 弹吉他的兔子
弹吉他的兔子
1、入门
ElasticSearch概述
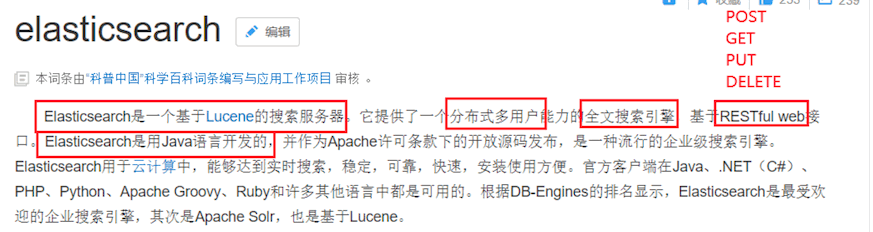
原来我们基于数据库搜索:select * from xxx where xx=xxx,使用sql查询
大数据量下,索引失效了,就十分的慢,真正的大数据搜索都不会直接使用SQL查询,而是将数据导入到搜索引擎中,通过搜索引擎查询数据。
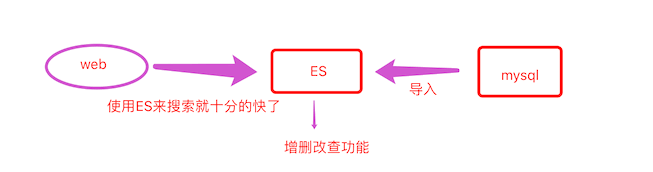
ElasticSearch(下面简称ES) 现在主流用的是6.x和7.x版本,如何用它和它的原理思想最重要。
第一个版本:2010年2月,开源在github上
官网下载:https://www.elastic.co/cn/downloads/elasticsearch
文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/7.x/getting-started.html
与Solr的比较
Solr简介
-
Apache下的顶级开源项目,使用java开发,基于Lucene封装的全文搜索服务器。
-
提供的功能:大量的配置,索引进行了优化。
-
是独立运行的服务器
-
使用的方式:Post发送一个请求xml文档,添加、删除、更新,Get请求进行查询
ES简介
- 是一个实时分布式搜索和分析引擎,在大数据领域使用十分广泛,比如百度搜索高亮,商品搜索
- 实时搜索,效率十分高,使用倒排索引
- 是一个基于Apache Lucene的开源搜索引擎
Lucene简介
- 是一个开源的全文检索引擎工具包,查询引擎、索引引擎、文本分析。现在很少直接使用Lucene来实现全文检索了
全文检索
- Baidu,Google,GitHub 都是通过从互联网上提取的各个网站的信息(网页文字),将这些信息建立到数据库中的。
数据来源
- 爬虫,主动收集
- 数据库中的内容
- 清洗完毕的数据
- 搞懂数据是如何存储和操作的
性能对比
1、当单纯的对已有数据进行搜索时,Solr更快。
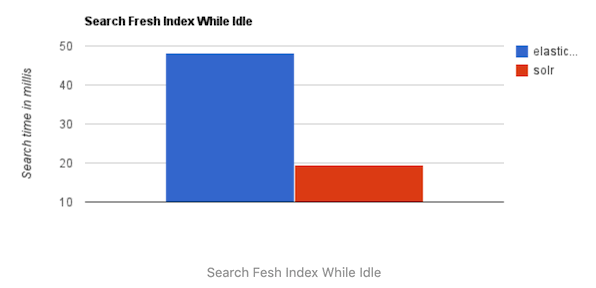
2、当实时建立索引时, Solr会产生io阻塞,查询性能较差, Elasticsearch具有明显的优势。
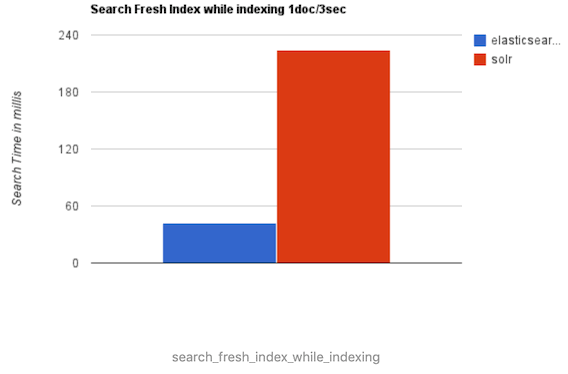
3、随着数据量的增加,Solr的搜索效率会变得更低,而Elasticsearch却没有明显的变化。
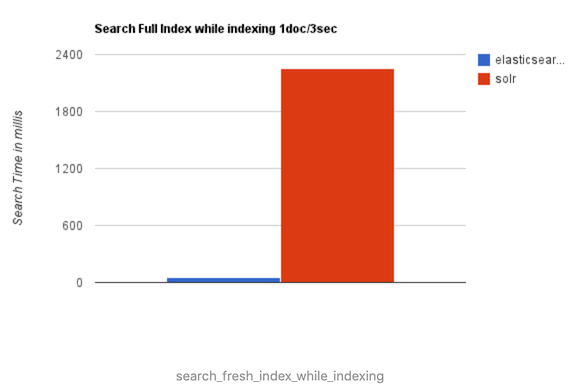
综上所述,Solr的架构不适合实时搜索的应用,而ES更适合
4、实际生产环境测试
下图为将搜索引擎从Solr转到Elasticsearch以后的平均查询速度有了50倍的提升。
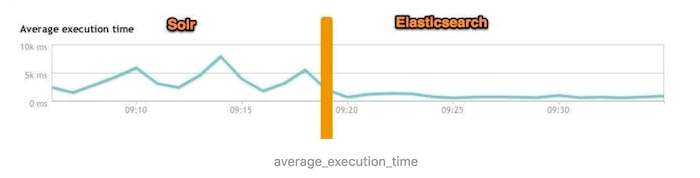
小结:
1、ES开箱即用,Solr相对复杂一点
2、Solr需要独立部署在tomcat上,可以实现集群和分片,自身不支持集群结构,需要zookeeper来进行集群的支持提供服务注册,进行分布式索引查询,也是可以自己实现故障转移的(3组节点,每组2个solr,互为主从),ES自带集群管理,分布式搜索。
3、Solr支持的数据格式XML、JSON,ES仅支持JSON
4、Solr官方提供的功能更多,ES注重核心功能,拥有良好的插件机制,高级功能可以使用第三方插件。
5、Solr对已有数据查询更快,索引更新时查询很慢,ES建立索引快,实时查询比较快
6、Solr生态和用户较大,ES相对来说较少,ES版本更新快,很多人还在用旧版本6.x
ES的核心概念
Lucene是一个Java语言开发的开源全文检索引擎工具包,用Netty封装成服务,使用JSON访问就是ES了。
ES内置了分布式集群(多节点)和分布式索引(数据分片)的管理。使用ES的搜索系统管理架构图如下:
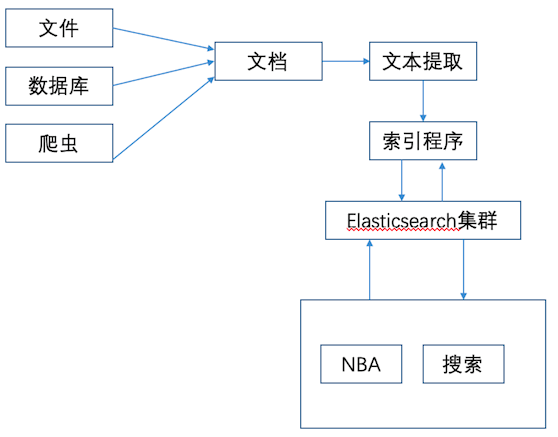
核心术语:
1、索引index
ES将数据存储到索引中,用sql领域的术语来类比,索引就像数据库,可以向索引写入文档和读取文档,索引是具有某些类似特征的文档集合。
2、文档document
ES索引中一条一条的数据,相当于数据库表里的一行一行的数据
3、映射Mappings
相当于表结构定义,定义字段内容信息
4、类型type
文档的类型(分组),允许一个索引存储多种文档类型,7.x版本后默认为doc。
ES6.x,一个文档只能包含一个映射类型
ES7.x,映射类型默认是_doc,
ES8.x,将完成删除type
5、节点node
单个ES服务实例称为节点,很多时候部署一个ES节点就足以应付大多数简单应用,但是考虑到容错性和数据的膨胀,单机无法应用这些状况。
6、集群cluster
集群是一组具有相同cluster.name的节点集合,集群状态通过绿、黄、红来标识
- 绿色,一切都很好,集群功能齐全
- 黄色,所有数据均可用,但尚未分配一些副本
- 红色,某些数据由于某种原因不可用,集群功能不齐全,这个时候要尽快修复
7、分片shard
-
数据分片的概念,需要进行水平扩展服务节点只需要加入新的机器到集群中即可,允许分片跨节点分布,从而提供性能和吞吐量。
-
集群的每个数据节点都是HA的
主分片:承担数据写入访问的作用
replica备份分片:除了做备份以外,还承担了读数据的水平负载作用(可执行搜索),创建索引时要定义正确数量的分片和副本分片。创建索引后,也可以动态更改副本分片数。
8、NRT (Near Real Time)
ES中新的文档(doc)被加入后可查询的时间间隔非常微弱,接近实时
| Mysql | ES |
|---|---|
| 数据库(database) | 索引(index) |
| 表(table) | types (7.x后默认为doc) |
| 行(rows) | 文档(documents) |
| 字段(columns) | 字段(fields) |
物理设计,一个集群至少包含一个节点,一个节点就是一个es进程,节点可以有多个索引,如创建一个索引
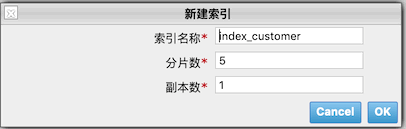
这个索引有5个主分片,每个主分片有一个副本分片,分布在不同的节点内,某个节点挂了,数据也不至于丢失

安装ES
去官网下载,也可以用docker安装,这里我使用第一种方式
windows安装
1、解压安装包即可使用
bin: 启动文件
config: 配置文件
log4j: 日志配置
jvm: java虚拟机的配置
es.yml: es的配置文件
lib: 相关类库jar包
logs: 日志
modules: 功能模块
plguins: 放置插件使用,如ik中文分词器,拼音分词器
2、由于ES默认占有的内存资源很大,所以需要修改jvm参数

3、双击启动即可

4、查看启动日志

启动时会加载模块
5、访问 http://localhost:9200
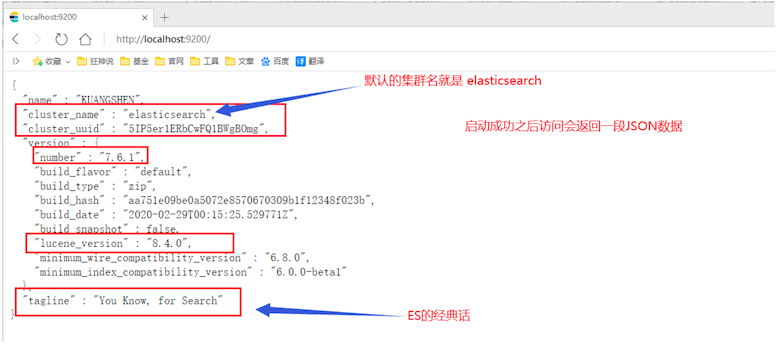
linux安装
# linux下,不能用root启动es,所以我直接创建一个用户esuser来安装es
[root@helloworld ~]# adduser esuser
# 下载
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.6.1-linux-x86_64.tar.gz
# 1、切换esuser,上传ElasticSearch到服务器,解压
[root@helloworld ~]# su esuser
[esuser@helloworld ~]$ pwd
/home/esuser
[esuser@helloworld ~]$ rz
[esuser@helloworld ~]$ tar -zxvf elasticsearch-7.6.1-linux-x86_64.tar.gz
[esuser@helloworld elasticsearch-7.6.1]$ mkdir data
# 2、修改配置文件,注意留空格
[esuser@helloworld config]$ vi elasticsearch.yml
cluster.name: jude-es # 给集群设置一个名字,如果是集群,所有在这个集群中的节点集群名都要一样
node.name: es-node-1 # 如果是集群,集群中每个节点的名字都不能一样
path.data: /home/esuser/elasticsearc-7.6.1/data
path.logs: /home/esuser/elasticsearc-7.6.1/logs
network.host: 0.0.0.0 # 不限制ip访问 ES,生产环境应该要设置可以访问的ip
http.port: 9200 # 访问 服务端口,节点通信的端口是9300
cluster.initial_master_nodes: ["es-node-1"] # master节点服务发现,和上面的节点名一致
# 改小java的堆内存,这个自己设置,默认是1g内存
[esuser@helloworld config]$ vi jvm.options
-Xms512m
-Xmx512m
# 3、修改sysctl.conf文件,需要切回root用户
[root@helloworld bin]# vi /etc/sysctl.conf
vm.max_map_count=262145
# 修改后刷新生效
[root@helloworld bin]# sysctl -p
# 修改 /etc/security/limits.conf,文件尾部添加
[root@helloworld ~]# vi /etc/security/limits.conf
esuser soft nofile 65536
esuser hard nofile 65536
esuser nproc 2048
esuser nproc 4096
# 4、启动,需要使用esuser用户,到elasticsearch的bin目录下执行
[esuser@helloworld bin]$ ./elasticsearch # 先在线启动确认没有报错
[esuser@helloworld bin]$ ./elasticsearch -d # 后台启动
安装 ES Head
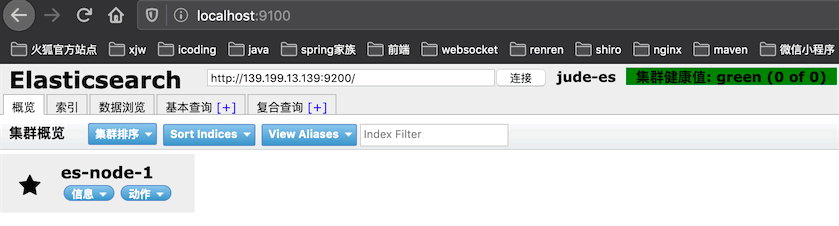
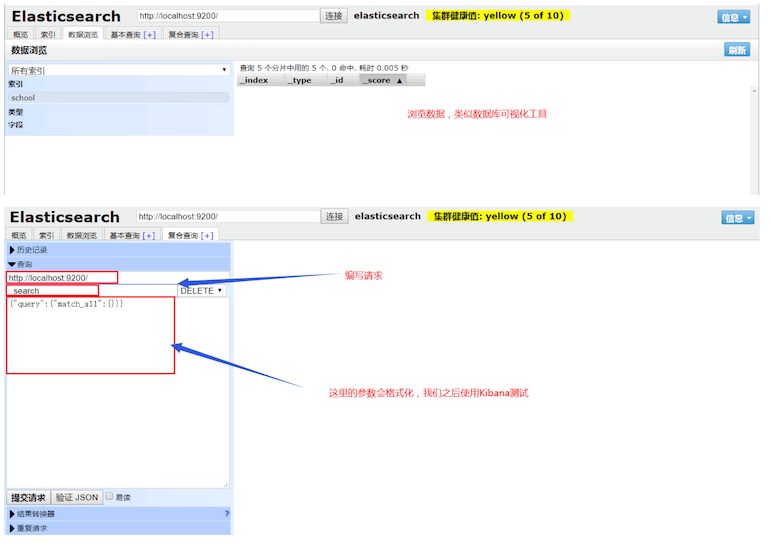
ES本身没有界面控制,我们使用第三方工具来测试查看
elasticSearch-head 需要nodejs环境,在自己本机安装就行了
下载地址:https://github.com/mobz/elasticsearch-head
Running with built in server
git clone git://github.com/mobz/elasticsearch-head.git
cd elasticsearch-head
npm install
npm run start
open http://localhost:9100/
配置ES的可以跨域访问
# 在elasticsearch.yaml里加入
http.cors.enabled: true
# 开放所有ip访问,线上这样设置不安全,建议head与elasticsearch在同一台服务器上
http.cors.allow-origin: "*"
# 重启elasticsearch
连接成功
ES设置用户密码访问
# 1、修改配置文件,开启x-pack验证
[esuser@helloworld config]$ vi elasticsearch.yml
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: Authorization
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
# 2、
2、倒排索引
ES使用的是一种倒排索引的结构,
Redis在查询的时候:key-value?是通过key来找到的value,是否可以通过value来找key?通过value找到和这个value相似度极高的内容?不可以,所以需要全文搜索引擎,引出倒排索引概念
倒排索引(Inverted Index):比如通过歌词来查歌名,通过内容检索名称,而这个名称在系统中其实就是一个索引,通过歌来找歌词这是正排索引
比如拿课程学习举例:
文档编号 文档内容
1 艾编程架构师之路
2 艾编程Java成长之路 (分词:艾编程 Java 成长 之路)
3 ES成长学习入门
搜索的分词 这个分词在哪个文档中出现 文档编号:次数:位置
成长 2,3 2:1:<3>,3:1:<2>
ES的索引流程:建立索引->分片->集群中不同的节点上,每个分片还有一个副本分片。
每个分片保存了一些倒排索引词条->词条对应的文档记录
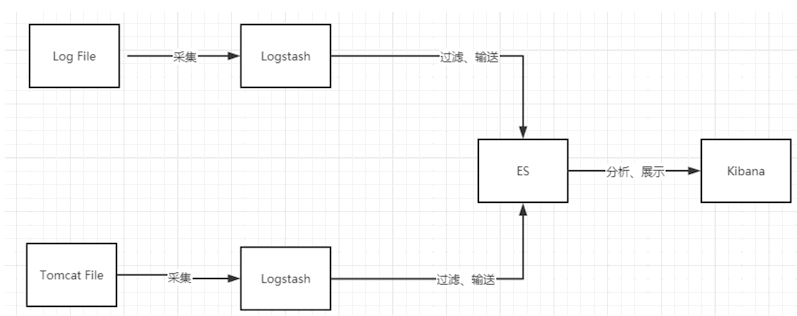
3、ELK
ELK是三个技术的总和(ElasticSearch、Logstash、Kibana)
ElasticSearch 是一个基于Lucene、分布式、通过Restful Api进行交互的实时搜索平台
Logstash 是ELK的中央数据流引擎,作用是将收集不同的数据(文件、数据库、MQ),需要通过它过滤
Kibana 将这些数据进行可视化的展示出来,提供实时分析功能
安装Kibana
官网地址:https://www.elastic.co/cn/downloads/kibana
ES和Kibana的版本必须一致window安装
下载后直接解压
启动

linux安装
# es 和 kibana放在同一目录下,也不能root用户启动kibana
[esuser@helloworld ~]$ ls
elasticsearch-7.6.1 kibana-7.6.1-linux-x86_64.tar.gz
# 1、解压
[esuser@helloworld ~]$ tar -zxvf kibana-7.6.1-linux-x86_64.tar.gz
# 改名字
[esuser@helloworld ~]$ mv kibana-7.6.1-linux-x86_64 kibana-7.6.1
# 2、修改kibana的yaml配置,
[esuser@helloworld config]$ cd kibana-7.6.1
[esuser@helloworld config]$ vi kibana.yml
server.port: 5601 # 默认端口5601,可以不修改
server.host: "0.0.0.0" # 开放ip访问,默认localhost
elasticsearch.hosts: ["http://localhost:9200"] # es实例节点,默认localhost:9200
i18n.locale: "zh-CN" # 汉化
# 3、启动,cd到kibana的bin目录
[esuser@helloworld bin]$ ./kibana # 在线运行
nohup kibana > kibana.log 2>&1 & # 后台运行
# 注意,云服务器防火墙和安全组要开放5601端口,
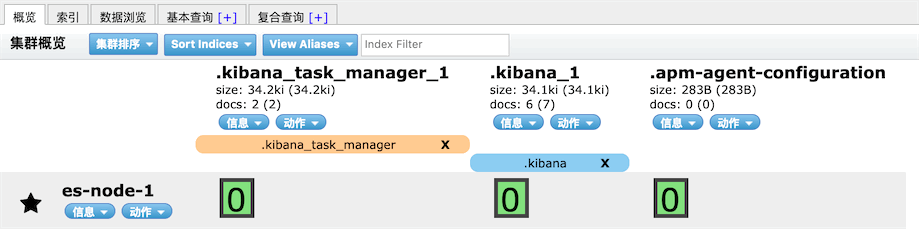
启动后,ES会多了几个kibana的索引

访问:http://localhost:5601/app/kibana#/home

开放工具
建一个索引,包含数据
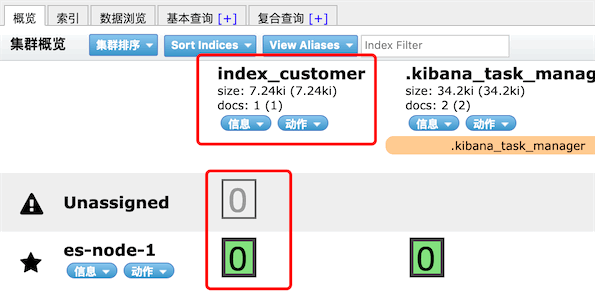
查看elasticsearch-head,多了一个索引index_customer

4、IK中文分词器
分词:将一个完成的词或者语句,拆分为一个一个关键字(词条),搜索的时候就会进行关键字查找搜索。其实ES在添加文档的时候,就会对文档内容按指定的分词器进行拆分了。
安装
要与ES版本对应github地址: https://github.com/medcl/elasticsearch-analysis-ik/releases
window安装
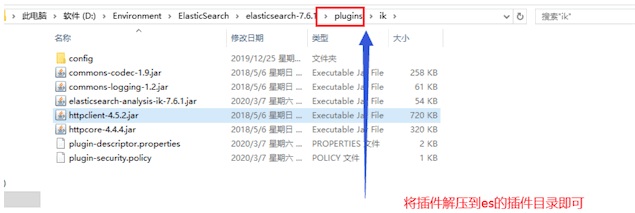
1、解压到es插件目录中
2、重启ES观察是否加载成功
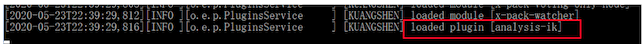
# 通过命令查询
[esuser@helloworld bin]$ ./elasticsearch-plugin list
ik
linux安装
#安装unzip
yum -y install unzip
# 1、下载完解压到elasticsearch的plugin/ik目录下
[esuser@helloworld ~]$ unzip elasticsearch-analysis-ik-7.6.1.zip -d /home/esuser/elasticsearch-7.6.1/plugins/ik
[esuser@helloworld ~]$ cd elasticsearch-7.6.1/plugins/ik
[esuser@helloworld ik]$ ls
commons-codec-1.9.jar config httpclient-4.5.2.jar plugin-descriptor.properties
commons-logging-1.2.jar elasticsearch-analysis-ik-7.6.1.jar httpcore-4.4.4.jar plugin-security.policy
# 2、重启elasticsearch
# 新增分词器后,先加的记录是不能被匹配出来的,要后加的记录才能匹配,因为文档在新增的时候就进行了分词,可以重建索引,对所有的文档记录重新分词,但相对会损耗些资源。
使用kibana测试ik分词器
ik分词器提供了两种算法:
-
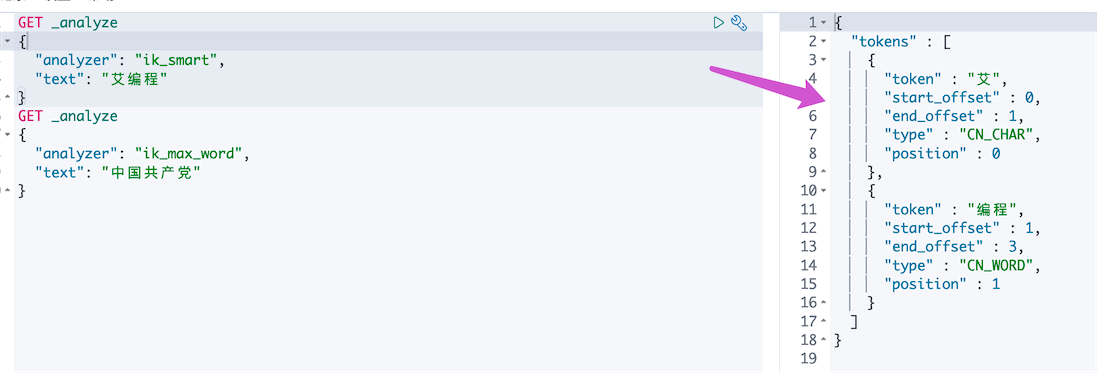
ik_smart 最少切分,发现只有一个词
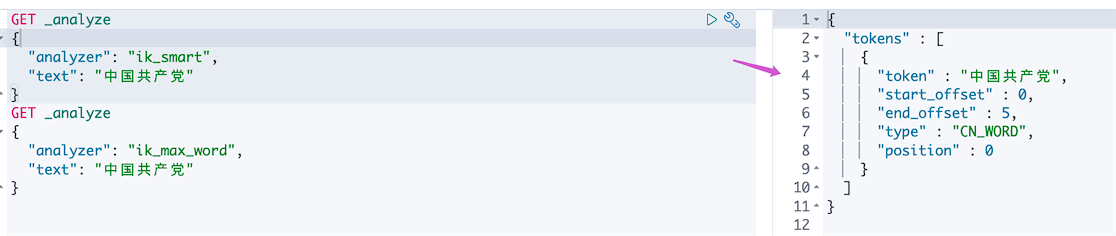
在ik分词器的词库里,“中国共产党”是一个词,所以就可以最少拆分出一个词来,但是”艾编程”并不在ik分词器的词库里,也就是说它不是一个词,所以拆分出“艾”和“编程”两个词(最少)。怎么把“艾编程”当做一个词,自定义词库。
-
Ik_max_word 最细粒度划分,穷尽词库
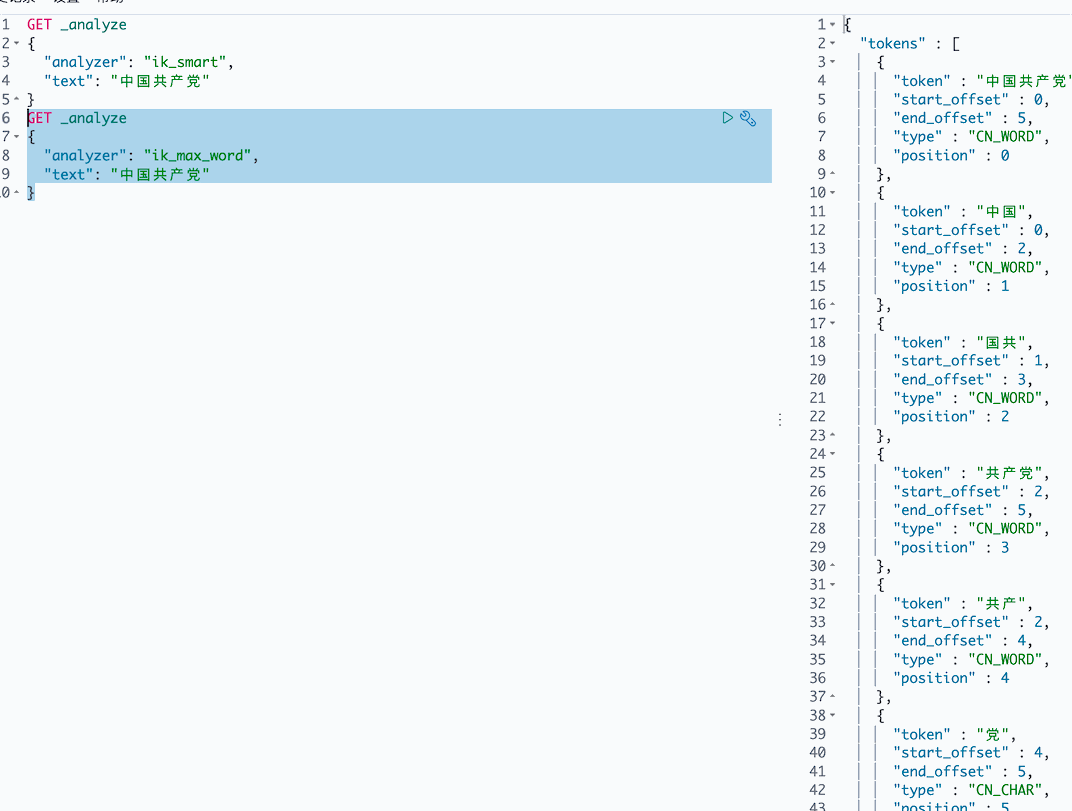
自定义词库
在ik分词器的配置中ik/config,有很多dic文件,保存了大量的关键字(词条),就是拆分的依据

点击其中一个看看

可以看到很多个词语。
1、定义自己的.dic,然后放入自己的词
[esuser@helloworld config]$ vi my.dic
# 添加 “艾编程”
[esuser@helloworld config]$ cat my.dic
艾编程
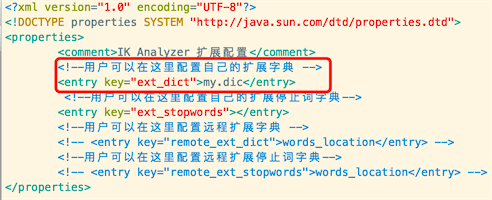
2、配置到IKAnalyzer.cfg.xml中
3、重启ES,测试“艾编程”
[esuser@helloworld config]$ ps -ef|grep elastic
[esuser@helloworld config]$ kill
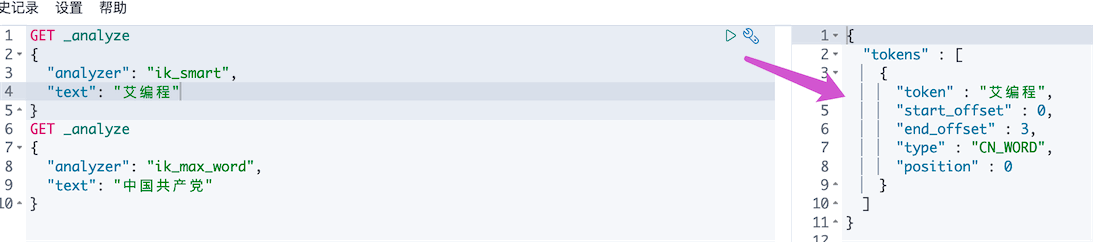
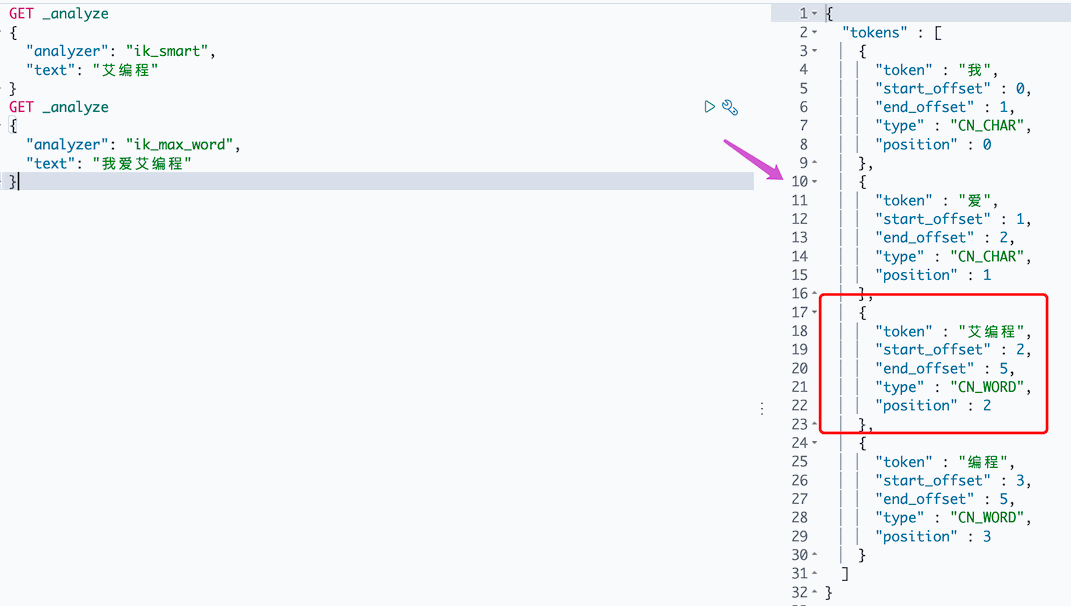
发现“艾编程”已是一个可识别的词了。
5、基础操作
Rest风格
| Method | url风格 | 描述 |
|---|---|---|
| PUT/POST | localhost:9200/索引/类型名称/文档id | 创建文档(指定id) |
| POST | localhost:9200/索引/类型名称 | 创建文档(随机id) |
| POST | localhost:9200/索引/类型名称/文档id/_update | 修改文档 |
| DELETE | localhost:9200/索引/类型名称/文档id | 删除文档 |
| GET | localhost:9200/索引/类型名称/文档id | 通过id查询文档 |
| POST | localhost:9200/索引/类型名称/文档id/_search | 查询所有数据 |