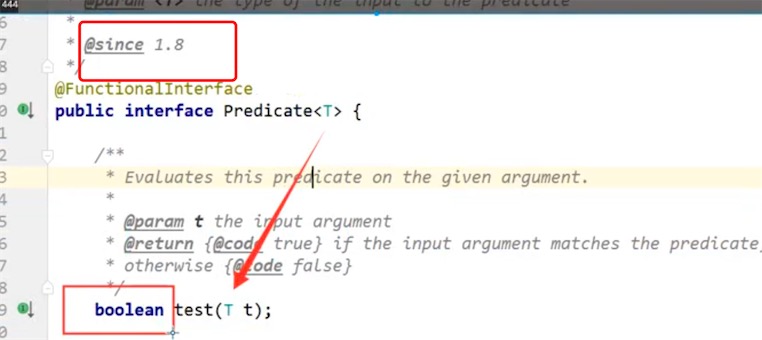
:没有输入参数,只有输出参数 - Predicate
:有一个输入参数,判断是否正确! */
Function
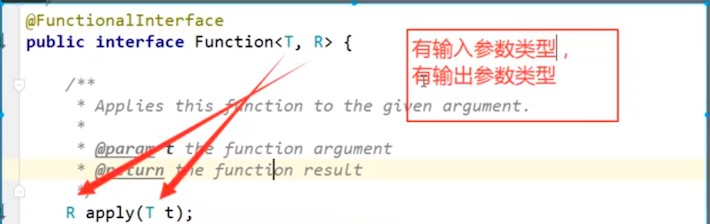
public static void main(String[] args) {
// (参数) -> {方法体}
Function<String,Integer> function = (str)->{
return str.length();
};
System.out.println(function.apply("helloworld")); // 10
}
Consumer
有一个输入参数,没有返回
Supplier
public static void main(String[] args) {
// 生产者
Supplier<String> supplier = ()->{
return "hello,spring";
};
// 消费者
Consumer<String> consumer =(str)->{
// 可以自己写一些功能性的要求
System.out.println(str);
};
consumer.accept(supplier.get());
}
Predicate
public static void main(String[] args) {
Predicate<String> predicate1 = (str)->{
return str.equals("123");
};
Predicate<String> predicate2 = (str)->{
return str.equals("456");
};
System.out.println(predicate1.test("123"));
// 连续判断
System.out.println(predicate1.and(predicate2).test("123"));
}
应用场景:判断用户登录
6. Stream流式计算
你现在的所有努力,都是让自己有选择的权利,而不是被选择
在java.util.stream包下,基于函数式接口实现的流式计算使代码简洁易读,提高开发效率。
大数据时代: 存储 + 计算
计算和处理数据交给 Stream 流,代码层面处理数据比数据库快
遍历操作
jdk7的操作
public List<Long> getUserIds(List<User> userList){
List<Long> userIds = new ArrayList<>();
for (User user : userList) {
userIds.add(user.getUserId());
}
return userIds;
}
采用stream后
public List<Long> getUserIds(List<User> userList){
List<Long> userIds = userList.stream().map(User::getUserId).collect(Collectors.toList());
return userIds;
}
筛选元素
public List<Long> getUserIds8(List<User> userList){
List<Long> userIds = userList.stream().filter(item -> item.getUserId() != null).map(User::getUserId).collect(Collectors.toList());
return userIds;
}
删除重复内容
public Set<Long> getUserIds(List<User> userList){
Set<Long> userIds = userList.stream().filter(item -> item.getUserId() != null).map(User::getUserId).collect(Collectors.toSet());
return userIds;
}
数据类型转换
例如有的系统,使用String接受,有的是用Long,对于这种场景,我们需要将其转换
public List<String> getUserIds10(List<Long> userIds){
List<String> userIdStrs = userIds.stream().map(x -> x.toString()).collect(Collectors.toList());
return userIdStrs;
}
数组转集合
public static void main(String[] args) {
//创建一个字符串数组
String[] strArray = new String[]{"a","b","c"};
//转换后的List 属于 java.util.ArrayList 能进行正常的增删查操作
List<String> strList = Stream.of(strArray).collect(Collectors.toList());
}
集合转Map操作
集合转map-不分组
在实际的开发过程中,还有一个使用最频繁的操作就是,将集合元素中某个主键字段作为key,元素作为value,来实现集合转map的需求,这种需求在数据组装方面使用的非常多,尤其是在禁止连表 sql 查询操作的公司,视图数据的拼装只能在代码层面来实现。
在 jdk7 中,将集合中的元素转 map,我们通常会采用如下方式。
public Map<Long, User> getMap(List<User> userList){
Map<Long, User> userMap = new HashMap<>();
for (User user : userList) {
userMap.put(user.getUserId(), user);
}
return userMap;
}
在 jdk8 中,采用 stream api的方式,我们只需要一行代码即可实现
public Map<Long, User> getMap(List<User> userList){
Map<Long, User> userMap = userList.stream().collect(Collectors.toMap(User::getUserId, v -> v, (k1,k2) -> k1));
return userMap;
}
测试代码如下:
public static void main(String[] args) {
List<Map<String,Object>> userList = new ArrayList<>(10);
Map<String,Object> user1 = new HashMap(3);
user1.put("id",1);
user1.put("name","array");
user1.put("age","10");
userList.add(user1);
Map<String,Object> user2 = new HashMap(3);
user2.put("id",2);
user2.put("name","gavin");
user2.put("age","12");
userList.add(user2);
Map<String,Object> user3 = new HashMap(3);
user3.put("id",3);
user3.put("name","jacob");
user3.put("age","13");
userList.add(user3);
Map<Object,Map<String,Object>> userMap = userList.stream().collect(Collectors.toMap(m->m.get("id"),v->v,(k1,k2)->k1));
System.out.println(userMap);
}
执行结果

点进Collectors.toMap的源码
public static <T, K, U>
Collector<T, ?, Map<K,U>> toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper,
BinaryOperator<U> mergeFunction) {
return toMap(keyMapper, valueMapper, mergeFunction, HashMap::new);
}
- 第一个参数:表示 key
- 第二个参数:表示 value
- 第三个参数:表示某种规则
上文中的Collectors.toMap(User::getUserId, v -> v, (k1,k2) -> k1),表达的意思就是将userId的内容作为key,v -> v是表示将元素user作为value,其中(k1,k2) -> k1表示如果存在相同的key,将第一个匹配的元素作为内容,第二个舍弃!
集合转map-分组
/**
* jdk7 将集合转换成Map,将相同的key,加入到一个集合中,实现分组
* @param userList
* @return
*/
public Map<Long, List<User>> getMapGroup(List<User> userList){
Map<Long, List<User>> userListMap = new HashMap<>();
for (User user : userList) {
if(userListMap.containsKey(user.getUserId())){
userListMap.get(user.getUserId()).add(user);
} else {
List<User> users = new ArrayList<>();
users.add(user);
userListMap.put(user.getUserId(), users);
}
}
return userListMap;
}
而在 jdk8 中,采用 stream api的方式,我们只需要一行代码即可实现
public Map<Long, List<User>> getMapGroup(List<User> userList){
Map<Long, List<User>> userMap = userList.stream().collect(Collectors.groupingBy(User::getUserId));
return userMap;
}
转map后,可以用来判断重复
//1.1 校验相同商户、账户
Map<String, List<TrxOiBillCreateReqDTO>> groupMap = settleList.stream().collect(Collectors.groupingBy(dto -> dto.getTenantCode() + "_" + dto.getMerchantCode() + "_" + dto.getAccountCode()));
if (1 < groupMap.size()) {
throw new BussinessException(SmcErrorEnum.BUSINESS_ERROR, "相同租户+商户+账户才能合并");
}
// 待结算单的业务单据类型为“销售单”的行集合处理(合并),按相同产品、价格、税率、折扣率分组
Map<String, List<TrxOiLineVO>> normalGroup = normalLineList.stream().collect(Collectors.groupingBy(line -> line.getItemCode() + "-" + line.getPrice() + "-" + line.getTaxRate() + "-" + line.getDiscount()));
normalGroup.forEach((key, list) -> {
TrxInvoiceBillLineEntity invoiceLine = this.createInvoiceLineWithDiscount(invoiceBill.getId(), lineNum, list);
if (Objects.nonNull(invoiceLine)) {
invoiceLineList.add(invoiceLine);
}
});
分页操作
将如下的数组从小到大进行排序,排序完成之后,从第1行开始,查询10条数据出来,操作如下:
//需要查询的数据
List<Integer> numbers = Arrays.asList(3, 2, 2, 3, 7, 3, 5,10, 6, 20, 30, 40, 50, 60, 100);
List<Integer> dataList= numbers.stream().sorted((x, y) -> x.compareTo(y)).skip(0).limit(10).collect(Collectors.toList());
System.out.println(dataList.toString());
其中skip参数表示第几行,limit表示查询的数量,类似页容量!
查找与匹配操作
-
allMatch(检查是否匹配所有元素)
List<Integer> list = Arrays.asList(10, 5, 7, 3); boolean allMatch = list.stream()// .allMatch(x -> x > 2);//是否全部元素都大于2 System.out.println(allMatch); -
findFirst(返回第一个元素)
List<Integer> list = Arrays.asList(10, 5, 7, 3); Optional<Integer> first = list.stream()// .findFirst(); Integer val = first.get(); System.out.println(val);//输出10 -
reduce(可以将流中元素反复结合起来,得到一个值)
List<Integer> list = Arrays.asList(10, 5, 7, 3); Integer result = list.stream()// .reduce(2, Integer::sum); System.out.println(result);//输出27,其实相当于2+10+5+7+3,就是一个累加 // 头的总金额=求和(行的产品单价*产品数量) BigDecimal sum = trxOiBill.getLineList().stream().map(item -> item.getPrice().multiply(BigDecimal.valueOf(item.getQuantity()))) .reduce(BigDecimal.ZERO, BigDecimal::add); trxOiBill.setSettleAmount(sum); -
distinct 去重复
//获取待结算单头id列表 List<Long> settleBillHeaderIds = lineRespDTOList.stream().map(SettleApplyLineRespDTO::getSettleBillHeaderId).distinct().collect(Collectors.toList()); -
flatMap 汇总子列表形成stream流(嵌套stream流处理)
settleBillHeaderEntityList.stream().flatMap(head->head.getSettleBillLineList() .stream()).map(SettleBillLineEntity::getItemSettlePrice).reduce(BigDecimal.ZERO,BigDecimal::add); // 看源码注释 * <p>If {@code orders} is a stream of purchase orders, and each purchase * order contains a collection of line items, then the following produces a * stream containing all the line items in all the orders: * <pre>{@code * orders.flatMap(order -> order.getLineItems().stream())... * }</pre> -
sorted,排序,下面的代码片段,取两个字段,按优先级排序
if(tableList!=null&&tableList.size()>0){ tableList= tableList.stream().filter(czPageItemDto -> BigDecimal.ZERO.compareTo(czPageItemDto.getSjhs())!=0||BigDecimal.ZERO.compareTo(czPageItemDto.getYjjhl())!=0) .sorted((a1,a2)->{ int s1 = a2.getSjhs().compareTo(a1.getSjhs()); if(s1!=0){ return s1; }else{ return a2.getYjjhl().compareTo(a1.getYjjhl()); } }) .collect(Collectors.toList()); czPageDto.setTableList(tableList); }
并行操作
- 并行:指的是多个任务在同一时间点发生,并由不同的cpu进行处理,不互相抢占资源
- 并发:指的是多个任务在同一时间点内同时发生了,但由同一个cpu进行处理,互相抢占资源
stream api 的并行操作和串行操作,只有一个方法区别,其他都一样,例如下面我们使用parallelStream来输出空字符串的数量:
List<String> strings = Arrays.asList("abc", "", "bc", "efg", "abcd","", "jkl");
// 采用并行计算方法,获取空字符串的数量
long count = strings.parallelStream().filter(string -> string.isEmpty()).count();
在实际使用的时候,并行操作不一定比串行操作快!对于简单操作,数量非常大,同时服务器是多核的话,建议使用Stream并行!反之,采用串行操作更可靠!
例子代码
声明User类
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User implements Serializable
{
private Long id;
private String name;
private Integer age;
}
import java.util.Arrays;
import java.util.List;
/**
* 按条件筛选用户
* 1.id 为偶数
* 2.年龄大于22
* 3.用户名大写
* 4.用户名倒排序
* 5.输出一个用户
*请你只用一行代码完成 ,如下例子
*/
public class StreamDemo {
public static void main(String[] args) {
User user1 = new User(1L,"a",23);
User user2 = new User(2L,"b",24);
User user3 = new User(3L,"c",22);
User user4 = new User(4L,"d",28);
User user5 = new User(5L,"e",26);
List<User> userList = Arrays.asList(user1,user2,user3,user4,user5);
userList.stream()
.filter(user->{return user.getId() %2 ==0;})
.filter(user->{return user.getAge()>22;})
//.map(user->{return user.getName().toUpperCase();})// 返回大写的用户名的map集合 stream流
.sorted((a1,a2)->{return a2.compareTo(a1);})
//.limit(1)
.forEach(System.out::println);
// 求和
int ageSumThree = userList.stream().map(User::getAge).reduce(0, Integer::sum);
System.out.println("ageSumThree: " + ageSumThree);
int ageSumFour = userList.stream().mapToInt(User::getAge).sum();
System.out.println("ageSumFour: " + ageSumFour);
// 求最大最小值
int min = userList.stream().map(User::getAge).reduce(Integer::min).orElse(0);
System.out.println("min : " + min);
int max = userList.stream().map(User::getAge).reduce(Integer::max).orElse(0);
System.out.println("max : " + max);
// 拼接字符串
String append = userList.stream().map(User::toString).reduce("拼接字符串:", String::concat);
System.out.println("append : " + append);
// 求平均值
double average = userList.stream().mapToInt(User::getAge).average().orElse(0.0);
System.out.println("average : " + average);
}
}
执行结果:
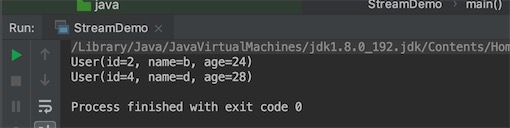
forEach的源码参数是一个消费者函数式接口
void forEach(Consumer<? super T> action);
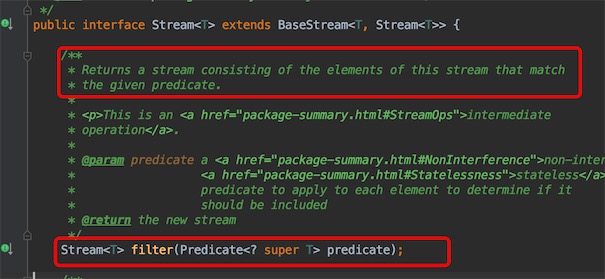
filter的源码参数是一个Predicate函数式接口
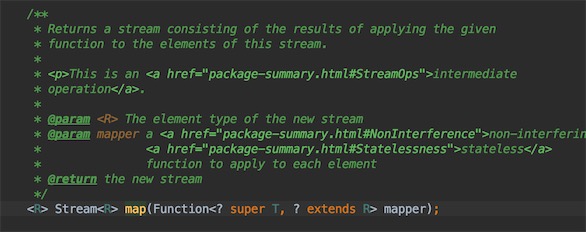
map的源码是一个Function函数式接口
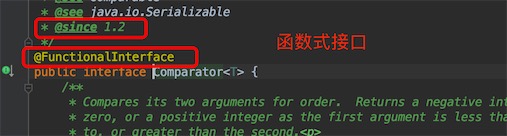
sort的源码
Stream<T> sorted(Comparator<? super T> comparator);
点进Comparator的源码
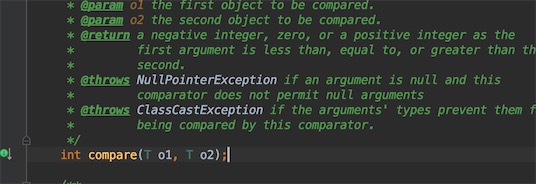
参考代码2
public BasePageResponse<Map<String,Object>> replacePaySalesManageReportCollectList(CcsBusinessAnalysisReportDTO ccsBusinessAnalysisReportDto) {
String[] split = collectKey.split(",");
...
// 请求传参
ccsBusinessAnalysisReportDto.setPageNo(1);
ccsBusinessAnalysisReportDto.setPageSize(1000);
ccsBusinessAnalysisReportDto.setIsReport("Y");
// 代理运营商
ccsBusinessAnalysisReportDto.setOperatorCode(allOperatorCodes.toString());
Map<String, Object> result = new HashMap<>();
String url =cimsReportUrl + "/es/salesmanage/so-customer-sales-detail/matchQuery";
String params = JSONObject.toJSONString(ccsBusinessAnalysisReportDto);
try {
// http请求获取数据
result = cimsMatchQuery(url, params, 0);
if ("0000".equals(result.get("code"))) {
// 总页数
Integer totalPage = Integer.valueOf(result.get("totalPage").toString());
// 第一页数据
JSONArray list = (JSONArray) result.get("rows");
// 其他页数据循环获取
for (int i = 2; i <= totalPage; i++) {
ccsBusinessAnalysisReportDto.setPageNo(i); // 页码
Map<String, Object> result1 = cimsMatchQuery(url, JSONObject.toJSONString(ccsBusinessAnalysisReportDto), 0);
if ("0000".equals(result1.get("code"))) {
list.addAll((JSONArray) result1.get("rows"));
}
}
// 转换类型
List<Map> allList = list.toJavaList(Map.class);
List<Map<String, Object>> collectList = new ArrayList<>();
for (Map<String, Object> map : allList) {
collectList.add(map);
}
//按创建时间由近到远排序
collectList =collectList.stream().sorted((o1, o2) -> {
Date date = simpleDateFormat.parse(o1.get("beginDate").toString());
Date date1 = simpleDateFormat.parse(o2.get("beginDate").toString());
return date.compareTo(date1);
}).collect(Collectors.toList());
// 分组
Map<String, List<Map<String, Object>>> collect1= collectList.stream().collect(Collectors.groupingBy(map -> {
StringBuilder sb = new StringBuilder();
Arrays.stream(split).forEach(s-> sb.append(map.get(s).toString()).append("_"));
return sb.toString(); // 返回分组的key,即XXX_XXX_
}));
List<Map<String,Object>> resultDone =new ArrayList<>();
// 对分组进行聚合计算
collect1.forEach((key,slist)->{
Map<String,Object> map=new HashMap<>();
// 销售数量
BigDecimal itemQtyAll = slist.stream().map(map1 ->map1.get("itemQty")==null?BigDecimal.ZERO:new BigDecimal(map1.get("itemQty").toString())).reduce(BigDecimal.ZERO, BigDecimal::add);
// 销售金额
BigDecimal operationAmountAll = slist.stream().map(map1 ->map1.get("operationAmount")==null?BigDecimal.ZERO:new BigDecimal(map1.get("operationAmount").toString())).reduce(BigDecimal.ZERO, BigDecimal::add);
// 运营费
BigDecimal wholesaleAmountAll = slist.stream().map(map1 ->map1.get("wholesaleAmount")==null?BigDecimal.ZERO:new BigDecimal(map1.get("wholesaleAmount").toString())).reduce(BigDecimal.ZERO, BigDecimal::add);
// 批发空间
BigDecimal itemListAmountAll = slist.stream().map(map1 ->map1.get("itemListAmount")==null?BigDecimal.ZERO:new BigDecimal(map1.get("itemListAmount").toString())).reduce(BigDecimal.ZERO, BigDecimal::add);
map.put("itemQty",itemQtyAll);
map.put("operationAmount",operationAmountAll);
map.put("wholesaleAmount",wholesaleAmountAll);
map.put("itemListAmount",itemListAmountAll);
// 分组的key值也放入map中
Arrays.stream(split).forEach(s->map.put(s,slist.get(0).get(s)));
resultDone.add(map);
});
//按销售金额降序排列
List<Map<String,Object>> resultEnd = resultDone.stream().sorted((o1, o2) -> {
BigDecimal itemListAmount1 = new BigDecimal(o1.get("itemListAmount").toString());
BigDecimal itemListAmount2 = new BigDecimal(o2.get("itemListAmount").toString());
return itemListAmount2.compareTo(itemListAmount1);
}).collect(Collectors.toList());
}
}
}
7. 分支合并forkjoin
工作原理
什么是forkjoin
Fork是执行的意思, Join是等待的意思, 结合使用就是先用Fork来执行子任务, 然后再用Join等待子任务全部执行完毕之后再统一处理或者返回,主要就是两步:
-
任务拆分
-
结果合并
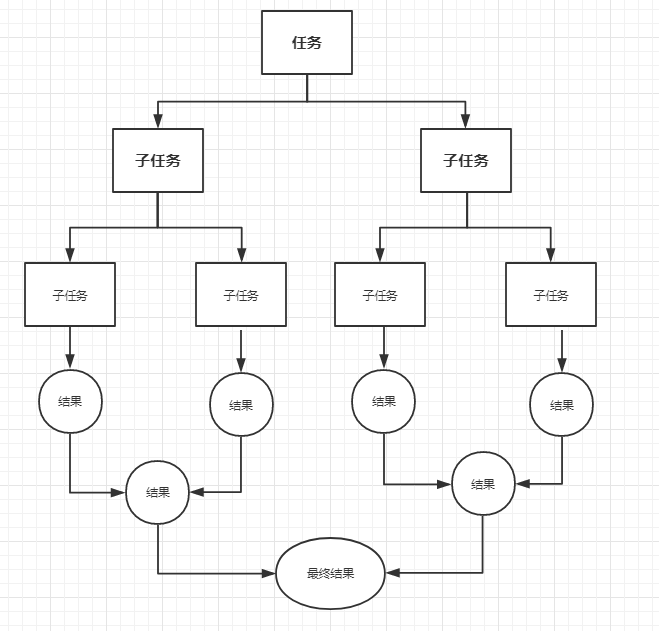
forkjoin一定是用在大数据量的情况下
它的工作原理是通过维护一个双端队列实现子任务的管理
如下图线程A、B分别执行子任务,A慢,B快,B执行完就会窃取线程A的剩余子任务来执行,
- 好处:这样可以提高效率
- 坏处:会产生资源争夺的问题。
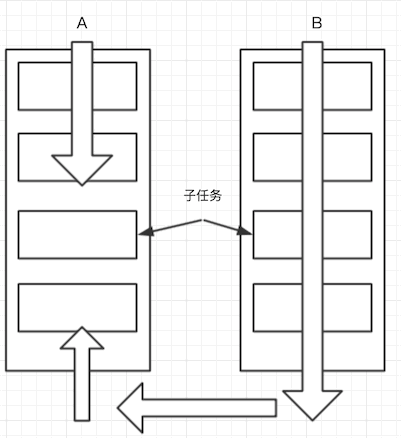
测试一下forkjoin
java中我们通过类java.util.concurrent.ForkJoinPool(一个池子) ,调用它的exeute()方法执行任务,传入参数是ForkJoinTask类的具体调用任务

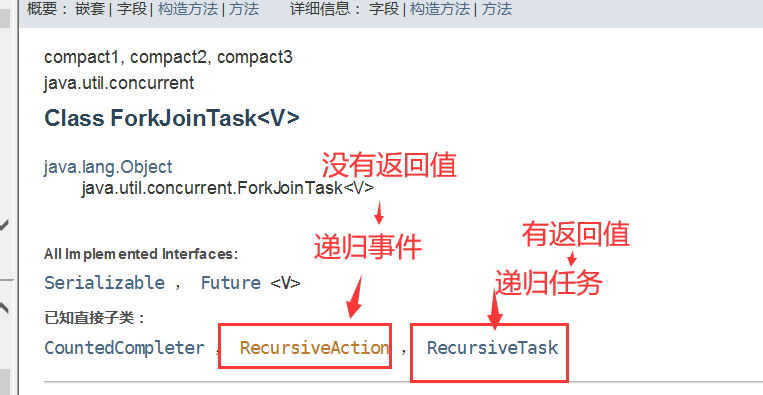
1、ForkJoinWork 任务类
import java.util.concurrent.RecursiveTask;
// 求和,有返回值继承RecursiveTask,没返回值继承RecursiveAction
public class ForkJoinWork extends RecursiveTask<Long> {
private Long start;
private Long end;
private static final Long tempLong = 10000L; //临界值,只要超过这个值forkjoni的效率就更高
public ForkJoinWork(Long start, Long end) {
this.start = start;
this.end = end;
}
// 计算方法
@Override
protected Long compute() {
// 临界值判断
if((end - start) <= tempLong){
Long sum = 0L;
// 普通方法
for (Long i = start; i <= end; i++) {
sum += i;
}
return sum;
}else {
// 第二种方式,拆分两个任务执行
long middle = (end - start)/2;
ForkJoinWork right = new ForkJoinWork(start,middle);
right.fork(); // 压入线程队列
ForkJoinWork left = new ForkJoinWork(middle+1,end);
left.fork(); // 压入线程队列
// 获得结果,join会阻塞等待结果
return right.join() + left.join();
}
}
}
2、编写测试类
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.stream.LongStream;
public class MyTest {
public static void main(String[] args) throws ExecutionException, InterruptedException{
test1(); // times:3186 r=> 500000000500000000
test2(); // times:4262 r=> 500000000500000000
test3(); // times:135 r=> 500000000500000000
}
// 普通的方法 3000块的写法
private static void test1(){
long sum =0l;
long start = System.currentTimeMillis();
// _是分隔符,java是不会识别的,为了更易阅读
for (Long i = 0L; i <= 10_0000_0000L; i++) {
sum += i;
}
long end = System.currentTimeMillis();
System.out.println("普通方法times:" + (end - start) +" r=> "+ sum);
}
// forkjoin 6000块的写法
private static void test2() throws ExecutionException, InterruptedException {
long start = System.currentTimeMillis();
ForkJoinPool forkJoinPool = new ForkJoinPool();
ForkJoinWork forkJoinWork = new ForkJoinWork(0L,10_0000_0000L);
// 运行,并返回值
ForkJoinTask<Long> submit = forkJoinPool.submit(forkJoinWork);
Long sum = submit.get();
long end = System.currentTimeMillis();
System.out.println("forkjoin times:" + (end - start) +" r=> "+ sum);
}
// 并行流计算 9000块的写法
private static void test3(){
long start = System.currentTimeMillis();
// 流计算,parallel 并行计算
Long sum = LongStream.rangeClosed(0L,10_0000_0000L).parallel().reduce(0L,Long::sum);
long end = System.currentTimeMillis();
System.out.println("并行流计算 times:" + (end - start) +" r=> "+ sum);
}
}
执行结果:
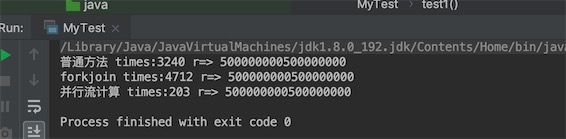
使用forkjoin比普通方法还慢,并行流计算最快,这说明计算数据量还不够大,体现不出优势。
8. 异步回调CompletableFuture
为什么需要异步回调
- 提高cpu的使用率,提高服务器的并发量。
在正常的业务中使用同步线程,如果服务器每处理一个请求,就创建一个线程的话,会对服务器的资源造成浪费。因为这些线程可能会浪费时间在等待网络传输,等待数据库连接等其他事情上,真正处理业务逻辑的时间很短很短,但是其他线程在线程池满了之后又会阻塞,等待前面的线程处理完成。而且,会出现一个奇怪的现象,客户端的请求被阻塞,但是cpu的资源使用却很低,大部分线程都浪费在处理其他事情上了。所以,这就导致服务器并发量不高。
而异步,则可以解决这个问题。
场景
我们可以把需要用到cpu的业务处理使用异步来实现,这样其他请求就不会被阻塞,而且cpu会保持比较高的使用率。我们设想一个情景,A是处理业务的一个步骤,A需要解决一个问题,这时候A可以问B,让B来告诉A答案,这期间,A可以继续做自己的事情,而不用因为B做的事而阻塞。于是,我们想到给B设置一个线程,让B去处理耗时的操作,然后处理完之后把结果告诉A。所以这个问题的要点就在于B处理完之后如何把结果告诉A。我们可以直接在A中写一个方法对B处理完的结果进行处理,然后B处理完之后调用A这个方法。这样A调用B去处理过程,B调用A的C方法去处理结果就叫做回调
没有返回值的异步回调
在juc包,我们使用CompletableFuture做异步回调。
public class CompleteFutureDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 没有返回值,好比多线程,功能更强大!
CompletableFuture<Void> completableFuture = CompletableFuture.runAsync(() -> {
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "没有返回值!");
});
System.out.println("111111");
completableFuture.get();
}
}
执行结果:
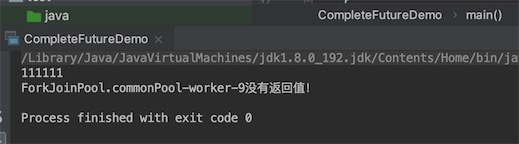
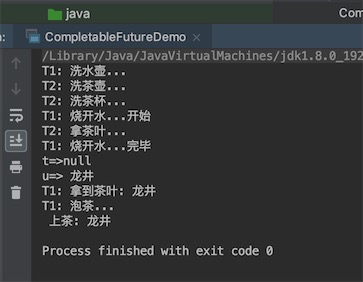
先输出11111,2秒后输出异步线程的名字,说明是异步
带返回值的异步回调
public class CompleteFutureDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
CompletableFuture<Integer> uCompletableFuture = CompletableFuture.supplyAsync(() -> {
System.out.println(Thread.currentThread().getName()+"=>supplyAsync!");
//int i = 10/0;
return 1024;
});
System.out.println(uCompletableFuture.whenComplete((t, u) -> { // 成功失败都会执行
System.out.println("t=>" + t); // 正确结果
System.out.println("u=>" + u); // 错误信息
}).exceptionally(e -> { // 失败,如果错误就返回错误的结果!
System.out.println("e:" + e.getMessage());
return 500; // 错误的结果
}).get());
}
}
点进whenComplete的源码

参数是一个BiConsumer,consumer函数式接口的变体,消费没有返回,点进BiConsumer的接口
点进exceptionally的源码,参数是一个Function函数式接口,一个输入参数一个返回参数
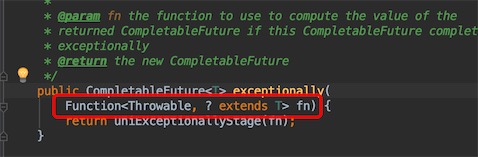
执行结果,发现t就是正确的结果
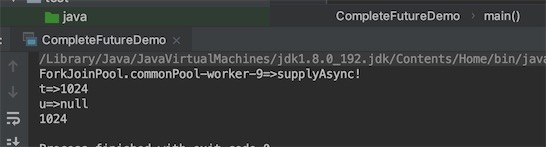
执行int i = 10/0,u就是错误的信息
泡茶的例子代码
public static void main(String[] args) throws ExecutionException, InterruptedException {
// runAsync 没有返回值
// 任务1:洗水壶 -> 烧开水
CompletableFuture<Void> f1 =
CompletableFuture.runAsync(()->{
System.out.println("T1: 洗水壶...");
sleep(1, TimeUnit.SECONDS);
System.out.println("T1: 烧开水...开始");
sleep(15, TimeUnit.SECONDS);
System.out.println("T1: 烧开水...完毕");
});
// supplyAsync 有返回值
// 任务2:洗茶壶 -> 洗茶杯 -> 拿茶叶
CompletableFuture<String> f2 =
CompletableFuture.supplyAsync(()->{
System.out.println("T2: 洗茶壶...");
sleep(1, TimeUnit.SECONDS);
System.out.println("T2: 洗茶杯...");
sleep(2, TimeUnit.SECONDS);
System.out.println("T2: 拿茶叶...");
sleep(1, TimeUnit.SECONDS);
return " 龙井 ";
});
// 任务3:任务1和任务2完成后执行->泡茶
CompletableFuture<String> f3 =
f1.thenCombine(f2, (t, u)->{
System.out.println("T1: 拿到茶叶:" + u); // u就是结合任务f2的返回值
System.out.println("T1: 泡茶...");
return " 上茶:" + u;
});
// 等待任务 3 执行结果
System.out.println(f3.join());
}
private static void sleep(int t, TimeUnit u) {
try {
u.sleep(t);
}catch(InterruptedException e){}
}
}
点进thenCombine 的源码

第一个参数CompletionStage 是一个接口,点进它的源码,CompletableFuture就是它的实现类,所以这里把任务f2传给f1,f1任务完成后结合f2的返回结果
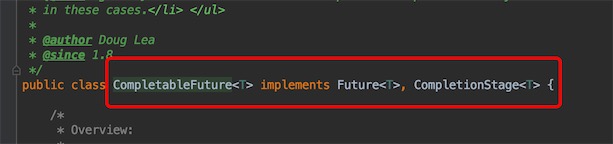
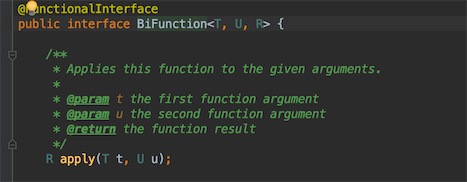
第二个参数BiFuntion是一个Function函数式接口的变体,
参考博客:
多任务异步线程
@Override
public BaseResponse<JSONObject> getQuotation(JSONObject content) {
BaseResponse<JSONObject> response = new BaseResponse<>();
QueryParam queryParam = new QueryParam(); // 传参
queryParam.setP01(content.getString("accountNumber")); // 结算批号
JSONObject data = new JSONObject();
CountDownLatch latch = new CountDownLatch(4);
try {
// 1.查询核销单头信息
CompletableFuture<Map<String,Object>> headFuture = CompletableFuture.supplyAsync(()-> getQuotationHead(queryParam));
headFuture.whenComplete((r,e) ->{
if(Objects.nonNull(r)){
data.putAll(r);
}
latch.countDown();
}).exceptionally(e->{
logger.error("查询核销单头信息错误:" + e.getMessage(), e);
response.setSuccess(false);
data.put("headResponseMsg",e.getMessage());
return null;
});
// 2.查询核销物料行信息
CompletableFuture<Map<String,Object>> lineFuture = CompletableFuture.supplyAsync(() -> listQuotationLine(queryParam));
lineFuture.whenComplete((r,e) -> {
if(Objects.nonNull(r)){
data.putAll(r);
}
latch.countDown();
}).exceptionally(e->{
logger.error("查询核销物料行信息错误:" + e.getMessage(), e);
response.setSuccess(false);
data.put("lineResponseMsg",e.getMessage());
return null;
});
// 3.查询发票列表
CompletableFuture<Map<String,Object>> invoiceFuture = CompletableFuture.supplyAsync(() -> listQuotationInvoice(queryParam));
invoiceFuture.whenComplete((r,e) -> {
if(Objects.nonNull(r)){
data.putAll(r);
}
latch.countDown();
}).exceptionally(e->{
logger.error("查询核销发票错误:" + e.getMessage(), e);
response.setSuccess(false);
data.put("invoiceResponseMsg",e.getMessage());
return null;
});
// 4.查询附件列表
CompletableFuture<Map<String,Object>> appendixFuture = CompletableFuture.supplyAsync(() -> listQuotationAppendix(queryParam));
appendixFuture.whenComplete((r,e) -> {
if(Objects.nonNull(r)){
data.putAll(r);
}
latch.countDown();
}).exceptionally(e->{
logger.error("查询核销附件错误:" + e.getMessage(), e);
response.setSuccess(false);
data.put("appendixResponseMsg",e.getMessage());
return null;
});
latch.await();
} catch (Exception e) {
logger.error("查询核销单详情错误:" + e.getMessage(), e);
response.setSuccess(false);
response.setMsg(ErrorCode.SYSTEM_ERROR.getMessage());
response.setCode(ErrorCode.SYSTEM_ERROR.getCode());
}
response.setData(data);
return response;
}
深入
参考:https://www.cnblogs.com/liujiarui/p/13395424.html
CompletableFuture是JDK8新增的用于异步编程的类,与传统的Future接口相比,它是一个完整的非阻塞编程模型:Future、Promise、Callback。
-
Future的缺点
Futrue在Java里面,通常用来表示一个异步任务的引用,比如我们将任务提交到线程池里面,然后我们会得到一个Futrue,在Future里面有isDone方法来 判断任务是否处理结束,还有get方法可以一直阻塞直到任务结束然后获取结果,但整体来说这种方式,还是同步的,因为需要客户端不断阻塞等待或者不断轮询才能知道任务是否完成。
-
CompletableFuture
能够将回调放到与任务不同的线程中执行,也能将回调作为继续执行的同步函数,在与任务相同的线程中执行。它避免了传统回调最大的问题,那就是能够将控制流分离到不同的事件处理器中。
弥补了Future模式的缺点。在异步的任务完成后,需要用其结果继续操作时,无需等待。可以直接通过thenAccept、thenApply、thenCompose等方式将前面异步处理的结果交给另外一个异步事件处理线程来处理。
1、get阻塞主线程
在主线程里面创建一个CompletableFuture,然后主线程调用get方法会阻塞,最后我们在一个子线程中使其终止。
public class TestCompletableFuture {
public static void main(String[] args) throws Exception{
CompletableFuture<String> completableFuture=new CompletableFuture<String>();
Runnable runnable=new Runnable() {
@Override
public void run() {
try {
TimeUnit.SECONDS.sleep(3);
System.out.println(Thread.currentThread().getName()+" 执行.....");
completableFuture.complete("success");//在子线程中完成主线程completableFuture的完成
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
Thread t1=new Thread(runnable);
t1.start();//启动子线程
String result=completableFuture.get();//主线程阻塞,等待完成
System.out.println(Thread.currentThread().getName()+" 1x: "+result);
}
}
输出结果:
Thread-0 执行.....
main 1x: success
2、thenApply 异步处理结果传给下一个异步线程
public class TestCompletableFuture {
public static void asyncCallback() throws ExecutionException, InterruptedException {
CompletableFuture<String> task=CompletableFuture.supplyAsync(()->{
System.out.println("线程" + Thread.currentThread().getName() + " supplyAsync");
return "123";
});
CompletableFuture<Integer> result1 = task.thenApply(number->{
System.out.println("线程" + Thread.currentThread().getName() + " thenApply1 ");
return Integer.parseInt(number);
});
CompletableFuture<Integer> result2 = result1.thenApply(number->{
System.out.println("线程" + Thread.currentThread().getName() + " thenApply2 ");
return number*2;
});
System.out.println("线程" + Thread.currentThread().getName()+" => "+result2.get());
}
public static void main(String[] args) throws Exception{
asyncCallback();
}
}

CompletableFuture默认使用的线程池是ForkJoinPool
3、thenAccept 接受,相当于消费者函数式接口,只接受不返回
适合用于多个callback函数的最后一步操作使用,看源码,传入的参数就是一个消费者函数式接口

public class TestCompletableFuture {
public static void asyncCallback() throws ExecutionException, InterruptedException {
CompletableFuture<String> task=CompletableFuture.supplyAsync(()->{
System.out.println("线程" + Thread.currentThread().getName() + " supplyAsync");
return "123";
});
CompletableFuture<Integer> chain1 = task.thenApply(number->{
System.out.println("线程" + Thread.currentThread().getName() + " thenApply1 ");
return Integer.parseInt(number);
});
CompletableFuture<Integer> chain2 = chain1.thenApply(number->{
System.out.println("线程" + Thread.currentThread().getName() + " thenApply2 ");
return number*2;
});
CompletableFuture<Void> result = chain2.thenAccept(product -> {
System.out.println("线程" + Thread.currentThread().getName() + "thenAccept=" + product);
});
result.get();
System.out.println("线程" + Thread.currentThread().getName()+" end ");
}
public static void main(String[] args) throws Exception{
asyncCallback();
}
}

4、thenRun 任务的最后步骤
与thenAccept类似,区别是不接受回调函数的返回值,表示任务的最后一个步骤,不接受参数也不返回参数。
public class TestCompletableFuture {
public static void asyncCallback() throws ExecutionException, InterruptedException {
CompletableFuture.supplyAsync(()->{
System.out.println(Thread.currentThread().getName()+" supplyAsync: 一阶段任务");
return null;
}).thenRun(()->{
System.out.println(Thread.currentThread().getName()+" thenRun: 收尾任务");
}).get();
}
public static void main(String[] args) throws Exception {
asyncCallback();
}
}
结果:
ForkJoinPool.commonPool-worker-1 supplyAsync: 一阶段任务
main thenRun: 收尾任务
5、一个主线程多个异步线程任务
每一步都是异步运行的
public class TestCompletableFuture {
public static void asyncCallback() throws ExecutionException, InterruptedException {
CompletableFuture<String> ref1= CompletableFuture.supplyAsync(()->{
try {
System.out.println(Thread.currentThread().getName() + " supplyAsync开始执行任务1.... ");
TimeUnit.SECONDS.sleep(1);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " supplyAsync: 任务1");
return null;
});
CompletableFuture<String> ref2= CompletableFuture.supplyAsync(()->{
try {
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " thenApplyAsync: 任务2");
return null;
});
CompletableFuture<String> ref3=ref2.thenApplyAsync(value->{
System.out.println(Thread.currentThread().getName() +" thenApplyAsync: 任务2的子任务");
return " finish";
});
Thread.sleep(4000);
System.out.println(Thread.currentThread().getName() + ref3.get());
}
public static void main(String[] args) throws Exception{
asyncCallback();
}
}

可以看到ForkJoinPool线程1执行了任务ref1,线程3执行了任务ref2,线程2执行了任务2的子任务,3个任务都是异步执行的。
注意
ForkJoinPool所有的工作线程都是守护模式的,也就是说如果主线程退出,那么整个处理任务都会结束,而不管你当前的任务是否执行完。如果需要主线程等待结束,可采用ExecutorsThreadPool,如下:
// ExecutorService pool = Executors.newFixedThreadPool(5);
ExecutorService pool = new ThreadPoolExecutor(5,5,3,TimeUnit.SECONDS
,new LinkedBlockingDeque<>(3),new ThreadPoolExecutor.AbortPolicy());
final CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
... }, pool);
6、thenCompose 合并两个有依赖关系的CompletableFutures的执行结果
感觉功能上跟thenApply相似
public class TestCompletableFuture {
public static void asyncCompose() throws ExecutionException, InterruptedException {
CompletableFuture<String> future1=CompletableFuture.supplyAsync(new Supplier<String>() {
@Override
public String get() {
return "1";
}
});
CompletableFuture<String>nestedResult = future1.thenCompose(value->
CompletableFuture.supplyAsync(()->{
return value+"2";
}));
System.out.println(nestedResult.get());
}
public static void main(String[] args) throws Exception {
asyncCompose();
}
}
输出结果:12
7、thenCombine 合并两个没有依赖关系的CompletableFutures的执行结果
就像前面泡茶的例子
public class TestCompletableFuture {
public static void asyncCallback() throws ExecutionException, InterruptedException {
CompletableFuture<Double> d1= CompletableFuture.supplyAsync(()->{
return 1d;
});
CompletableFuture<Double> d2= CompletableFuture.supplyAsync(()->{
return 2d;
});
CompletableFuture<Double> result= d1.thenCombine(d2,(number1,number2)->{
return number1+number2;
});
System.out.println(result.get());
}
public static void main(String[] args) throws Exception{
asyncCallback();
}
}

8、allof与anyof合并多个任务的结果
场景1:allof适用于,你有一系列独立的future任务,你想等其所有的任务执行完后做一些事情。举个例子,比如我想下载100个网页,传统的串行,性能肯定不行,这里我们采用异步模式,同时对100个网页进行下载,当所有的任务下载完成之后,我们想判断每个网页是否包含某个关键词。
public static void mutilTaskTest() throws ExecutionException, InterruptedException {
//添加n个任务
CompletableFuture<Double> array[]=new CompletableFuture[3];
for ( int i = 0; i < 3; i++) {
array[i]=CompletableFuture.supplyAsync(()->{
return Math.random();
});
}
//获取结果的方式一
// CompletableFuture.allOf(array).get();
// for(CompletableFuture<Double> cf:array){
// if(cf.get()>0.6){
// System.out.println(cf.get());
// }
// }
//获取结果的方式二,过滤大于指定数字,在收集输出,流水计算
List<Double> rs= Stream.of(array).map(CompletableFuture::join).filter(number->number>0.6).collect(Collectors.toList());
System.out.println(rs);
}
public static void main(String[] args) throws Exception {
mutilTaskTest();
}

注意其中的join方法和get方法类似,仅仅在于在Future不能正常完成的时候抛出一个unchecked的exception,这可以确保它用在Stream的map方法中,直接使用get是没法在map里面运行的。
场景2:anyof意思就是只要在多个future里面有一个返回,整个任务就可以结束,而不需要等到每一个future结束。
public class TestCompletableFuture {
public static void mutilTaskTest() throws ExecutionException, InterruptedException {
CompletableFuture<String> f1 = CompletableFuture.supplyAsync(()->{
try {
TimeUnit.SECONDS.sleep(4);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "wait 4 seconds";
});
CompletableFuture<String> f2 = CompletableFuture.supplyAsync(()->{
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "wait 2 seconds";
});
CompletableFuture<String> f3 = CompletableFuture.supplyAsync(()->{
try {
TimeUnit.SECONDS.sleep(4);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "wait 10 seconds";
});
CompletableFuture<Object> result = CompletableFuture.anyOf(f1, f2, f3);
System.out.println(result.get());
}
public static void main(String[] args) throws Exception {
mutilTaskTest();
}
}

注意由于Anyof返回的是其中任意一个Future所以这里没有明确的返回类型,统一使用Object接受,留给使用端处理。
9、exceptionally异常处理
CompletableFuture的异常结果输出,
public class TestCompletableFuture {
public static void exceptionProcess() throws ExecutionException, InterruptedException {
int age=-1;
CompletableFuture<String> task= CompletableFuture.supplyAsync(()->{
if(age<0){
throw new IllegalArgumentException("性别必须大于0");
}
if(age<18){
return "未成年人";
}
return "成年人";
}).exceptionally(ex->{
System.out.println(ex.getMessage());
return "发生 异常"+ex.getMessage();
});
System.out.println(task.get());
}
public static void main(String[] args) throws Exception {
exceptionProcess();
}
}

方式2:handle 捕捉异常,无论是否发生异常都会执行
点进handle的源码,底层是一个BiFunction,有输入有返回,返回的是CompletableFuture本身任务要返回的类型

修改上面的代码
public class TestCompletableFuture {
public static void exceptionProcess() throws ExecutionException, InterruptedException {
int age=-1;
CompletableFuture<String> task= CompletableFuture.supplyAsync(()->{
if(age<0){
throw new IllegalArgumentException("性别必须大于0");
}
if(age<18){
return "未成年人";
}
return "成年人";
}).handle((res,ex) ->{
System.out.println("执行handle");
if(ex!=null){
System.out.println("发生异常");
return "发生异常"+ex.getMessage();
}
return res;
});
System.out.println(task.get());
}
public static void main(String[] args) throws Exception {
exceptionProcess();
}
}

// 正常执行
int age=10;

方式3:whenComplete 捕捉异常,无论是否发生异常都会执行
前面已经分析过,whenComplete 的源码底层是一个BiConsumer,没有返回
public class TestCompletableFuture {
public static void exceptionProcess() throws ExecutionException, InterruptedException {
int age=-1;
CompletableFuture<String> task= CompletableFuture.supplyAsync(()->{
if(age<0){
throw new IllegalArgumentException("性别必须大于0");
}
if(age<18){
return "未成年人";
}
return "成年人";
}).whenComplete((res,ex)->{
System.out.println("执行complete");
if(ex!=null){
System.out.println("发生异常"+ex);
}else{
System.out.println(res);
}
});
System.out.println(task.get());
}
public static void main(String[] args) throws Exception {
exceptionProcess();
}
}

JDK9 CompletableFuture 类增强的主要内容
(1)支持对异步方法的超时调用
- orTimeout()
- completeOnTimeout()
(2)支持延迟调用
- Executor delayedExecutor(long delay, TimeUnit unit, Executor executor)
- Executor delayedExecutor(long delay, TimeUnit unit)