 弹吉他的兔子
弹吉他的兔子
1、Redis持久化
Redis是一个非关系型内存数据库,断电即失,文件存储!持久化是一个刚需!
RDB
什么是rdb
Redis database,在指定的时间间隔将数据集写入磁盘,redis.conf配置文件
# rdb 持就化配置
save 900 1 # 900秒内,只要发生一次变化,就会触发一次 rdb操作(bgsave)
save 300 10 # 300秒内,只要发生10次变化,就会触发一次 rdb操作
save 60 10000 # 60秒内,只要发生10000次变化,就会触发一次 rdb操作
# 生成一个文件
dbfilename dump.rdb # 默认的文件名
redis启动的时候,就会加载这个rdb文件(恢复数据的过程)
Rdb是整合内存的压缩过的快照信息,具体原理:
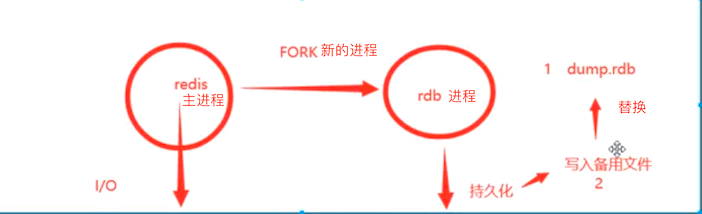
1、fork一个子进程持久化
2、备份和替换
缺陷:可能会丢失最后一次同步的数据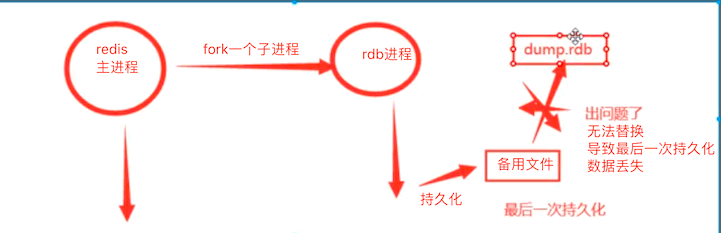
手动触发Rdb
# 1、配置文件save定义的触发规则生效,产生dump.rdb 【被动】
# 2、save命令,执行的时候会阻塞Redis的服务,直到RDB文件完成才会释放我们Redis进程恢复读写操作【主动】
# 3、bgsave命令,执行的时候会在后台fork一个进程进行RDB的生成,不影响主进程的业务操作【主动】
返回最近一次 Redis 成功将数据保存到磁盘上的时间
127.0.0.1:6379> lastsave
(integer) 1589718280
4、flushall 命令触发rdb操作(flushdb不会触发)
127.0.0.1:6379> flushall # 清空所有数据库的数据,会再产生一个空的dump.db,但是没有什么意义
5、退出redis也会触发rdb操作
127.0.0.1:6379> shutdown
恢复的规则
启动的时候,会自动加载当前目录下的dump.rdb文件,恢复数据
具体放置的目录
127.0.0.1:6379> config get dir
"dir"
"/usr/local/bin"
分析
1、大规模的数据恢复,合适
2、对数据完整性和一致性的要求不高的情况下
3、按照save配置定时做备份,redis意外down掉,最后一次的快照数据就有可能丢失
4、采用fork子进程的方式备份数据,内存中的数据被克隆了一份,所以说空间可能会占有较大
AOF
Append Only File,我们每一个步骤,它都会记录下来(读取的命令是不会记录),不断的在这个文件进行追加内容。
恢复的时候,就按照这个文件中记录的指令一个一个的读取(执行一遍)
# 配置 aof 开启
appendonly yes
# aof的文件名
appendfilename "appendonly.aof"
重启redis的时候,它会读取这个文件,假设redis启动失败,可能原因:文件错误
我们可以通过 redis-check-aof来修改文件
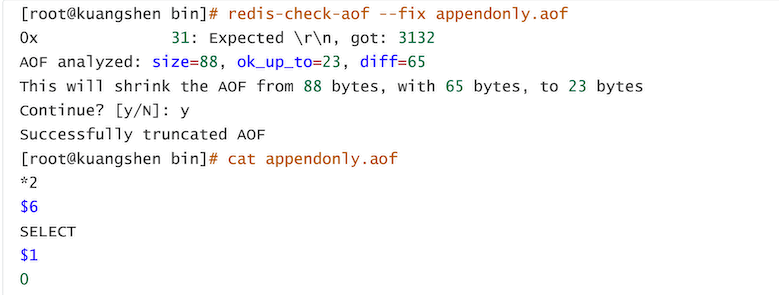
其他配置规则
# redis.conf,redis官方写入 8万次/秒
appendfsync always # 每次写入都执行同步,相对效率低
appendfsync everysec # 每秒执行一次sync,问题:可能会导致这1s丢失
appendfsync no # 不执行同步,redis直接持久化到磁盘
no-appendfsync-on-rewrite no # 重写时是否执行同步,yes不执行同步,no 执行同步,默认no,保证数据的安全
什么时候会触发重写,下面两个配置
# 重写机制(压缩机制):避免文件越来越大,将key的重复值合并(同一个key只保留最后一次写操作),重写的时候会触发fork一个新进程来操作,与RDB的fork进程区别是前者复制写操作,后者复制数据本身
# 重写触发条件就是下面两个都满足才触发
# 上面配置no,重写触发后会fork进程并阻塞主进程无法写入导致等待,所以两个值可以设置小点让重写快速阻塞完毕
# 1.现有的文件比上次多出100%:上次压缩完2G,现在已经4G了如果是50%就是3G
auto-aof-rewrite-percentage 100
# 2.现有的文件已经超过100mb了,避免设置过小,频繁触发重写,也不能过大,避免重写的时候阻塞时间过长
auto-aof-rewrite-min-size 100mb
# 上面配置:aof文件大于100mb 且 比上次比较多出100%,才会触发aof文件的重写
分析
1、相同的数据,aof文件远远大于rdb的文件,恢复速度也是比较慢的
2、每秒执行一次sync同步,问题:可能导致这1秒丢失
3、aof运行的效率慢于rdb,但是同步策略比rdb好一点(每秒同步,数据更完整)
如果不同步(上面的配置appendfsync no),性能是一样的。
总结
1、RDB持久化,save配置可以进行指定时间间隔来进行持久化存储
2、AOF持久化,记录每一次的命令,读取的时候一行行读取恢复。由于有重写机制,可以保证这个文件不会太大
3、如果你是使用Redis只做缓存,可以选择不做持久化
4、同时开启了两种持久化方式:
- redis启动的时候有优先加载aof文件,先恢复原始数据,通常情况下aof文件保存的数据集一定比rdb文件完整,rdb是定期备份的。
- 推荐不要只使用aof,因为如果aof文件损坏,可能数据就没了(redis启动不了),这时rdb就显得特别重要了
5、性能
-
Rdb 用做后备使用,一般在slave 从节点配置,我们也不需要改动原来默认的配置,保留 15分钟备份一次即可。(我们使用redis的模式: 主从复制 + 哨兵模式)
save 900 1 # save 300 10 # save 60 10000 -
如果你开启了AOF,最多的数据丢失不会超过2秒,启动时也只是加载了aof文件(单机你就开启aof吧),auto-aof-rewrite-min-size 一般设置 几个G都是ok的
-
默认不开启AOF,我们可以使用主从来实现高可用,好处就是减少IO资源,减少了重写的空间浪费。假设 主从节点都出现了问题,也就是丢失了15分钟的数据,启动的时候查看哪个一个从节点的rdb更加完整来进行选择加载,微博就是这样做的。
所以说:Redis的持久化是默认不开启AOF的,是使用RDB来处理持久化!
2、Redis事务
事务本质
Redis的事务本质是一组命令的集合,可以一次性支持多个指令。串行执行,从上到下依次执行。
Redis事务没有隔离性的概念。为什么?
因为所有的命令在事务真正执行之前都是没有操作,在队列缓存中。
Redis的事务流程:
# 开启一个事务
# 一堆指令
# 执行事务
multi # 标记事务的开始
exec # 执行事务,结束
discard # 放弃事务,取消这个事务
正常执行

放弃事务
127.0.0.1:6379> multi # 开始事务
127.0.0.1:6379> set k1 v1
127.0.0.1:6379> set k2 v2
127.0.0.1:6379> set k4 v4
127.0.0.1:6379> discard # 放弃事务,队列就没了
127.0.0.1:6379> get k4
(nil)
Redis不保证原子性
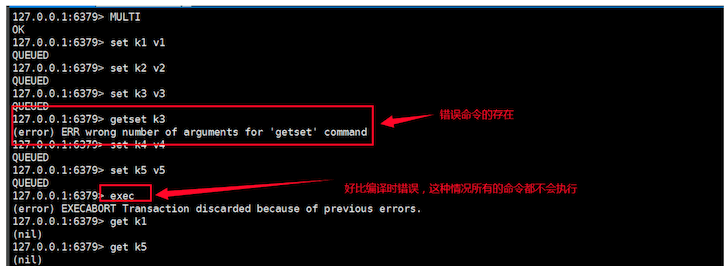
Redis的单条命了一定是原子性的,但是事务中,如果其中一个命令执行失败,其与的命令依旧执行。
命令执行失败有两种情况
-
编译型错误(命令错误),事务自动回滚,exec执行不会成功,例子如下:
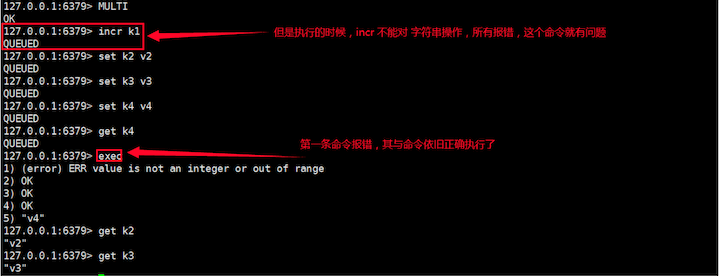
-
运行时错误,不保证原子性的证明
乐观锁
-
乐观锁
非常乐观,每次获取数据都认为这个数据没有变化,没有被人修改过,所以不会上锁。但是更新的时候需要去比较这个数据期间是否被人更新过,版本号机制:提交的版本一定要大于当前记录版本才可以修改。
乐观锁使用的场景:读非常多的情况下,这样可以提高吞吐量!
-
悲观锁
非常悲观,每次获取这个数据都认为会被人修改,每次获取数据都会上锁,如果别人要获取这个数据,就必须要等到解锁才可以拿到。传统关系型数据库都是这种锁机制,行锁,表锁,java的读写锁,synchronized都是悲观锁,操作之前先上锁。
Redis实现乐观锁操作
watch # 监控数据
unwatch # 取消监控
正常执行
# 初始化测试环境
127.0.0.1:6379> set money 100
127.0.0.1:6379> set use 0
127.0.0.1:6379> watch money # 事务开始之前监控money,事务过程中这个money没有发生变化,这个事务才可以执行成功,否则事务自动取消
127.0.0.1:6379> multi
127.0.0.1:6379> decrby money 20
QUEUED
127.0.0.1:6379> incrby use 20
QUEUED
127.0.0.1:6379> exec
1) (integer) 80
2) (integer) 20
失败测试
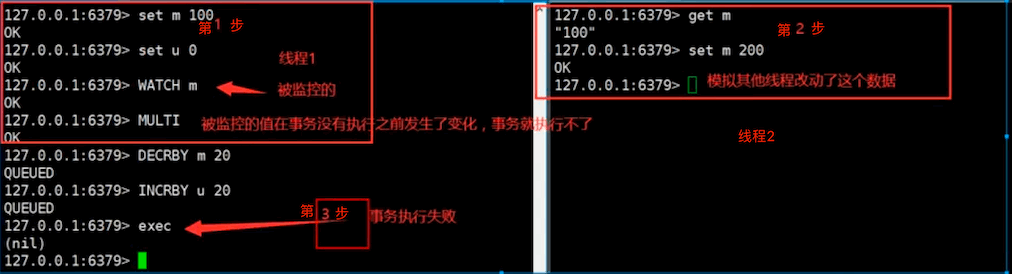
# 如果执行失败,需要放弃监控
127.0.0.1:6379> unwatch
# 重写监控
127.0.0.1:6379> watch m
127.0.0.1:6379> multi
127.0.0.1:6379> decrby m 20
QUEUED
127.0.0.1:6379> incrby u 20
QUEUED
127.0.0.1:6379> exec
1) (integer) 180
2) (integer) 20
# mysql
select version # 获取版本号 1
update version = version + 1 where version = 1
while() {
// 获取最新版本,直到修改成功
}
小结:
我们一旦执行exec,无论你事务是否执行成功,watch都会取消监控,我们需要重新watch这个变量
watch就是类似于我们之前学习的乐观锁机制。
3、发布订阅
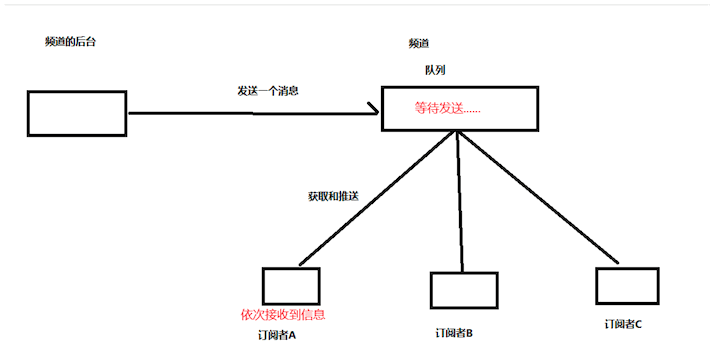
使用微信公众号:
这种模型下,我们是允许用户收到有延迟的,可以使用Redis的发布订阅功能!
比如说:网站内部信。
两个角色:
- 发布者
- 订阅者
subscribe # 订阅消息,
publish # 发布消息
unsubscribe # 退订指定频道
例子:
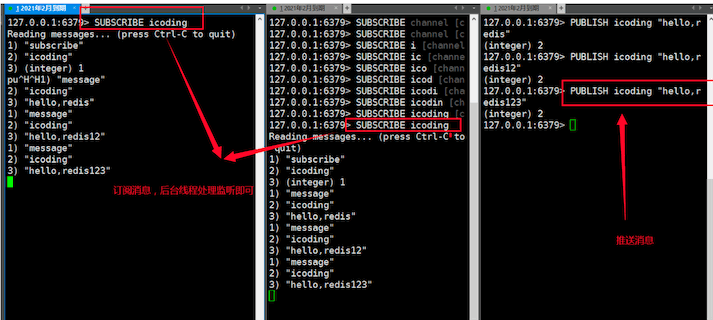
原理:底层是redis.pubsub.c 源码文件。它的核心是使用key作为chanel,而字典的值是一个链表,链表中维护订阅了这个key的所有客户端,每订阅一个,subscribe就把客户端添加到chanel的链表中。
publish发送消息,redis会找到这个chanel(key)的 链表,将消息发送给每个客户端

应用场景:实现消息系统,及时聊天,群聊
相比专业消息队列(如rabbitmq),它的功能就比较局限了。
4、主从复制(重点)
主从复制,将一台Redis服务器的数据复制到其他的Redis服务器。
单向复制:只能是主节点到从节点。Master: 写,Slave: 读
主从复制的好处:
- 数据冗余:数据备份,除了持久化之外的数据冗余方式
- 故障恢复:Master出现问题,从机可以顶替主节点工作
- 负载均衡:主节点提供写服务,从节点提供读服务,分担服务器负载压力
- 高可用基础:集群是高可用的基础
假设Redis所在服务器256G内存,我们不能讲所有内存分配给Redis,一般只想20G即可。真正的使用中,读多写少。
命令方式配置
1、启动集群
复制redis.conf为3个文件,以redis端口号.conf的格式命名,分别启动3个Redis实例,如下图
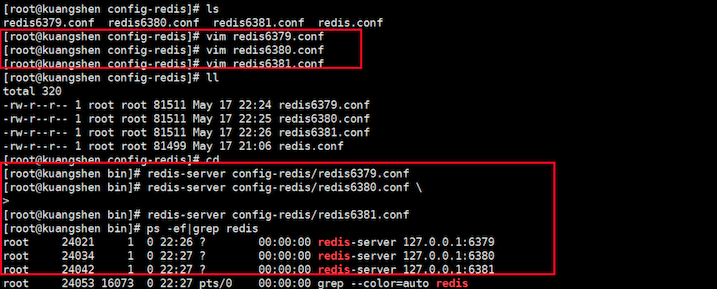
连接客户端
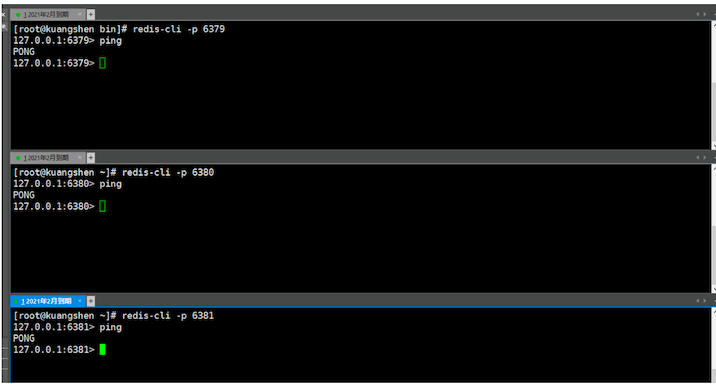
查看当前每个节点的信息 info replication
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:0
min_slaves_good_slaves:0
master_replid:15894a199166379e8e75f2c9ed8713828f81da87
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:5242880
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
# 默认情况下,三个节点都是 master
2、配一主二从
有两种方式配置
- 命令方式,slaveof master-ip master-port (重启实例后回master 角色,需要重新执行命令连接主节点)
- 配置文件修改,配置 replicaof master-ip master-port
这里使用命令方式

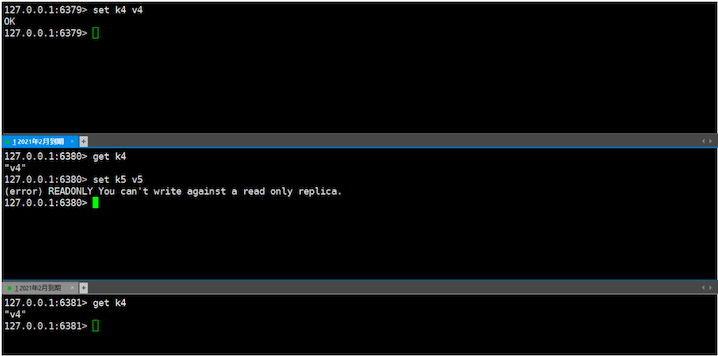
3、测试:从节点不能写入,主节点中设置的会自动同步到从节点中
# redis.conf 默认开启并配置为yes, 从节点不能写
# slave节点只允许read 默认就是 yes,这个配置只对slave节点才生效,对master节点没作用
replica-read-only yes
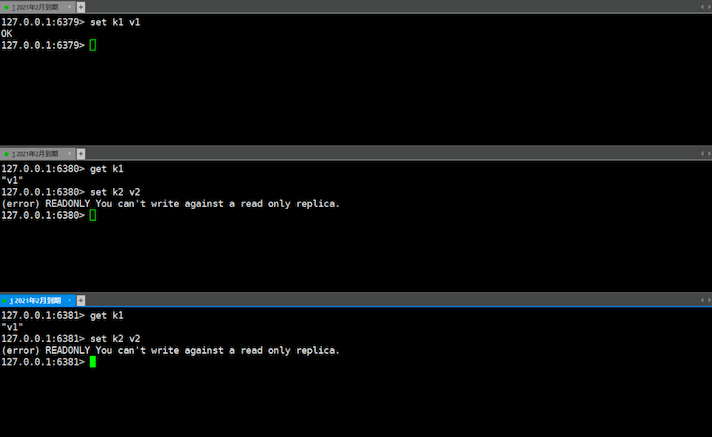
数据同步:
- 全量复制:从节点第一次连接到主节点的时候,会将主节点的所有内容全部同步一次
- 增量复制:第一次同步数据后,每次连接,主节点的所有命令同步增加进来
4、服务器(节点)挂了
-
主节点挂了,从节点等待主节点恢复(十分笨,不智能,后面使用哨兵模式实现主从自动切换解决),如果主节点恢复,数据会继续同步。
主节点挂了,从节点升级当老大,手动版
使用 SLAVEOF NO ONE命令,从节点恢复到master,然后手动配置其他从节点连接到这个节点上
# 1、恢复到master 127.0.0.1:7002> slaveof no one OK 127.0.0.1:7002> info replication # Replication role:master connected_slaves:0 min_slaves_good_slaves:0 master_replid:9a7763c54ae32880a72566fefa8443f76fa844b1 master_replid2:b8949076868b0fd644f8576c0cad1b76a4c1216a master_repl_offset:61552242 # 2、其他节点连接到这个节点上 127.0.0.1:7001> slaveof 127.0.0.1 7002 OK 127.0.0.1:7001> info replication # Replication role:slave master_host:127.0.0.1 master_port:7002 master_link_status:up # 3、查看7002的节点信息,已有一个从节点了 127.0.0.1:7002> info replication # Replication role:master connected_slaves:1 min_slaves_good_slaves:1 slave0:ip=127.0.0.1,port=7001,state=online,offset=61552270,lag=0 master_replid:5d555dbd6508b02cc2424a829a8bf61efbaaa706 -
从节点挂了,然后恢复,内容是否还可以同步?可以,从节点重新连接到主节点,数据会自动同步过来。(如果是通过命令方式配置从节点的,重启后需要手动配置,重新成为从节点)
其他集群方式,仅学习使用,生产环境不能使用

查看 info replication
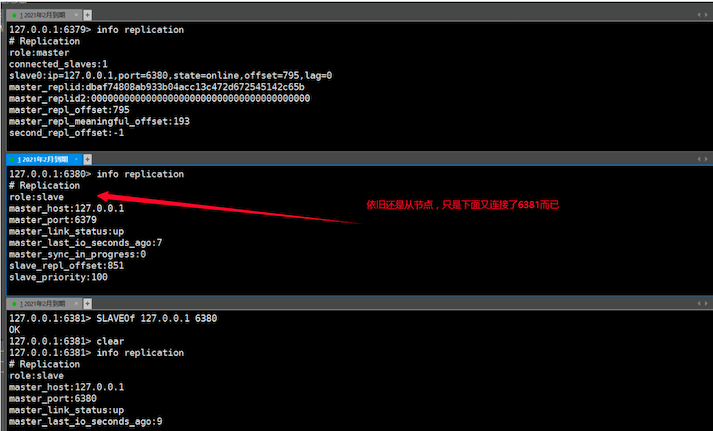
测试,数据会从6379 同步到 6380,6380会把数据同步都6381
注意:如果Redis是有密码的,主从节点的配置文件都要配置
# redis.conf
masterauth xxxx # 主节点的访问密码
主从节点的全部配置
# 可以通过命令看一下主从信息,v5.x版本前从是用slave表示,之后换成replication
# 1、master和slave节点都可以查看,要考虑主从切换的情况
info replication
# 2、修改slave的redis.conf
replicaof 192.168.1.100 6379 #master的ip,master的端口
# 3、在master和slave配置上添加,避免主节点宕机后重启成为从节点,配置文件没有设置密码的话就无法连接到新的主节点了
masterauth icoding #主机的访问密码
# 4、默认开启yes,在slave上配置
# yes 主从复制中,从服务器可以响应客户端请求
# no 主从复制中,从服务器将阻塞所有请求,有客户端请求时返回“SYNC with master in progress”;
replica-serve-stale-data yes
# 5、默认开启并配置为yes,在slave上配置
# slave节点只允许read 默认就是 yes,这个配置只对slave节点才生效,对master节点没作用
replica-read-only yes
# 6、默认没有开启,在slave的配置上打开
# slave根据指定的时间间隔向master发送ping请求,默认10秒,相当于心跳检测
repl-ping-replica-period 10
# 7、默认没有开启,在slave的配置上打开
# 复制连接超时时间。
# master和slave都有超时时间的设置。
# master检测到slave上次发送的时间超过repl-timeout,即认为slave离线,清除该slave信息。
# slave检测到上次和master交互的时间超过repl-timeout,则认为master离线。
# 需要注意的是repl-timeout需要设置为比repl-ping-slave-period更大的值,不然会经常检测到超时。
repl-timeout 60
# 8、是否禁止复制tcp链接的tcp nodelay参数,默认开启并配置为no,在master上配置
# 默认是no,即使用tcp nodelay,允许小包的发送。对于延时敏感型,同时数据传输量比较小的应用,开启TCP_NODELAY选项无疑是一个正确的选择
# 如果master设置了yes来禁止tcp nodelay设置,在把数据复制给slave的时候,会减少包的数量和更小的网络带宽。
# 但是这也可能带来数据的延迟。
# 默认我们推荐更小的延迟,但是在数据量传输很大的场景下,建议选择yes。
repl-disable-tcp-nodelay no
# 9、默认没有开启,在master上配置
# 复制缓冲区大小,这是一个环形复制缓冲区,用来保存最新复制的命令。
# 这样在slave离线的时候,不需要完全复制master的数据,如果可以执行部分同步,只需要把缓冲区的部分数据复制给slave,就能恢复正常复制状态。
# 缓冲区的大小越大,slave离线的时间可以更长,复制缓冲区只有在有slave连接的时候才分配内存。
# 没有slave的一段时间,内存会被释放出来,默认1m。
repl-backlog-size 5mb
# 10、默认没有开启,在master上配置
# master没有slave一段时间会释放复制缓冲区的内存,repl-backlog-ttl用来设置该时间长度。
# 单位为秒。
repl-backlog-ttl 3600
# 11、默认开启,在slave上配置
# 当master不可用,Sentinel会根据slave的优先级选举一个master。
# 最低的优先级的slave,当选master。
# 而配置成0,永远不会被选举。
# 注意:要实现Sentinel自动选举,至少需要2台slave。
replica-priority 100
# 12、默认没有开启,在master上配置
# redis提供了可以让master停止写入的方式,如果配置了min-slaves-to-write,健康的slave的个数小于N,mater就禁止写入。
# master最少得有多少个健康的slave存活才能执行写命令。
# 这个配置虽然不能保证N个slave都一定能接收到master的写操作,但是能避免没有足够健康的slave的时候,master不能写入来避免数据丢失。
# 设置为0是关闭该功能,默认也是0。
min-replicas-to-write 2
# 13、默认没有开启,在master上配置
# 延迟小于min-replicas-max-lag秒的slave才认为是健康的slave。
min-replicas-max-lag 10
5、哨兵模式
哨兵机制
上面的状态,主从节点挂了,我们只能手动配置,很原始的做法。能不能自动完成?
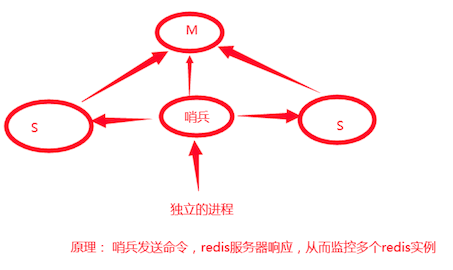
使用哨兵模式:
-
检测集群监控状况
-
自动选举主节点(哨兵也是集群,至少3个节点,使用投票机制)
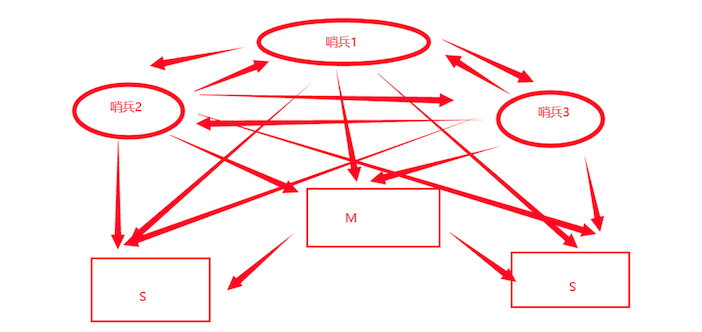
哨兵监视集群,哨兵之间相互监督
配置哨兵
# redis的安装根目录下,有个sentinel.conf
# 部署三个哨兵节点(sentinel要从redis的slave里选举一个node成为master,所以至少3个哨兵节点),同时监控一组redis服务(只有一个节点其实也可以,但有风险)
cp sentinel.conf /usr/local/redis-6379
vi sentinel.conf
# bind 127.0.0.1 192.168.1.1
# 测试的时候放开访问保护,
protected-mode no
port 26379 #默认是26379
daemonize yes # 守护进程的方式启动(后台)
pidfile /var/run/redis-sentinel-26379.pid #pid 集群要区分开
logfile /usr/local/redis-6379/sentinel/redis-sentinel.log #日志,非常重要
dir /usr/local/redis-6379/sentinel #工作空间
# sentinel监控的核心配置
# 1、最后一个2,quorum,>=2个哨兵主观认为master下线了,master才会被客观下线,才会选一个slave成为master
sentinel monitor icoding-master 127.0.0.1 6379 2
# 2、master访问密码
sentinel auth-pass icoding-master icoding
# 3、sentinel主观认为master挂几秒以上才会触发选举切换主节点
sentinel down-after-milliseconds icoding-master 3000
# 4、所有slave同步新master的并行同步数量,如果是1就一个一个同步,在同步过程中slave节点是阻塞的不可用的,同步完了才会放开
sentinel parallel-syncs icoding-master 1
# 5、同一个master节点failover之间的时间间隔,默认3分钟,举个例子,master节点A宕机了,重启后成为slave节点,它要重新成为master节点需要等3分钟
sentinel failover-timeout icoding-master 180000
测试的时候可以使用1个哨兵,多个哨兵只需修改配置文件的端口就可以了。
1、启动
# 跟redis-server一样,安装好redis后在/usr/local/bin就redis-sentinel的启动项
redis-sentinel sentinel.conf
# 如果要搭建集群,只需要将刚刚配置的sentinel.conf复制到其他节点即可
哨兵集群部署的约定
- 哨兵集群至少3个节点
- 最好三个节点在不同的物理机器上
- 一组哨兵最好只监控一组主从
2、测试主节点挂6379了之后
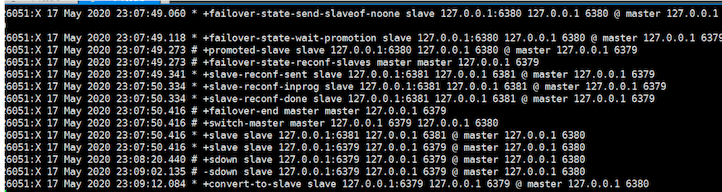
哨兵自动切换主节点到6380