 弹吉他的兔子
弹吉他的兔子
1、NoSQL
NoSQL的概述
NoSQL(Not Only Sql),分析一下历史,为什么会诞生NoSql,它帮助我们解决什么问题?
1、单机MySql使用
早些年,小型网站很多,他们的访问量也不大,一个数据库完全可以搞定。但随着数据量和访问量的增大,就会产生瓶颈:
- 数据量如果太大,一个机器放不下
- 数据的索引太大,一个机器内存也放不下
- 访问量变大导致一个数据库实例不能够承受
这个时候就需要升级了
在架构中,没有什么是加一层解决不了的。生活很多事情也是如此,如管理。
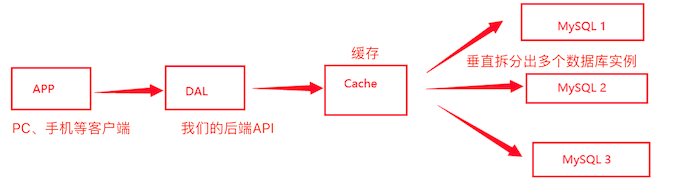
2、Memcache(缓存) + Mysql + 垂直拆分
最初一般先加一层缓存解决,缓存热点数据,缓解数据库的压力,然后下一步优化数据库的结构和索引。使用Memcache成为这个时候最流行的产品
Memcache的优点:
-
简单的key - value 存储
- 内存使用率高
- 多核,多线程
它的缺点:
- 无法容灾
- 无法持久化
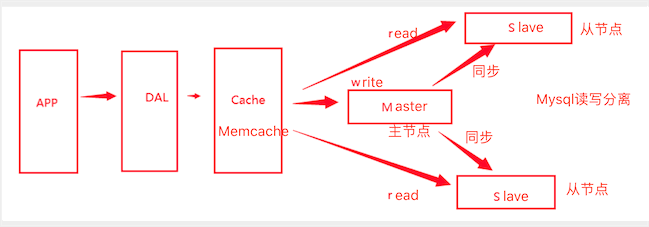
3、主从复制和读写分离
随着访问量更大,我们的数据库的写压力也增加了,Memcache只是解决了读的问题。
我们通过主从复制和读写分离来提高数据库的可读性和可扩展
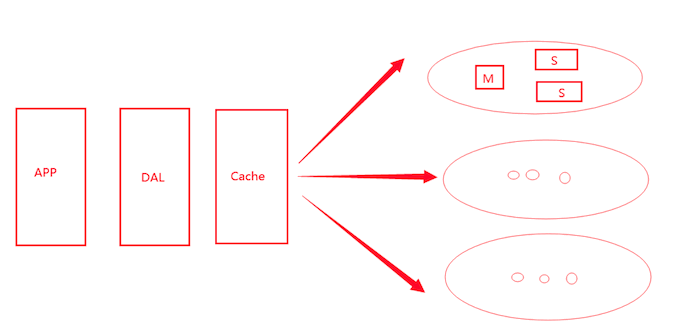
4、分库分表 + 水平拆分 + Mysql集群
我们的数据量持续增大,Mysql的读和写会慢慢出现瓶颈。
-
高并发问题,Mysql最开始的时候使用MyISAM(表锁) ,一个请求就把表给锁了(其实我只是修改一行),高并发的时候,性能低,后来使用InnoDB(行锁)解决。
-
缓存问题,缓存数据量大,需要精简数据,提高热点数据的精度,使用分库分表,是基于业务相关来拆分表的,如下面的
edu
-
user 表
用户信息10个字段
展示3个字段
用户订单相关字段
-
Course 表
-
。。。100个表
-
-
表分区
-
Mysql cluster 集群,高可用
到这里使用集群这个架构,已经完全满足大部分的要求,横向扩展添加机器就行。
5、寻求更加完美的解决方案
Mysql是可以存储大文本的,数据表的压力会十分的大,要恢复数据的时候会特别慢 。假设有1000万条4kb大小的记录,接近40GB,如果能把这些数据从Mysql剔除,我们的Mysql数据库就会变得十分轻巧。
关系性数据库很强大,但是它并不能够很好的适应所有场景。如Mysql的扩展性比较差,大数据量IO压力大,假设1000万的数据要增加一个列,就会十分的困难了,Mysql开发人员就会很痛苦了。
NoSQL(非关系型数据库) 和 MySQL(关系型数据库)今天,我们的应用十分的复杂,集成了很多第三方平台,可以十分轻松的获取数据,如用户的信息、社交网络、地理位置等,这些数据每天都爆增,对这些数据进行操作,SQL关系性数据库就完全无法适应,而非关系型数据库在这上面就显得如鱼得水,如Redis、MongoDB。
最佳实践:NoSQL(非关系型数据库) + MySQL(关系型数据库),综合才是王道!
什么是NoSQL
Not Only Sql,不仅仅是SQL,泛指非关系型数据库
问题:大量的web2.0时代的产品,纯动态网站,海量的多样数据,关系型数据库解决不了
解决:存储的问题,NoSQL数据库的产生就是为了解决大规模数据集合多种多样的情况和挑战。
它的特点
-
易扩展
由于去掉了数据的关系性,扩展就十分方便了
-
大数据量高性能
得益于数据之间没有关系,NoSQL数据库一般都是有很高的读写性能的,如Redis官方记录一秒读11万次,一秒写8万次。
-
数据类型是灵活的
NoSQL不需要给数据设置字段规则,随时可以存储自定义的格式
与关系型数据库的比较
| RDBMS | NoSQL |
|---|---|
| 结构化的数据 | 不仅仅是SQL |
| 结构化的查询语言SQL | 没有声明式的查询语言get set |
| 所有的数据和关系都是存储在单独的表中 | 键值对存储,列存储,文档存储,图形数据库 |
| 预定义的模式 | 没有预定义的模式 |
| 事务支持 | 没有事务 |
| 纵向扩展 | 高可用,高性能,可伸缩,横向扩展 |
| 严格的一致性 | 最终一致性 |
| ACID | CAP定理 |
大数据时代的特征
3V:针对问题的描述
- 海量(Volume [ˈvɑːljuːm]),数据量越来越大
- 多样(Velocity [vəˈlɑːsəti]),各种各样类型的数据出现,类型多样
- 速度(Variety ),数据量增长越来越快,需要处理的速度和响应越来越快
3高:对程序的基本要求
- 高并发
- 高可用
- 高性能
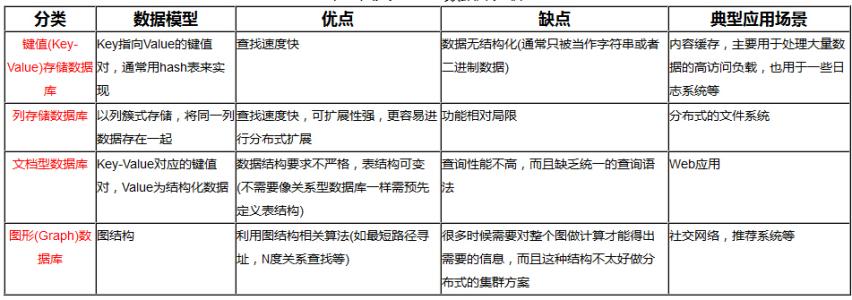
NoSQL的四大分类
1、KV键值对
- 美团: Redis + tair
- 阿里/百度:Redis + Memcache
2、文档型数据库
-
MongoDB
基于分布式文件存储的数据库,C++编写的。它就是介于关系型数据库和非关系型数据库之间的产品,是非关系数据库中最像关系型数据库的产品
-
CouchDb
3、列存储数据库
- HBase + Cassandra
- 分布式文件系统
4、图关系数据库
- Neo4j,InfoGrid
- 拓扑图,社交网络图

对比
理解NoSQL模型
例子:商品购买下订单
1、关系型数据库
ER图
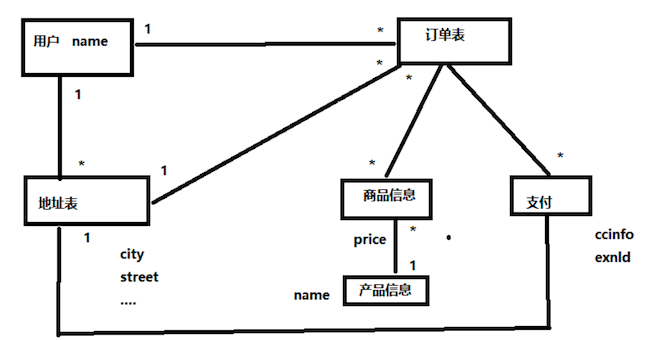
2、非关系型数据库
使用BSON数据类型

2、Redis
Redis( Remote Dictionary Server),即远程字典服务,是一个开源的使用ANSI C语言编写(效率高)、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
是当下最热门的NoSQL数据库之一,数据结构服务器
对比其他key -value缓存产品的特点
- 支持数据的持久化,重启的话,数据不会丢失
- 支持多种数据类型:string,list,set,hash,geo…
- 支持备份,支持主从复制,哨兵模式,集群模式
Redis可以做什么
- 内部存储和持久化
-
支持多种数据类型,满足日常
- 发布、订阅系统
- 地图分析
- 定时器
- 统计打卡
- 优化算法,hyperloglog、bitmap
安装Redis
Windows下安装
windows只支持3.x版本,直接解压后启动服务端redis-server.exe
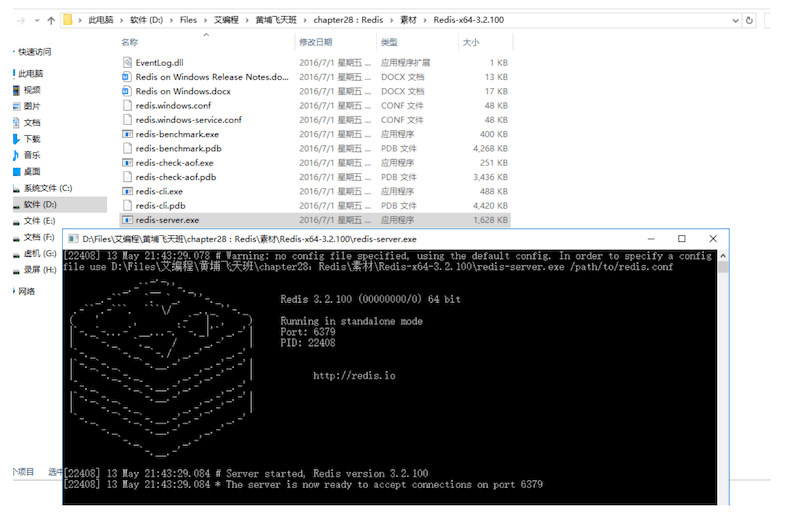
启动客户端redis-cli.exe 连接
Linux下安装
1、上官网https://redis.io/,下载最新版本redis-6.0.1.tar.gz上传到服务器的/opt目录下,解压
2、执行make命令安装
# 安装gcc环境
yum -y install gcc-c++
# redis 6.0版本 需要升级 gcc环境
[root@localhost redis-6.0.1]# yum -y install centos-release-scl
[root@localhost redis-6.0.1]# yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
[root@localhost redis-6.0.1]# scl enable devtoolset-9 bash
[root@localhost redis-6.0.1]# echo "source /opt/rh/devtoolset-9/enable" >> /etc/profile
[root@localhost redis-6.0.1]# make
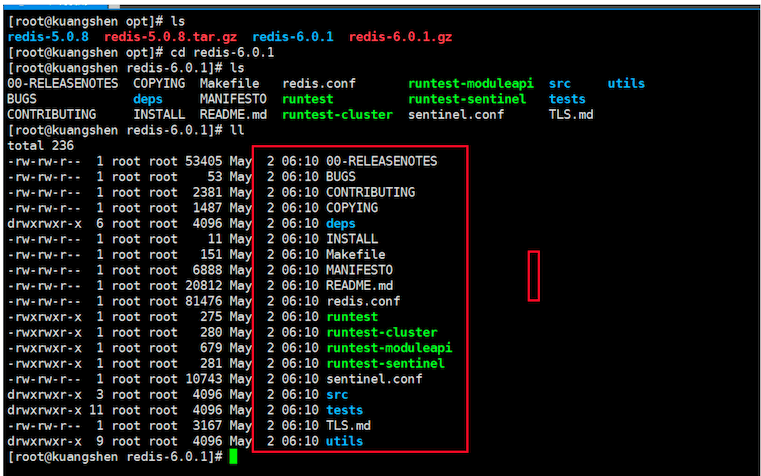
3、再次执行make install
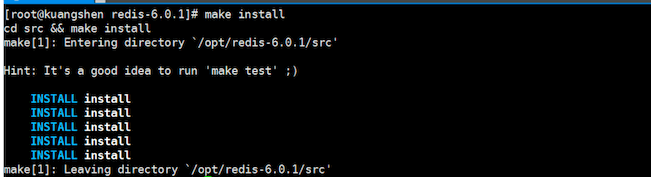
4、安装成功后,redis的相关命令放在redis-6.0.1/src目录下,同时也会放在 /usr/local/bin目录下,如下图:
5、启动redis服务
#1.在/usr/local下创建redis目录
mkdir /usr/local/redis
#2.复制redis.conf文件,以redis的端口号命名
cd redis-6.0.1
cp redis.conf /usr/local/redis/6379.conf
#3.修改配置文件,更多配置参数看文档注释
vi redis.conf
daemonize yes #后台运行
bind 0.0.0.0 #不限制ip访问
requirepass icoding #配置密码
dir /usr/local/redis/working #工作目录,rdb备份的数据保存目录
#4.指定配置文件启动redis
redis-server /usr/local/redis/6379.conf
# 不指定配置文件启动
redis-server
# 进入客户端
# /usr/local/bin下就有reds-server和reds-cli脚本,可以直接执行命令
redis-cli -p 6379 # 指定端口连接redis
redis-cli --help
redis-cli -h 10.12.13.1 -p 6379 -u jacob -a # 连接远程redis的客户端
6、停止redis服务
# 查看6379端口,是否redis已启动
lsof -i tcp:6379
# 查看redis进程
ps -ef|grep redis
ps aux|grep redis
# 正常停止redis服务
redis-cli shutdown # 默认端口6379
redis-cli -p 8080 shutdown # 指定端口关闭服务
# 远程关闭redis 服务器
redis-cli -h xxx.xxx.xxx.xxx -p xxxx -u xxxx -a xxxx shutdown
# 杀死进程的方式停止redis服务,PID通过前面ps命令查看进程ID
kill -9 PID
7、卸载redis服务
停止redis服务后,
- 删除/usr/local/lib目录下与redis 相关的命令
- 删除redis 解压后的目录 redis-6.0.1 即可
Mac下安装
# 解压
tar zxvf redis-4.0.9.tar.gz
# 移动
mv redis-4.0.9 /usr/local/
cd /usr/local/redis-4.0.9
# 编译测试
sudo make test
# 编译安装
sudo make install
注意,如果redis-server启动redis遇到没权限,提示permission denied,要修改redis文件夹的权限,脚步如下:
# 修改redis文件夹的属主、属组、其它用户的rwx 读写执行权限,全部放开
sudo chmod -R 777 文件目录
# 然后需要输入当前用户(要有管理员权限)的密码,就可以了,如下:
xjwdeMacBook:local xjw$ ls -l redis-4.0.13/
total 0
drwxrwxrwx@ 3 xjw staff 96 6 18 21:55 tests
启动成功
压力测试
redis-benchmark redis自带的压力测试工具
模拟高并发情况测试redis性能
redis 性能测试工具可选参数如下所示:
| 序号 | 选项 | 描述 | 默认值 |
|---|---|---|---|
| 1 | -h | 指定服务器主机名 | 127.0.0.1 |
| 2 | -p | 指定服务器端口 | 6379 |
| 3 | -s | 指定服务器 socket | |
| 4 | -c | 指定并发连接数 | 50 |
| 5 | -n | 指定请求数 | 10000 |
| 6 | -d | 以字节的形式指定 SET/GET 值的数据大小 | 2 |
| 7 | -k | 1=keep alive 0=reconnect | 1 |
| 8 | -r | SET/GET/INCR 使用随机 key, SADD 使用随机值 | |
| 9 | -P | 通过管道传输 |
1 |
| 10 | -q | 强制退出 redis。仅显示 query/sec 值 | |
| 11 | –csv | 以 CSV 格式输出 | |
| 12 | -l | 生成循环,永久执行测试 | |
| 13 | -t | 仅运行以逗号分隔的测试命令列表。 | |
| 14 | -I | Idle 模式。仅打开 N 个 idle 连接并等待。 |
# 测试一:100个并发连接数,100000个请求
[root@iZwz996g0 redis-6379]# redis-benchmark -h localhost -p 6379 -c 100 -n 100000
# 测试结果
====== SET ======
100000 requests completed in 1.69 seconds # 100000个请求完成的时间
100 parallel clients
3 bytes payload # 每次写入 3个字节的数据
keep alive: 1 # 保持一个连接
75.86% <= 1 milliseconds
98.64% <= 2 milliseconds
99.82% <= 3 milliseconds
99.90% <= 7 milliseconds
99.92% <= 8 milliseconds
99.96% <= 9 milliseconds
99.98% <= 10 milliseconds
100.00% <= 10 milliseconds
59206.63 requests per second # 每秒处理的请求次数
默认16个数据库
redis.conf配置文件默认配置了数据库有16个,下标从0开始
database 16
# 在默认数据库set值
127.0.0.1:6379> set db0 testdb0
OK
127.0.0.1:6379> select 7 # 切换数据库
127.0.0.1:6379> get db0
(nil)
127.0.0.1:6379> DBSIZE # 查看当前数据库有多少数据
(integer) 0
127.0.0.1:6379> select 0
127.0.0.1:6379> flushdb # 清空当前数据库 谨慎使用
127.0.0.1:6379> flushall # 清空全部数据库 16个都清空
pipeline管道
Redis 性能瓶颈主要是网络,主要原因是 Redis 执行命令的时间通常在微妙级别的,而传输网络是毫秒级别的,慢1000倍。
Linux系统底层通过socket是如何通信的,看下图
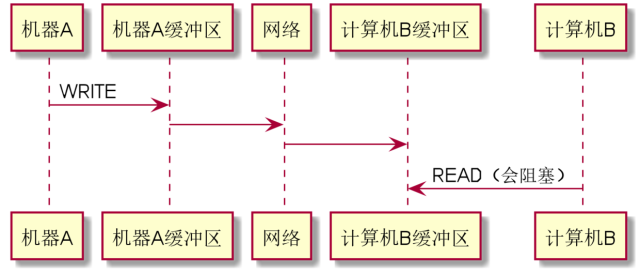
计算机A与计算机B的通信过程是这样的:
1、计算机A将要发送的数据写到自己的发送缓冲区里面SendBuffer,Linux操作系统内核会自己把这部分数据,按照设定的协议,通过网关,把数据发送到复杂地计算机网络中。
2、计算机B的内核会接收到这部分信息,并且会把数据拷贝到接受缓冲区RecvBuffer,然后B机器的进程过来Read就能获取到数据,
3、这里就存在这样一种情况,如果Read的时候数据还没有到B机器或者还没拷贝到缓冲区,那么就会阻塞。很明显,如果我们在一次业务查询中有多次请求,那么,我们希望服务器只要从缓冲区里面读取一次数据,那么就能节省一定量的时间,这是一方面。
从另一方面进行考虑,假如我们在一个业务请求中,需要从Redis上获取3个不同的数据,如果我们一次一次的获取,那会怎么样?时间都浪费在了等待网络传输上,正常情况下,我们执行一条 Redis 命令流程要经过如下几个步骤:
- 客户端发送 Redis 命令,阻塞等待 Redis 应答
- Redis 接收到命令,执行命令
- 应答,客户端收到响应信息
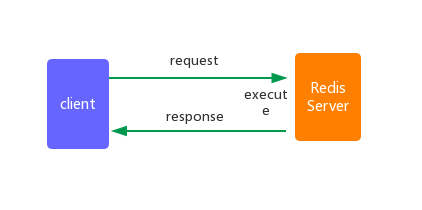
其中 1 、3 称之为一次 RTT(Round Trip Time)
看下图
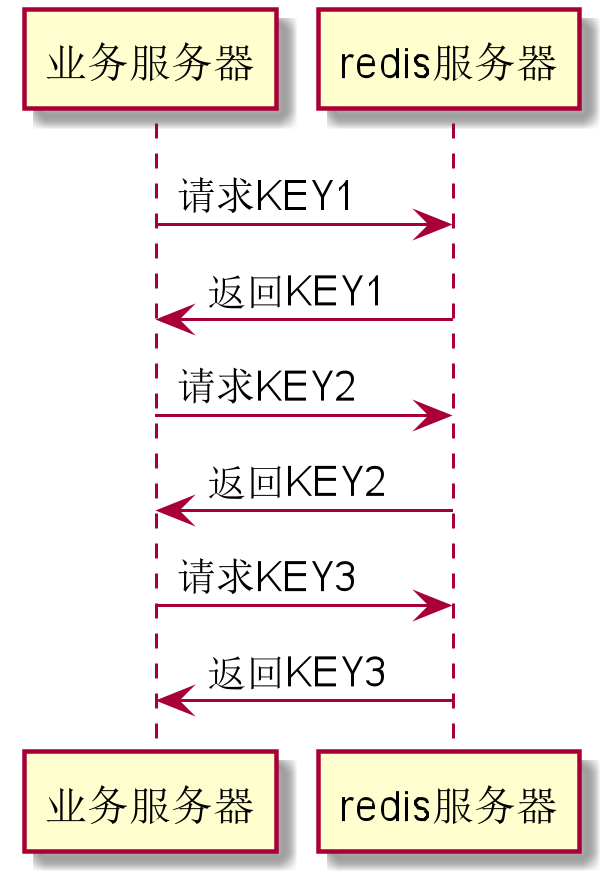
上面的redis请求有两个缺陷:
- 每次查询,都有网络上的延迟。特别是如果Redis跟系统服务不在同一个机房,单趟来回可能要10ms,多了两趟来回,就要多20ms。
- 对于一个请求,里面需要处理20ms,对于整个请求来说,可能延迟就不止增加20ms了,毕竟服务器是多线程的,可能中途又被Linux操作系统切出去干其他事情,整个系统的并发跟吞吐立马就降下来了
解决方案
如果我们能够把三次请求合并成一次丢给服务器,服务器再一次性返回给我们,这不就解决问题了么?这便是Redis的管道!它允许客户端一次性发送多条命令,减少 RTT (Round Trip Time)和 IO 的调用次数(IO 调用涉及到用户态到内核态之间的切换)
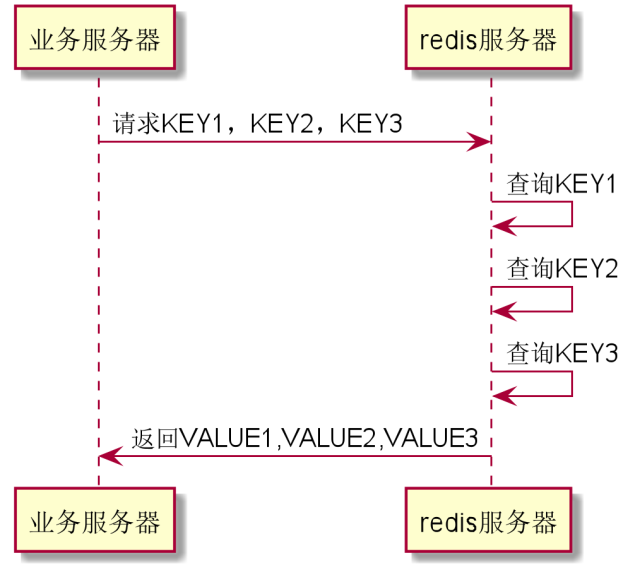
对于Redis来说,还是需要进行3次子查询,但是对于整个系统来说,网络通信的次数只有2次,并发自然就上去了,吞吐自然也上去了。
redis的压力测试工具redis-benchmark 有个-P参数,就是通过管道的方式发送请求,默认管道数是1,我们测试一下增加管道数后看redis的性能有多大的提高
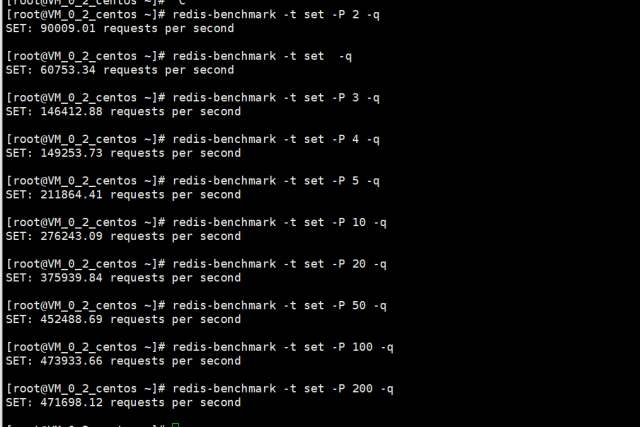
发现随着管道数的增加,每秒的并发量就提高上去了,但是管道数达到100后,并发量基本上就稳定不上升了,个人觉得是跟机器底层的缓存区有关,应该是饱和了,所以并发量已达到最大化。
总结:pipeline就是把发送给redis服务器的多个请求合并成一个请求发送,减少RTT和IO的调用次数,从而提升性能
与批量命令的比较
-
pipeline 可以一次性发送多个不同的命令,例如 set、get、而批量这是一次一个命令,只不过这一次对应的是多个 key 而已。
-
pipeline 只是将多个命令一起发出去而已,不保证这些命令的执行是原子性,
而批量提交则是原子性的,他需要保证整个操作的正确性,避免中途出错而导致最后产生的数据不一致。
与单个命令的性能比较测试
客户端使用jedis
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1",6379);
// 1、管道
Pipeline pipeline = jedis.pipelined();
long pipelineBegin = System.currentTimeMillis();
for(int i = 0; i < 100000; i++){
pipeline.set("pipeline:test_"+i,i + "");
}
//获取所有的 response
pipeline.sync();
long pipelineEnd = System.currentTimeMillis();
System.out.println("the pipeline is :"+ (pipelineEnd - pipelineBegin));
// 2、单个命令
long start = System.currentTimeMillis();
for(int i = 0; i < 100000; i++) {
jedis.set("jedis:test_"+i,i + "");
}
long end = System.currentTimeMillis();
System.out.println("the jedis is:"+ (end - start));
}
运行结果:
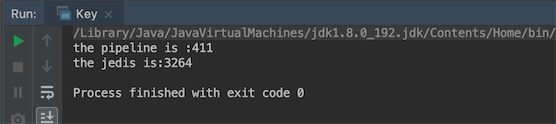
发现使用管道后,比普通方式性能提升了8倍。
客户端使用redisTemplate
@Test
void testPipeline(){
// 1.管道
long pipelineBegin = System.currentTimeMillis();
redisTemplate.executePipelined(new SessionCallback<String>() {
@Override
public <K, V> String execute(RedisOperations<K, V> redisOperations) throws DataAccessException {
for (int i = 0; i < 100000; i++) {
redisTemplate.opsForValue().set("pipeline:test_"+i,i + "");
}
return null;
}
});
long pipelineEnd = System.currentTimeMillis();
System.out.println("the pipeline is :"+ (pipelineEnd - pipelineBegin));
// 2、单个命令
long start = System.currentTimeMillis();
for (int i = 0; i < 100000 ; i++) {
redisTemplate.opsForValue().set("template:test_"+i,i + "");
}
long end = System.currentTimeMillis();
System.out.println("the jedis is:"+ (end - start));
}
运行结果
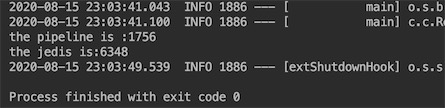
@Test
void testPipeline(){
// 1.管道
long pipelineBegin = System.currentTimeMillis();
List<Object> objects = redisTemplate.executePipelined(new RedisCallback<Object>() {
@Override
public Object doInRedis(RedisConnection redisConnection) throws DataAccessException {
redisConnection.openPipeline();
for (int i = 0; i < 100000; i++) {
String key = "pipeline:test_" + i;
redisConnection.set(key.getBytes(), String.valueOf(i).getBytes());
}
return null;
}
});
long pipelineEnd = System.currentTimeMillis();
System.out.println("the pipeline is :"+ (pipelineEnd - pipelineBegin));
// 2、单个命令
long start = System.currentTimeMillis();
for (int i = 0; i < 100000 ; i++) {
redisTemplate.opsForValue().set("template:test_"+i,i + "");
}
long end = System.currentTimeMillis();
System.out.println("the jedis is:"+ (end - start));
}
运行结果

在这里需要注意4点内容:
- 这里的connect是redis原生链接,所以connection的返回结果是基本上是byte数组,如果需要存储的数据,需要对byte[]数组反序列化。
- 在doInRedis中返回值必须返回为null,为什么返回为空?可以定位到内部代码去查看详情,这里不再赘
- connection.openPipeline()可以调用,也可以不调用,但是connection.closePipeline()不能调用,调用了拿不到返回值。因为调用的时候会直接将结果返回,同时也不会对代码进行反序列化。
- 反序列化需要传入反序列化对象,这些对象都可以进行相应的实例化。
根据你的项目需求选择合适的反序列化对象。比如我在项目中key使用的是StringRedisSerializer,而值通常使用的是GenerJackson2JsonRedisSerializer。所以在初始化redisTemplate的时候会这样做,代码如下,将序列化的实例化对象放入redisTemplate中,当使用的时候就可以直接redis.getKeySerializer()或者redis.getValueSerializer(),这样就不用在实例化一个对象,造成浪费和冗余。
public class MyRedisUtil {
private RedisTemplate redisTemplate;
@Autowired
public void setRedisTemplate(RedisTemplate redisTemplate) {
RedisSerializer keySerializer = new StringRedisSerializer();
RedisSerializer valueSerializer = new GenericJackson2JsonRedisSerializer();
redisTemplate.setKeySerializer(keySerializer);
redisTemplate.setValueSerializer(valueSerializer);
this.redisTemplate = redisTemplate;
}
public RedisTemplate getRedisTemplate() {
return redisTemplate;
}
}
通过这样的掉用方式,我们就可以不用进行强制转换,直接获得我们想要的对象了。
List<User> List = redisTemplate.executePipelined(new RedisCallback<User>() {
@Nullable
@Override
public User doInRedis(RedisConnection connection) throws DataAccessException {
connection.openPipeline();
for (int i = 0; i < 1000000; i++) {
String key = "123" + i;
connection.zCount(key.getBytes(), 0,Integer.MAX_VALUE);
}
return null;
}
}, myRedisComponent.getRedisTemplate().getValueSerializer());
参考博客:
https://blog.csdn.net/chenssy/article/details/104708045/
https://www.cnblogs.com/dobal/p/12039835.html
3、8大数据类型
Redis key 命令
# 进入客户端
redis-cli -p 6379
# 设置 key 的值,没有就创建,有则覆盖
127.0.0.1:6379>set key value
127.0.0.1:6379>get key
#1 查看所有的key,不要在线上使用,有可能导致服务器崩溃
127.0.0.1:6379> key *
#模糊查询key
127.0.0.1:6379> keys abc*
#2 判断一个key是否存在
127.0.0.1:6379> exists name
(integer) 1
#3 当前key移到其他库
127.0.0.1:6379> move name 1
#4 epxire 以秒为单位给这个key设置过期时间,秒杀场景:60秒可能存在大量的请求,缓存
127.0.0.1:6379> set name jude
127.0.0.1:6379> expire name 10
#5 time to live 以秒为单位返回剩余生存时间
127.0.0.1:6379> ttl name
(integer) 9
#6 查看当前key的类型
127.0.0.1:6379> type name
String
# 删除当前数据库的数据,原子性命令,一旦执行就无法回头
127.0.0.1:6379> flushdb
# 危险命令,删除所有数据库的数据,可以在配置文件中把命令改名字
127.0.0.1:6379> flushall
# 重要命令,获取配置信息
127.0.0.1:6379> config
通过中文官方文档学习客户端指令 https://www.redis.net.cn/
Redis dump命令
Redis DUMP 命令用于序列化给定 key ,并返回被序列化的值(字节数组)。
- 客户端(业务应用)将key和java对象序列化成字节数组进行网络传输
- redis服务端接受到写网络请求,将key反序列化在全局hash桶通过hash算法找出存储的位置,保存序列化后的java对象
- redis服务端接受到读网络请求,将key反序列化在全局hash桶(数组)通过hash算法找出存储的位置,如果发生hash冲突,则比较同一个hash值的桶元素(链表)的每个key值,查找出key对应的value,这时value是一个序列化后的java对象,对应redis支持的8种数据结构(规则),然后将java对象的字节数组按存储指定的数据结构规则进行反序列化,得到原对象。redis内部将这个反序列化得到的原对象结果返回,我们通过redis-cli -p 6379进入客户端执行命令得到的结果就是经过反序列化得到的。但是需要经过网络传输给到客户端(业务应用),则又要将反序列化得到的java对象进行序列化转为字节数组。
- 客户端(业务应用)得到redis响应网络请求,将字节数组按指定的数据结构(规则)进行反序列化的得到java对象。
dump命令的出现,就是避免了redis服务端的反序列化操作,从而降低redis服务器的cpu资源占用,直接将内存中存储的value值(序列化对象)通过网络传输返回,也减少了整个网络请求的等待时间
redis 127.0.0.1:6379> DUMP KEY_NAME
# 如果 key 不存在,那么返回 nil 。 否则,返回序列化之后的值。
redis> SET greeting "hello, dumping world!"
OK
# 返回序列化后的值
redis> DUMP greeting
"\x00\x15hello, dumping world!\x06\x00E\xa0Z\x82\xd8r\xc1\xde"
redis> DUMP not-exists-key
(nil)
String(字符串)
这是Redis中最基本的级别,一个key对应一个value,字符串value最大不要超过512M
单值单value
#=====================
# set get del keys exists append strlen
#=====================
# 1、是否存在key
127.0.0.1:6379> exists key1
(integer) 0
# 2、对key内容追加,如果没有值等同于set key
127.0.0.1:6379> append key1 "hello"
127.0.0.1:6379> append key1 " world"
127.0.0.1:6379> get key1
hello wolrd
# 3、获取字符长度
127.0.0.1:6379> strlen key1
(integer) 11
# 4、删除某key
127.0.0.1:6379> del key1
#=====================
# incr decr incrby decrby
#=====================
127.0.0.1:6379> set views 0
# 5、每个人浏览就 +1
127.0.0.1:6379> incr views
127.0.0.1:6379> get views
1
127.0.0.1:6379> incr views
127.0.0.1:6379> get views
2
# 6、浏览量 -1
127.0.0.1:6379> decr views
127.0.0.1:6379> get views
1
# 7、设置增量
127.0.0.1:6379> incrby views 10
127.0.0.1:6379> get views
11
# 8、设置减量
127.0.0.1:6379> decrby views 5
(integer) 6
#=====================
# range [范围]
# getrange setrange
#=====================
127.0.0.1:6379> set key1 abcdefg123456
# 9、范围获取全部字符串
127.0.0.1:6379> getrange key1 0 -1
"abcdefg123456"
# 获取[0,1,2]
127.0.0.1:6379> getrange key1 0 2
"abc"
# 10、替换指定字符串
127.0.0.1:6379> setrange key1 1 xx
127.0.0.1:6379> get key1
"axxdefg123456"
#=====================
# setex(expire) setnx(not exist)
#=====================
# 11、设置60秒过期
127.0.0.1:6379> setex key3 60 expire
127.0.0.1:6379> ttl key3
(integer)56
# 12、如果不存在就设置值,成功返回1,失败返回0
# 可以理解为信号量,原来我们是版本号
127.0.0.1:6379> setnx key4 "redis"
(integer) 1
127.0.0.1:6379> setnx key4 "mongodb"
(integer) 0
#=====================
# 批量机制
# mset mget msetnx
#=====================
# 13、批量设置键值对,
127.0.0.1:6379> mset k10 v10 k11 v11 k12 v12
# 14、批量获取键值对
127.0.0.1:6379> mget k10 k11 k12
"v10"
"v11"
"v12"
# 15、如果不存在就设置值批量操作,msetnx是一个原子性的操作,要么同时成功,要同时失败
127.0.0.1:6379> msetnx k10 10 k13 v13
(integer) 0 # 设置失败
# 例子 缓存对象,获取对象,省去解析的过程,其实使用hash的方式更方便
127.0.0.1:6379> mset user:1:name zhangsan user:1:age 2
127.0.0.1:6379> mget user:1:name user:1:age
"zhangesan"
2
#=====================
# 16、getset 先get返回值,然后再set值
#=====================
127.0.0.1:6379> getset db mongodb
(nil)
127.0.0.1:6379> getset db redis
"mongodb"
127.0.0.1:6379> get db
"redis"