 弹吉他的兔子
弹吉他的兔子
1、Jedis
Jedis是Redis官方推荐的Java连接开发工具,前面几节学习的Redis的所有命令在这里都可以找到。
注意,Redis安装在云服务器上连接:
- 配置文件的bind:127.0.0.1 (本机) 需要修改为 0.0.0.0(不限制IP)
- 安全组要打开
- Linux防火墙端口要开放
Jedis与原生Redis使用的比较
- 原生:Redis服务客户端、配置、命令
- Java: Redis对象(类)、配置(属性),方法(命令)
使用:
1、导入依赖
<dependencies>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
</dependencies>
2、测试代码
public class TestKey {
public static void main(String[] args) {
// Jedis 就是我们之前使用的客户端工具,抽象成为对象!
Jedis jedis = new Jedis("39.99.3.39",6379);
// 需要密码的要加这一行
jedis.auth("xxxxdis");
// 里面所有学习过的方法,都是我们之前命令的方法
// System.out.println(jedis.flushDB());
System.out.println(jedis.exists("username"));
System.out.println(jedis.set("username", "jude"));
System.out.println(jedis.get("username"));
System.out.println(jedis.mset("k10","v10","k11","v11","k12","v12"));
System.out.println(jedis.mget("k10","k11","k12"));
}
}
其他命令举例
-
expire 过期
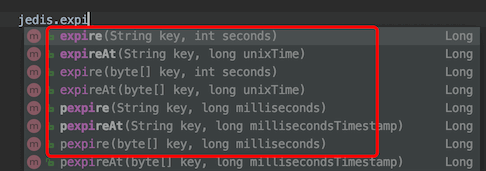
-
Incr 增加
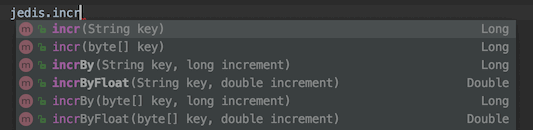
-
list
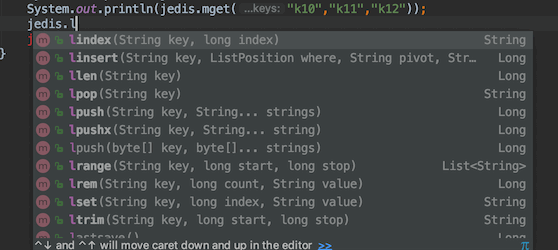
-
zset
-
bitmap
-
geo
-
hyperloglog
3、测试事务
public static void main(String[] args) {
// 1、连接redis
Jedis jedis = new Jedis("139.199.13.139",6379);
jedis.auth("juderedis");
// 2、初始数据
jedis.set("money","100");
jedis.set("use","0");
jedis.watch("money"); // 事务开始之前监控money,事务过程中这个money没有发生变化,这个事务才可以执行成功,否则事务自动取消
// 3、开启事务
Transaction multi = jedis.multi();
// 4、事务处理
try {
multi.decrBy("money",20);
multi.incrBy("use",20);
multi.exec();
} catch (Exception e) {
e.printStackTrace();
multi.discard();
} finally {
System.out.println(jedis.get("money"));
System.out.println(jedis.get("use"));
jedis.close();
}
}
jedis是十分简单的工具
2、Springboot集成Redis
分析源码
分析核心对象
1、JedisPool 和 LettucePool (配置连接池)
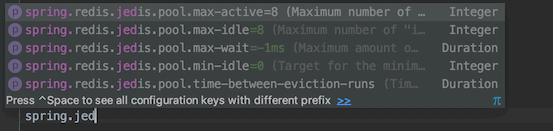
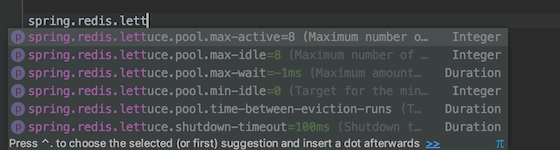
Springboot 1.x 使用的是jeids 作为连接池的,springboot 2.x使用的是lettuce作为连接池的
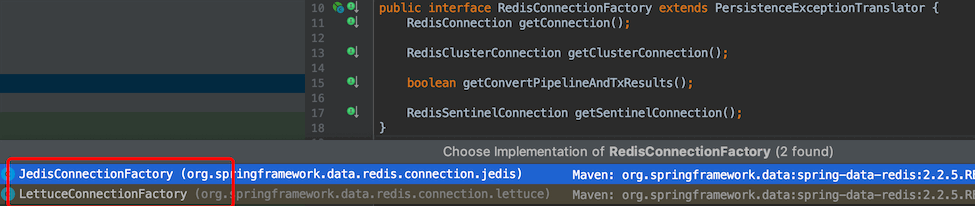
2、RedisConnectionFactory (配置连接的信息)
3、RedisTemplate (具体的操作)
集成
1、导入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
2、分析源码
两步:xxxAutoConfiguration 和 xxxProperties
全局搜索一下RedisAutoConfiguration(windows按两下shift,Mac就按两下⇧)
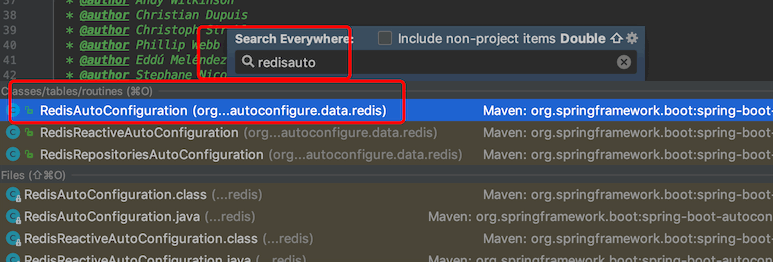
找到RedisAutoConfiguration
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass(RedisOperations.class)
@EnableConfigurationProperties(RedisProperties.class)
// 引入了两个连接池,但实际上是使用lettuce做为连接池,jedis连接池失效,点击JedisConnectionConfiguration的源码就知道了
@Import({ LettuceConnectionConfiguration.class, JedisConnectionConfiguration.class })
public class RedisAutoConfiguration {
// 启动时,向spring注入了两个bean
// 太简单,不符合真实开发需要,建议自定义一个Bean redisTemplate,则该bean失效
@Bean
@ConditionalOnMissingBean(name = "redisTemplate")
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory)
throws UnknownHostException {
RedisTemplate<Object, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
// 因为在redis中,String最常用,所以单独提出一个bean
@Bean
@ConditionalOnMissingBean
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory redisConnectionFactory)
throws UnknownHostException {
StringRedisTemplate template = new StringRedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
}
点进JedisConnectionConfiguration的源码
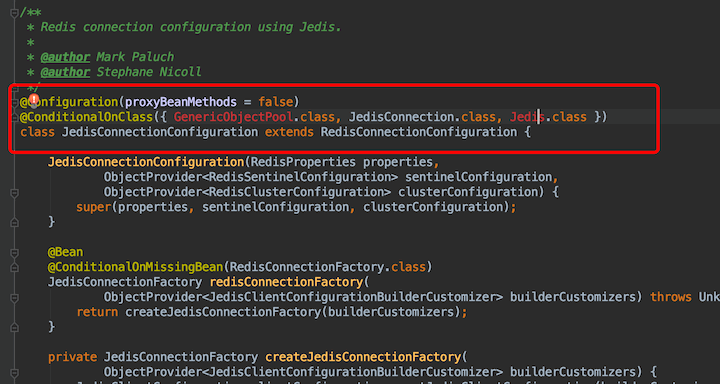
可以看到因为2.x版本的spring-boot-starter-data-redis没有引入Jedis的依赖包,jedis连接池配置类是不生效的。
点进RedisTemplate的源码,这个对象封装了关于Redis的所有操作
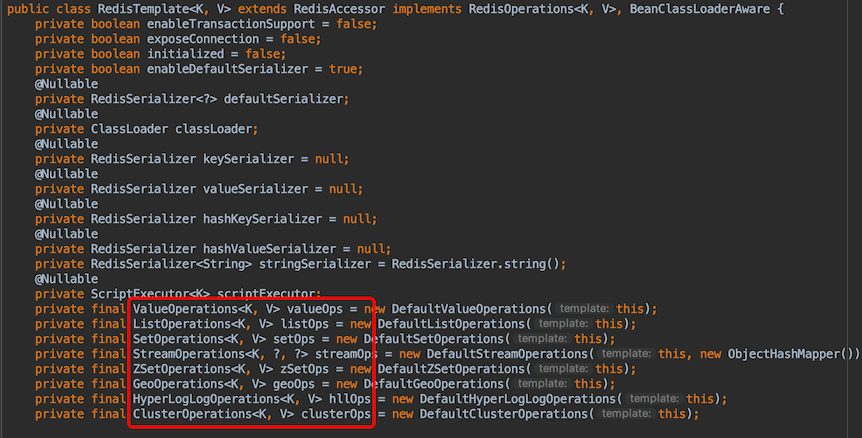
点击RedisTemplate的structure
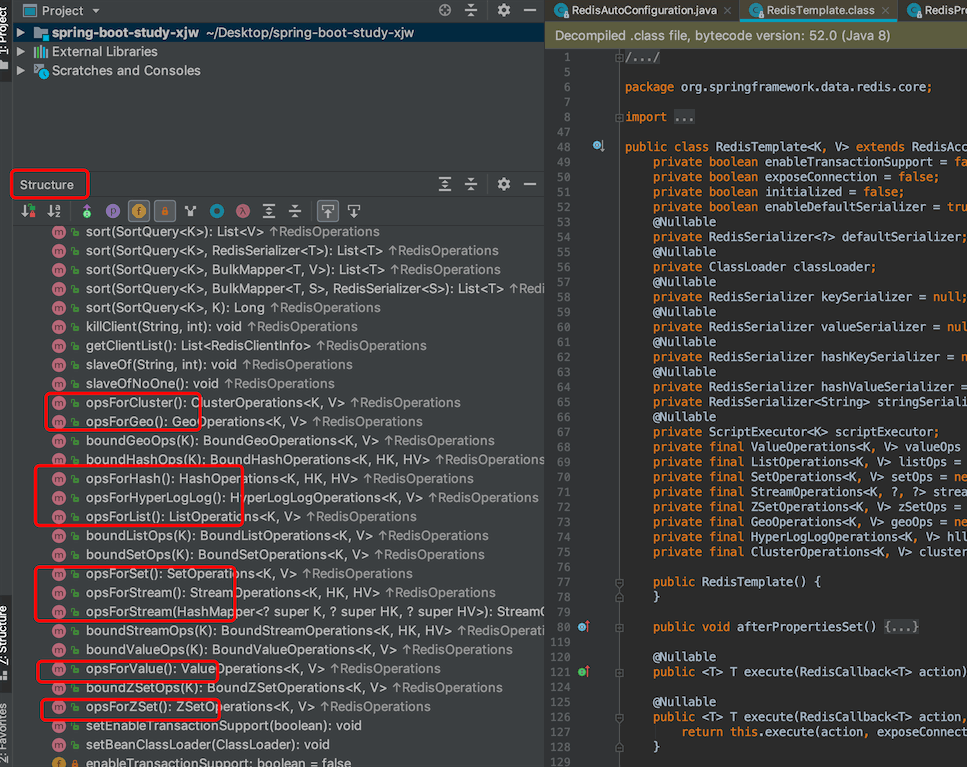
结论:
所有的具体操作还需要通过opsForxxxxx() 进行操作Redis的八大类型(String,list,set,hash,zset,geo,bitmap,hyperloglog)
操作Redis的步骤
1、导入依赖
2、编写redis的配置文件
# 单节点配置
spirng:
redis:
host: 39.99.13.39
password: xxxx # 无密码可以不用配置
# 主从+哨兵模式时配置
spring:
redis:
password: xxxxxx
sentinel:
master: jude-master
nodes: 7.13.9.19:26379,7.13.9.19:26381,7.13.9.19:26382 # 只需配置哨兵节点就可以了
3、在使用的类中,调用redisTemplate.opsForxxxxxx
@Autowired
RedisTemplate<String,String> redisTemplate;
@Test
public void testOps(){
redisTemplate.opsForValue().set("name","jude");
// list,向左插入值
redisTemplate.opsForList().leftPush("mylist","one","two");
// set,插入元素到集合
redisTemplate.opsForSet().add("myset","hello","coding","world");
// hash,给哈希key的field设置值
redisTemplate.opsForHash().put("myhash","filed1","hello");
// zset,员工的工资,安工资排序
redisTemplate.opsForZSet().add("salary","jude",5000);
// geo,添加城市和地理位置
redisTemplate.opsForGeo().add("china:city",new Point(116.23128,40.22077),"北京");
// bitmap,员工打卡情况
redisTemplate.opsForValue().setBit("sign:12",1,true);
// hyperloglog,统计基数
redisTemplate.opsForHyperLogLog().add("myhyper","1","3","5","1","3");
System.out.println(redisTemplate.opsForValue().getBit("sign:12",1));
// bitmap统计,返回1的个数
System.out.println(bitcount("sign:12"));
}
// redisTemplate 不能使用bitcount方法,需要自己扩充
private long bitcount(String key){
return redisTemplate.execute((RedisCallback<Long>) redisConnection -> redisConnection.bitCount(key.getBytes()));
}
发现redis命令和方法名并不一致,不像jedis的那样易懂,所以真实开放中,要对它进一步封装,封装成工具类,方法名给官方redis命令名称一致的话就比较清楚了。
自定义RedisTemplate Bean
官方自动配置的redisTemplate 太简单,不能满足实际开发的需要,一般都自定义一个redisTemplate Bean
@Configuration
public class RedisConfig {
// 对于对象和hash<key,value> 使用这个主要就是对象转换和编码问题!
@Bean
@SuppressWarnings("all")
public RedisTemplate<String,Object> redisTemplate(RedisConnectionFactory factory){
// 改为自己要操作的对象模式
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(factory);
// Object 如何序列化的问题
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper mapper = new ObjectMapper();
mapper.setVisibility(PropertyAccessor.ALL,JsonAutoDetect.Visibility.ANY);
mapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(mapper);
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
// key: String的序列化方式
template.setKeySerializer(stringRedisSerializer);
// hash: String的序列化方式
template.setHashKeySerializer(stringRedisSerializer);
// Object: Jsckson
template.setValueSerializer(jackson2JsonRedisSerializer);
// hashObject: Jsckson
template.setHashValueSerializer(jackson2JsonRedisSerializer);
// 其与的类型设置同理
// 生效
template.afterPropertiesSet();
return template;
}
}
封装工具类RedisUtils
需要注意一下,自动装配的redisTemplate一定是自定义的redisTemplate

@Component
public class RedisUtils {
@Autowired
RedisTemplate<String,Object> redisTemplate;
// ============================= common ============================
/**
* 指定缓存失效时间
* @param key
* @param timeout
* @return
*/
public boolean expire(String key,long timeout){
try{
if(timeout > 0){
redisTemplate.expire(key,timeout, TimeUnit.SECONDS);
}
return true;
}catch (Exception e) {
e.printStackTrace();
return false;
}
}
// ============================ String =============================
/**
* 普通缓存放入
* @param key
* @param value
* @return
*/
public boolean set(String key,Object value){
try{
redisTemplate.opsForValue().set(key,value);
return true;
}catch (Exception e){
e.printStackTrace();
return false;
}
}
// ============================ List =============================
/**
* 获取list缓存的内容
* @param key
* @param start
* @param end
* @return
*/
public List<Object> lrange(String key, long start, long end) {
try{
return redisTemplate.opsForList().range(key,start,end);
}catch (Exception e){
e.printStackTrace();
return null;
}
}
// ============================ Set =============================
/**
* 将数据放入set缓存
*
* @param key 键
* @param values 值 可以是多个
* @return 成功个数
*/
public long sadd(String key, Object... values) {
try {
return redisTemplate.opsForSet().add(key, values);
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
// ============================ HashMap =============================
/**
* 向一张hash表中放入数据,如果不存在将创建
*
* @param key 键
* @param item 项
* @param value 值
* @param timeout 失效时间(秒) 注意:如果已存在的hash表有时间,这里将会替换原有的时间
* @return true 成功 false失败
*/
public boolean hset(String key, String item, Object value, long timeout) {
try {
redisTemplate.opsForHash().put(key, item, value);
if (timeout > 0) {
expire(key, timeout);
}
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
// ============================ zSet =============================
// ============================ Geo =============================
// ============================ Bitmaps =============================
// ============================ HyperLogLog =============================
}
在代码中使用工具类,根据项目慢慢扩展, 不是一次性写好的
RedisUtils redis = new RedisUtils();
redis.hset("user","name","jude",10*60);
3、缓存击穿(一个点)
- 缓存击穿:针对一个key的大量并发查询,key过期失效的瞬间,所有请求就会穿破缓存,砸到了Mysql数据库去查询,导致数据库压力过大的现象,可能挂掉。
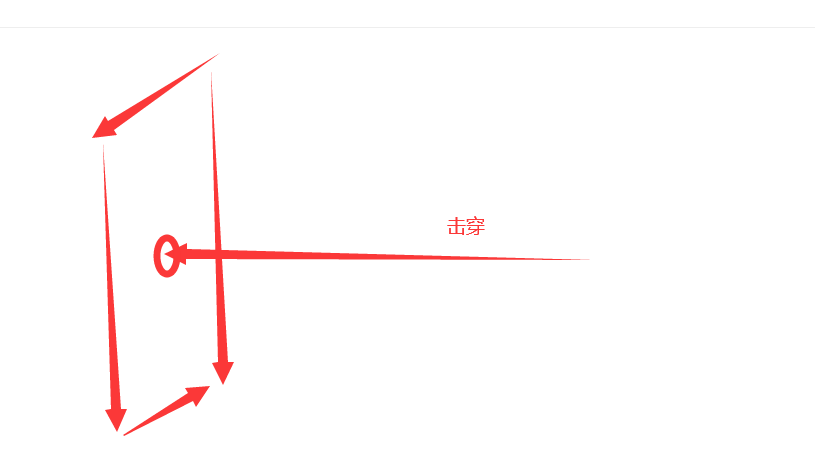
用户想要查询一个数据(热点的key),有很多人访问,如双11的秒杀活动,Redis不停的扛着高并发
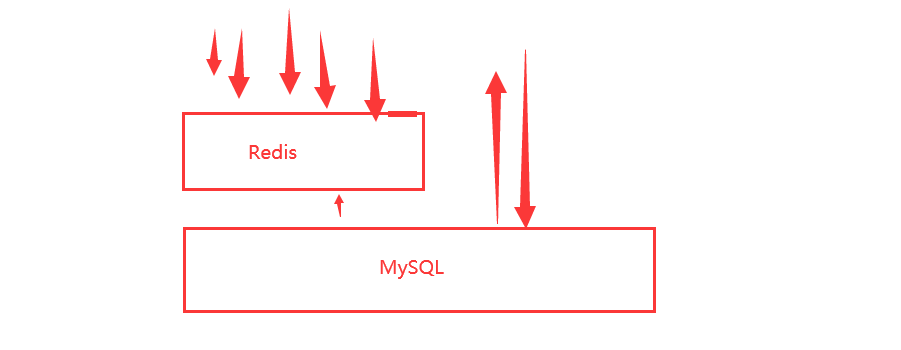
大量的请求都集中在一个 key 上 ,如100万个请求去get(“test”),突然一下缓存失效了,所有的请求一瞬间就砸到了MySQL上面,持续的并发就穿破Redis的缓存。
解决方案
1、设置热点数据永不过期
从缓存层面来说,没有设置过期时间,就不会产生穿透问题。
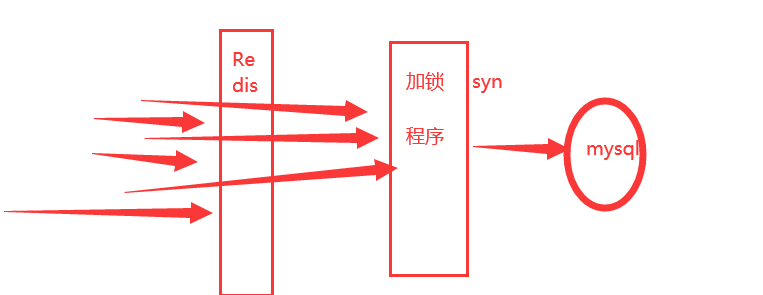
2、加互斥锁
分布式锁:只要加了锁,可以保证每个key,只有一个线程去查询后端的服务,其他线程就等待。
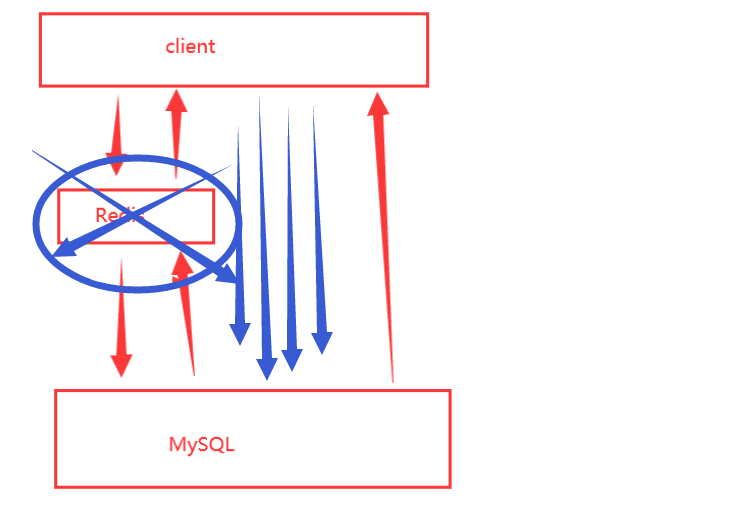
核心:转移压力,尽量服务不崩就可以了,将数据库承受的压力转义到了分布式锁上面,如下图:
4、缓存穿透(不存在)
- 缓存穿透:用户想要查询一个数据,在redis中不存在(缓存未命中),就会进入数据库去查询。如果有就写回redis,没有则redis就不存在这个数据的缓存。当很多用户查询的时候,缓存都没有命中,所有的请求最终还是进入数据库去查询,导致数据库压力过大的现象,可能挂掉。
解决方案
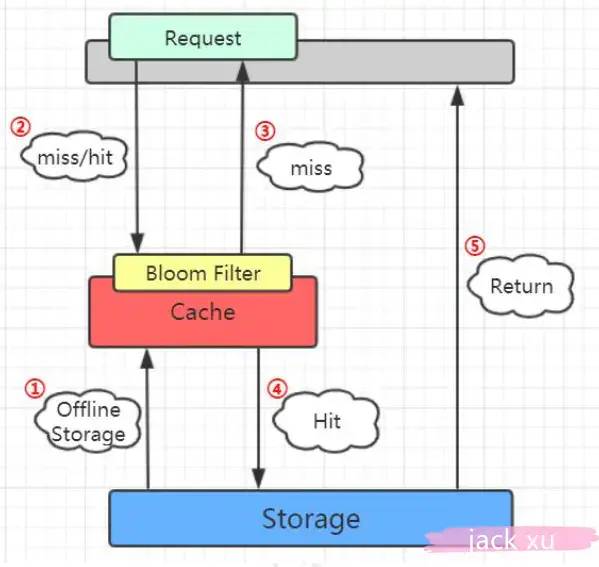
1、布隆过滤器
布隆过滤器是一种数据结构,判断这个数据是否存在,在查询的时候进行校验,不符合(不存在)则丢弃,直接返回空,避免了直接到数据库查询。
第一步是将数据库所有的数据加载到布隆过滤器。
第二步当有请求来的时候先去布隆过滤器查询,如果bloom filter说没有,直接返回空
如果bloom filter说有,再往下走之前的流程。
- 适用场景:数据命中低,数据相对固定实时性低
- 维护成本:代码维护复杂,缓存空间占用少
我的问题是应该将什么样的数据放到布隆过滤器中,也就是第一步数据预热的问题,新增的数据也可以实时放入到布隆过滤器,所以长度稍微长一些
场景举例:
我们的推荐服务有4亿个用户uid, 我们会根据用户的历史行为进行推荐(非实时),所有的用户推荐数据放到hbase中,但是每天有许多新用户来到网站,这些用户在当天的访问就会穿透到hbase。为此我们每天4点对所有uid做一份布隆过滤器。如果布隆过滤器认为uid不存在,那么就不会访问hbase,在一定程度保护了hbase(减少30%左右)。
什么时候使用布隆过滤器,还真要看业务场景支不支持。
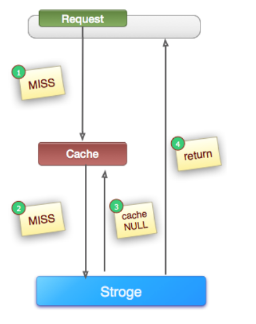
2、缓存空对象
请求过来,redis中查询不存在,到达数据库查询,数据库有数据就缓存数据到redis中,没有就缓存空字符串到redis中,并设置一个较短的过期时间,如60s。第二个请求到达,查询同样的key,就直接返回空字符串,避免了数据库的查询。
// 伪代码
public String getPassThrough(String key) {
// 从缓存中获取数据
String cacheValue = cache.get(key);
// 缓存为空
if (StringUtils.isBlank(cacheValue)) {
// 从存储中获取
String storageValue = storage.get(key);
cache.set(key, storageValue);
// 如果存储数据为空,需要设置一个过期时间(300秒)
if (StringUtils.isBlank(storageValue)) {
cache.expire(key, 60 * 5);
}
return storageValue;
} else {
// 缓存非空
return cacheValue;
}
}
- 适应场景:数据命中低,数据频繁变化实时性高
- 维护成本:代码维护简单,需要过多的缓存空间
5、缓存雪崩(一个面)
在某一个时间段,缓存集体失效,或者redis挂了,就会发生缓存雪崩。
场景:双十一,0点抢购。
将抢购商品集中的放入缓存(一个小时过期),一个小时后集体失效,对于这批商品而言,所有的请求直接查询数据库。数据库周期性的压力,存储层的调用会暴增,可能直接挂掉,这就是触发了雪崩。
解决方案
1、保证Redis的高可用,主从+哨兵模式,更大一点的可以考虑集群模式
2、限流降级,缓存失效后的处理,加锁,返回预定的对象(服务降级)
3、数据预热, 在正式的部署之前,我们先将这批数据放入到redis缓存中,假设即将发生高并发的情况,这个时候设置不同的过期时间,让缓存失效时间比较均匀。
4、缓存永不过期:冰封了
5、过期时间错开(可以在key创建时加入一个1-10分钟的随机数给到key)
6、多缓存数据结合(不要直接打到DB上,可以在DB上再加一个搜索引擎ES)
7、在代码里进行redis数据写入时通过锁解决(synchronized,分布式锁zookeeper),如果使用synchronized的话,最多并发放入的请求个数=该业务集群的节点数,使用分布式锁的话就是最多并发放入请求个数只有一个。
6、布隆过滤器
通常我们会遇到很多要判断一个元素是否在某个集合中的业务场景,一般想到的是将集合中所有元素保存起来,然后通过比较确定。set,链表、树、散列表(又叫哈希表,Hash table)等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间也会呈现线性增长,最终达到瓶颈。同时检索速度也越来越慢。
1970年布隆提出了一种过滤数据的数据结构,由一个固定大小的二进制向量或者位图(bitmap)和一系列映射函数组成,它就是布隆过滤器。
先了解一下哈希函数的概念:将任意大小的输入数据转换成特定大小的输出数据的函数,转换后的数据称为哈希值或哈希编码,也叫散列值。下面是一幅示意图:
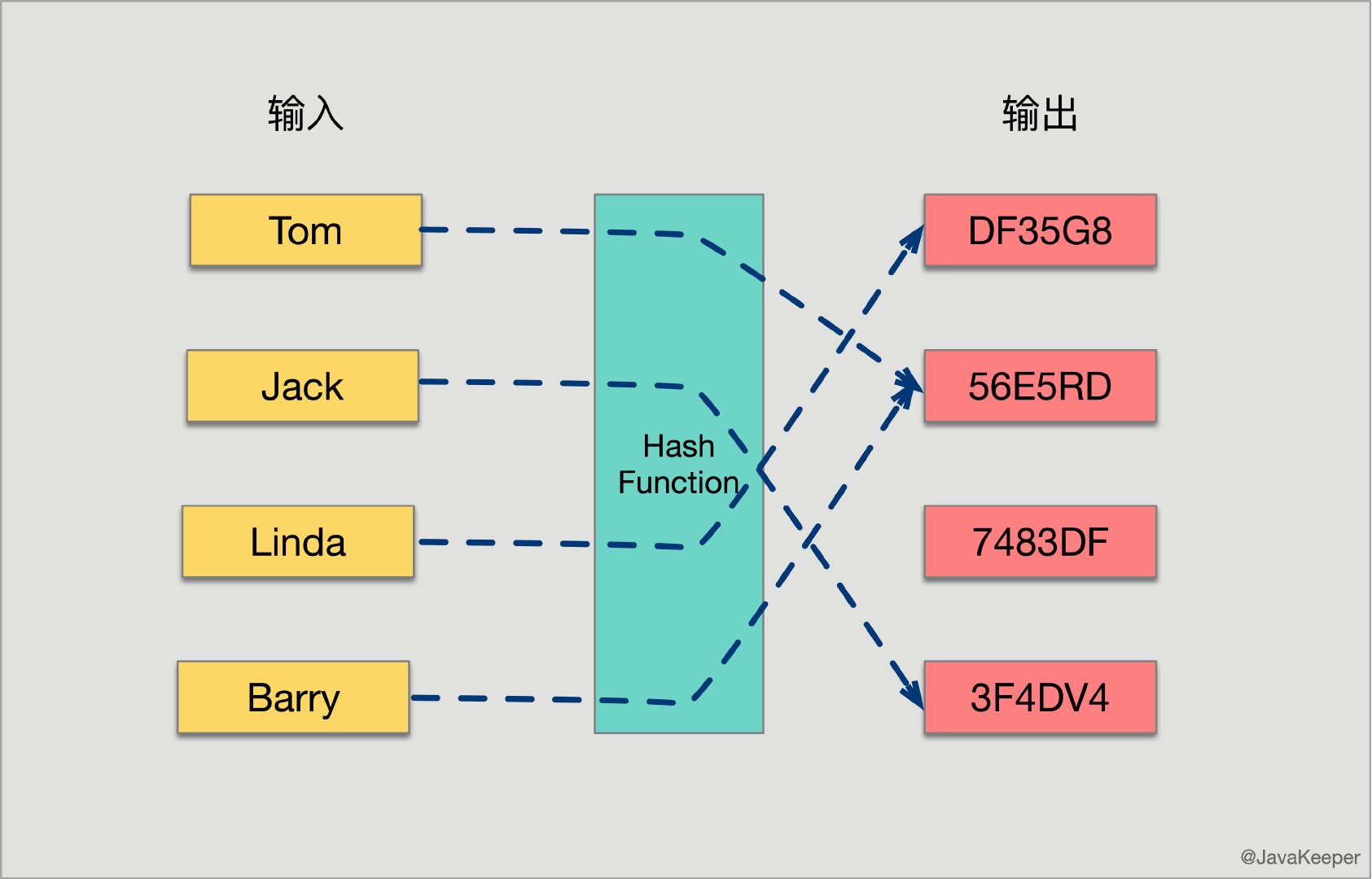
所有散列函数都有两个基本特性:
-
如果两个散列值是不相同的(根据同一函数),那么这两个散列值的原始输入也是不相同的。这个特性是散列函数具有确定性的结果,具有这种性质的散列函数称为单向散列函数。
-
散列函数的输入和输出不是唯一对应关系的,如果两个散列值相同,两个输入值很可能是相同的,但也可能不同,这种情况称为散列碰撞(collision)
但是用 hash表存储大数据量时,空间效率还是很低,当只有一个 hash 函数时,还很容易发生哈希碰撞,所以一般经过多个hash函数计算,得到不同坐标的二进制向量0和1,得到
布隆过滤器初始状态都是0,当有数据加入集合,通过哈希函数将数据转换为二进制向量0和1,如下图:
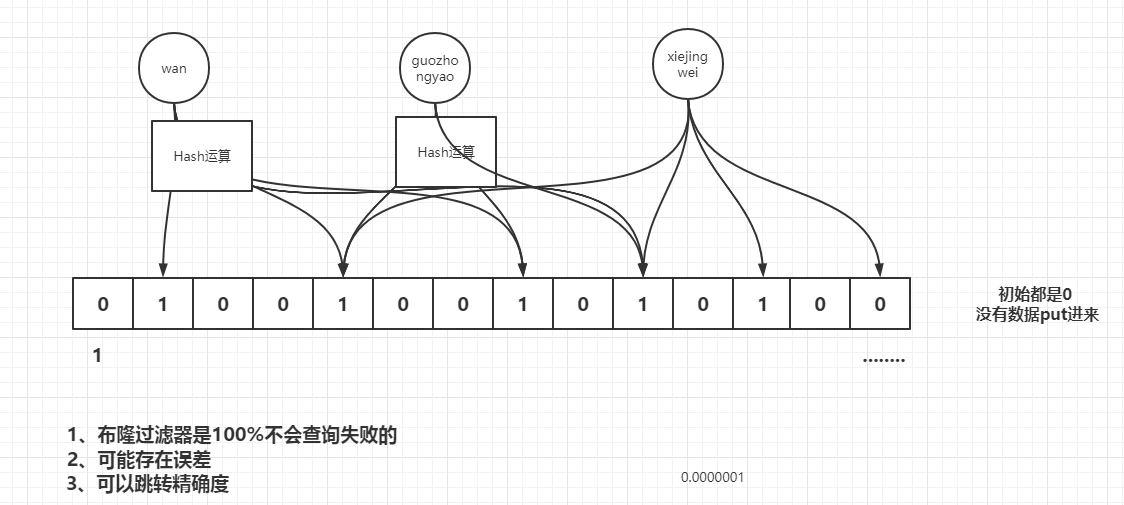
查询某个变量的时候我们只要看看这些点是不是都是 1:
- 如果这些点有一个 0,则被查询变量一定不在;
- 如果都是 1,则被查询变量很可能存在,因为散列函数是会有碰撞的。这个就是所谓的误判,是指多个输入经过哈希之后在相同的bit位置都是1,这样就无法判断究竟是哪个输入产生的。
核心三个点:
1、布隆过滤器是一个数据结构(容量,精确度)容量一旦初始化则不可更改。
2、布隆过滤器对于已存在的数据,不会存在误判
3、所有的存储都是使用 0 1 然后数据使用 hash 运算,然后通过hash碰撞来存放测试
过滤器中都是0和1,所以说,你无法查询这个数据是什么,只能查询它是否存在,然后还发现,这个数据不能删除
put 添加数据,mightContain判断数据是否存在。
布隆过滤器的应用举例:
-
今日头条:刷头条(很少刷到相同的内容,抖音)
所有的视频(去判断。set (没看)——> set(看了的))十分不科学。
有没有可能刷到同一个视频?在实际中是可能存在的。(有误差)
-
缓存宕机、缓存击穿场景,一般判断用户是否在缓存中,如果在则直接返回结果,不在则查询db,如果来一波冷数据,会导致缓存大量击穿,造成雪崩效应,这时候可以用布隆过滤器当缓存的索引,只有在布隆过滤器中,才去查询缓存,如果没查询到,则穿透到db。如果不在布隆器中,则直接返回。
Java中使用布隆过滤器
1、pom.xml导入依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.0-jre</version>
</dependency>
2、测试
public class TestBF {
public static void main(String[] args) {
// 创建一个布隆过滤器
// 第一个参数:字符集
// 第二个参数:预计插入数据的长度(二进制向量的容量长度)
// 第三个参数:fpp就是期望的误判率,错误率越低,需要的空间越大
BloomFilter<CharSequence> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.forName("utf-8")), 100000, 0.000001);
// 填满数据
for (int i = 0; i <100000; i++) {
bloomFilter.put(String.valueOf(i));
}
int flag = 0;
// 查询数据(故意查不存在的)
for (int i = 100000; i < 200000; i++) {
if (bloomFilter.mightContain(String.valueOf(i))){
flag++;
}
}
// 查询存在的数据(100% 可以查到)
for (int i = 0; i < 100000; i++) {
if (bloomFilter.mightContain(String.valueOf(i))){
flag++;
}
}
System.out.println("误判了:"+ flag);
}
}
特点:
1、不存在的数据可能会误判被查到,我们可以调整精确度来尽量避免这个问题(时间和空间问题)
2、存在的数据100% 不会误判。
3、这种方式布隆过滤器只在java 本机内存中,要考虑分布式的问题
Redis集成布隆过滤器
分布式环境中,布隆过滤器肯定还需要考虑是可以共享的资源,不能只用在java 本机内存中,这个时候可以使用Redis。Redis官方提供的布隆过滤器支持的是到了Redis4.x以后提供的插件功能,布隆过滤器作为一个插件加载到 Redis Server 中,给 Redis 提供了强大的布隆去重功能。
集成
# 1、下载布隆过滤器插件
wget https://github.com/RedisBloom/RedisBloom/archive/v2.2.2.tar.gz
# 解压
tar -zxvf v2.2.2.tar.gz
# 2、进入解压目录之后make
[root@kuangshen RedisBloom-2.2.2]# make
# 3、redis的配置文件添加插件,MODULES
loadmodule /opt/RedisBloom-2.2.2/redisbloom.so
# 重启redis,就加载好了
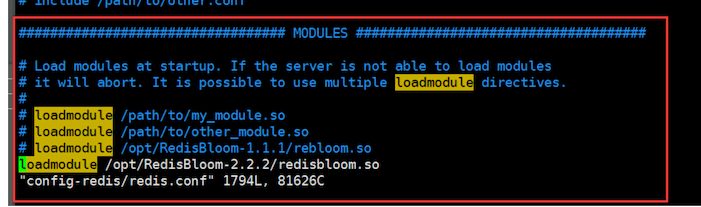
核心文件redisbloom.so
基本使用
# 进入redis-cli客户端
# 1、添加数据到布隆过滤器,默认过滤器元素容量为100,误判率0.01(精度)
127.0.0.1:6379> bf.add users value1
# 批量添加
127.0.0.1:6379> bf.madd users value2 value3
127.0.0.1:6379> type users
MBloom
# 2、手动编写 bf 的配置,误判率0.001(精度),过滤器容量 10000个元素,添加的条目数超过此数字后,性能将开始下降
# 如果对应的key已存在,会报错
127.0.0.1:6379> bf.reserve user-bm 0.001 10000
(error) ERR item exists
# 3、判断是否存在
127.0.0.1:6379> bf.exists user-bm value1
# 一次匹配多个数据
127.0.0.1:6379> bf.mEXISTS user-bm value1 value2 value3
Java集成Redis BloomFilter
1、导入依赖
<!-- https://mvnrepository.com/artifact/com.redislabs/jrebloom -->
<dependency>
<groupId>com.redislabs</groupId>
<artifactId>jrebloom</artifactId>
<version>2.0.0-m2</version>
</dependency>
2、测试
package com.coding;
import io.rebloom.client.Client;
public class TestBF {
public static void main(String[] args) {
Client bfClient = new Client("127.0.0.1", 6379);
// 创建一个过滤器,容量为1000个元素,误判率为0.01
bfClient.createFilter("icoding",1000,0.01);
// 向bf中添加数据(将这个数据hash运算之后,)
bfClient.add("bm-icoding","arry");
// 然后再次判断这个值是够存在 coding,hash,然后比对。!
System.out.println(bfClient.exists("bm-icoding","coding"));
}
}
小结
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
参考:https://blog.csdn.net/weixin_45727359/article/details/106110663
https://blog.csdn.net/u011870547/article/details/106018872/
https://juejin.im/post/5c9d8db9f265da60f5612835
7、分布式锁Redisson
高效的分布式锁(设计)
1、互斥(在分布式高并发的情况下,同一时刻只能有一个线程获得锁,最基本的点)
2、防止死锁(在分布式高并发的情况下,有线程获得锁的同时,还没有来的去释放锁,现在系统故障了,其他线程都无法获取,死锁),因此所有的锁都需要设置有效时间,解决死锁问题。
3、性能(减少锁等待时间,避免大量线程阻塞)
- 锁的粒度要小,比如你要通过锁来减库存,那这个锁的名称你可以设置成是商品的ID,而不是任取名称。这样这个锁只对当前商品有效,锁的颗粒度小。
- 锁的范围一定要小,比如只要锁2行代码就可以解决问题的,那就不要去锁10行代码了。
4、可重入锁(即同一个线程可以重复拿到同一个资源的锁,JUC的ReentrantLock就是可重入锁)
Redisson
- 加锁
- 锁有效时间(解决死锁问题,保证高可用)
- 锁删除
使用
1、导入依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.12.5</version>
</dependency>
2、分析源码
全局搜索RedissonAutoconfiguration,
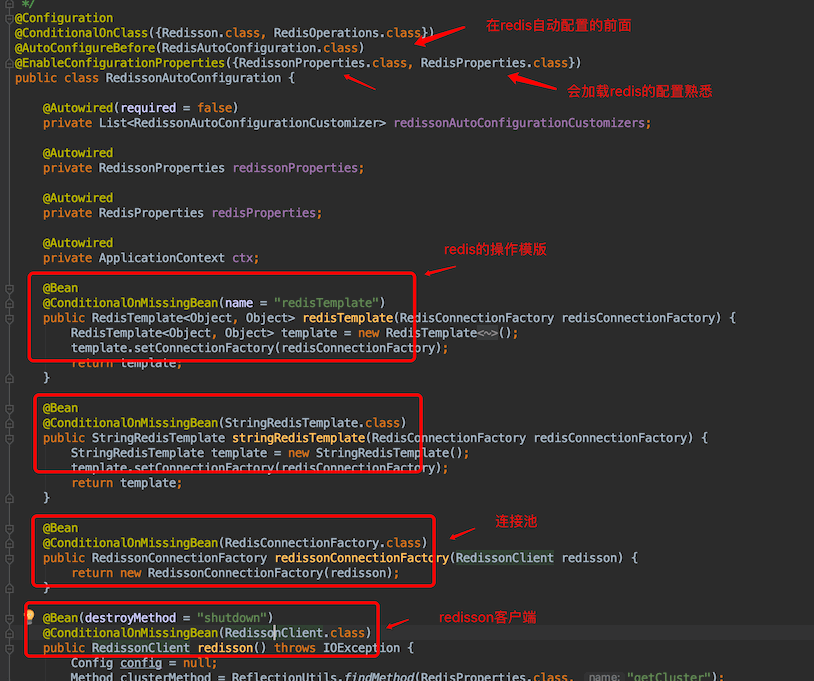
redisson是基于redis的分布式锁,但是并不是使用lettuce作为连接池,而是使用redisson作为连接池,而且比RedisAutoconfiguration先加载的。

3、编写测试代码
@RestController
public class TestRedisson {
@Autowired
RedissonClient redissonClient;
@GetMapping("redission")
public String testRedison(){
RLock userLock = redissonClient.getLock("userid:1223");
System.out.println("get Lock");
try{
// 如果有锁,等待5秒,如果拿到了锁持有30秒
userLock.tryLock(5,30, TimeUnit.SECONDS);
System.out.println("获取到锁");
TimeUnit.SECONDS.sleep(20);
System.out.println("88");
}catch (InterruptedException e){
e.printStackTrace();
}finally {
System.out.println("释放锁");
userLock.unlock();
}
return "redission";
}
}
启动项目,浏览器访问http://localhost:8080/redission
后台输出:
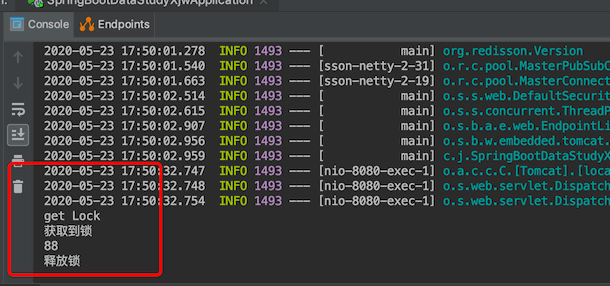
redisson默认就是加锁30秒,建议也是30秒以上,它还有一个监视锁的机制,默认的lockWatchdogTimeout会每隔10秒观察一下,待到20秒的时候如果主进程还没有释放锁,就会主动续期30秒
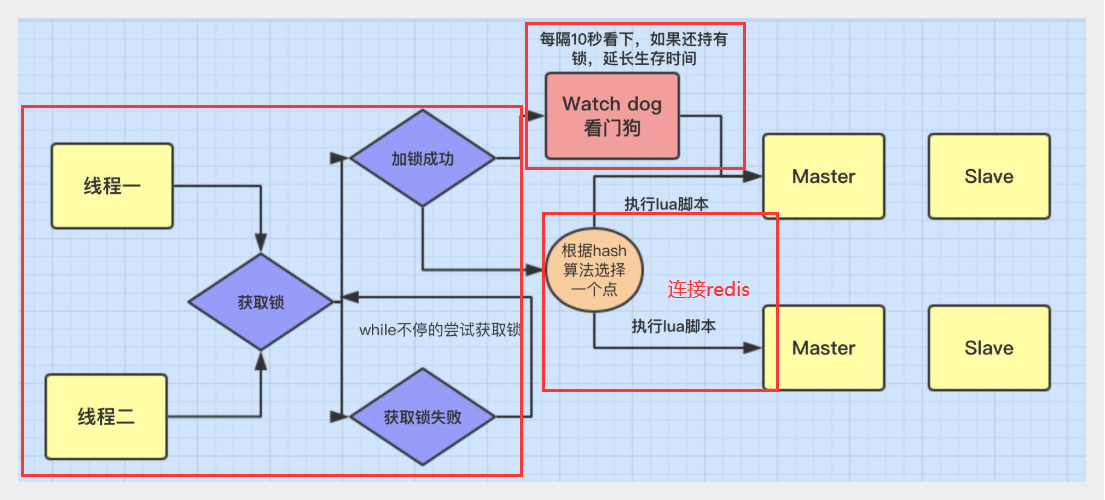
分布式锁流程
-
加锁机制
线程去获取锁,获取成功: 执行lua脚本,保存数据到redis数据库。
线程去获取锁,获取失败: 一直通过while循环尝试获取锁,获取成功后,执行lua脚本,保存数据到redis数据库。
-
Watch dog延迟锁有效时间机制
-
可重入锁机制
Redisson可以实现可重入加锁机制的原因,我觉得跟两点有关:
- 1、Redis存储锁的数据类型是 Hash类型
- 2、Hash数据类型的key值包含了当前线程信息。
下面是redis存储锁的机制

点进RedissonLock.java的源码,找到trylock方法

tryAcquire就是加锁方法,
private Long tryAcquire(long leaseTime, TimeUnit unit, long threadId) {
return get(tryAcquireAsync(leaseTime, unit, threadId));
}
点击tryAcquireAsync方法

先看tryLockInnerAsync方法,加锁的代码
<T> RFuture<T> tryLockInnerAsync(long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {
internalLockLeaseTime = unit.toMillis(leaseTime);
return evalWriteAsync(getName(), LongCodec.INSTANCE, command,
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);", // 返回key的剩余生存时间,因为当前线程bu
Collections.singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
}
可以看到加锁执行的是一段lua脚本,执行exist、hincrby、pexpire多个命令,这个锁的redis存储的数据类型是HASH,value是一个hash类型的数据。
-
Collections.singletonList(getName()) , 第一元素getName() 等于lua脚本中的 KEYS[1],也就是分布式锁的key,
-
internalLockLeaseTime 锁的过期时间,对应lua脚本中的 redis.call(‘pexpire’, KEYS[1], ARGV[1])
-
getLockName(threadId) 对应lua脚本中的 ARGV[2],即hash中的字段,它包含了当前线程信息
protected String getLockName(long threadId) { return id + ":" + threadId; }
看evalWriteAsync方法
protected <T> RFuture<T> evalWriteAsync(String key, Codec codec, RedisCommand<T> evalCommandType, String script, List<Object> keys, Object... params) {
CommandBatchService executorService = createCommandBatchService();
RFuture<T> result = executorService.evalWriteAsync(key, codec, evalCommandType, script, keys, params);
if (!(commandExecutor instanceof CommandBatchService)) {
executorService.executeAsync();
}
return result;
}
回到tryAcquireAsync方法,leaseTime持锁时间等于-1的时候,才会启动watchdog机制,获取一个30秒的锁成功后,调用scheduleExpirationRenewal方法给锁失效前进行续命,源码
private void scheduleExpirationRenewal(long threadId) {
ExpirationEntry entry = new ExpirationEntry();
ExpirationEntry oldEntry = EXPIRATION_RENEWAL_MAP.putIfAbsent(getEntryName(), entry);
if (oldEntry != null) {
oldEntry.addThreadId(threadId);
} else {
entry.addThreadId(threadId);
renewExpiration(); // 失效前续命
}
}
点击 renewExpiration
private void renewExpiration() {
ExpirationEntry ee = EXPIRATION_RENEWAL_MAP.get(getEntryName());
if (ee == null) {
return;
}
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
ExpirationEntry ent = EXPIRATION_RENEWAL_MAP.get(getEntryName());
if (ent == null) {
return;
}
Long threadId = ent.getFirstThreadId();
if (threadId == null) {
return;
}
RFuture<Boolean> future = renewExpirationAsync(threadId); // 重点,锁续命
future.onComplete((res, e) -> {
if (e != null) {
log.error("Can't update lock " + getName() + " expiration", e);
return;
}
if (res) { // 续命成功,调用本身10后又来检查锁
// reschedule itself
renewExpiration();
}
});
}
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS); // 这里internalLockLeaseTime是30秒,也就是10秒后观察锁的失效,
ee.setTimeout(task);
}
重点,锁续命方法renewExpirationAsync,点击源码

最终调用redis pexpire命令给key(锁名称)续命30毫秒,不过前面`trylock`的时候参数leaseTime=-1才会启动watchDog机制给锁续命,其实就是每隔10秒重新设置redis 的key过期时间为30秒后。
缺点
在redis master实例宕机的时候,可能导致多个客户端同时完成加锁:如果你对某个redis master实例,写入了myLock这种锁key的value,此时会异步复制给对应的master slave实例。但是这个过程中一旦发生redis master宕机,主备切换,redis slave成为新的redis master,但是没有myLock锁。接着就会导致,客户端2来尝试加锁的时候,在新的redis master上完成了加锁,而客户端1也以为自己成功加了锁。此时就会导致多个客户端对一个分布式锁完成了加锁。这时系统在业务上一定会出现问题,导致脏数据的产生。
参考:
- https://www.cnblogs.com/qdhxhz/p/11046905.html
- https://blog.csdn.net/chongbaozhong/article/details/114682080
- https://www.cnblogs.com/wkynf/p/14479779.html
8、Redis6.0新特性
Redis6.0开始支持多线程IO,但是默认是不开启的,默认还是单线程
打开redis.conf,可以看到多线程的相关配置是注释了

redis瓶颈在 cpu 和 内存! 和IO线程无关
新特性参考这篇博客:https://www.cnblogs.com/madashu/p/12832766.html