 弹吉他的兔子
弹吉他的兔子
1. 数据的切分实现方式
简单来讲,就是讲存放在一台数据库上的数据分布到多台数据库上,形成了一个分布式数据库,大致我们数据的拆分方式分为两种
1.1. 垂直切分
常用于我们的微服务设计中,不同的业务领域存放不同的表,比如用户模块存放我们用户相关表,外部调用通过服务访问用户模块,用户模块再去访问对应的数据库
跨库来实现我们数据的join连接,就会导致查询性能极大的下降
垂直切分的优缺点
优点
- 拆分后业务更清晰,规则明确
- 系统之间耦合降低,便于扩展
- 数据维护简单
缺点
-
部分业务表无法join,只能通过接口调用,提升了系统的复杂度
-
跨库事务处理是个问题(2PC,程序端解决2PC,阿里的seata 解决分布式事务)
-
垂直切分以后,某些业务数据依旧庞大,依然会存在单体性能瓶颈
1.2. 水平拆分
明确的id查询是通过表的存入规则来进行匹配,如果是范围查询,将数据在两个表都进行查询然后进行业务合并,如在A表,B表查询完后结果进行一个排序,再返回相应数据量的结果,ElasticSearch的分片查询底层也是如此的原理。
优点
- 解决了单库大数据,高并发的问题,实现数据的分布式
- 拆分规则只要封装好,开发人员不用考虑拆分细节
- 提升了系统的稳定性和负载能力
缺点
-
拆分规则不太好抽象
-
分布式事务一致性不好解决
-
二次扩展的时候、数据迁移、维护难度都比较大
1.3. 整体方案总结
垂直和水平都要面临的问题(一定是先垂直后水平)
- 分布式事务问题
- 跨库join问题
- 多数据源的问题
- 拆分合并的问题
针对多数据源的管理问题,主要有两种思路
1、客户端模式:只要需要配置好底层的数据源,然后在程序上直接访问即可
2、中间代理模式:由中间代理管理所有数据源,开发人员完全不用关心底层数据源是什么,在哪里,开发人员不用关系拆分规则
基于这两种模式对应的成熟的第三方中间件
-
中间代理模式:MyCat
(相当于一个分布式数据库,而我们的MySQL只是他的一个存储仓库)
- 客户端模式:sharding-jdbc(统一的数据源,由他管理不同的数据链接)
2. MyCat的内部逻辑
1、逻辑库(Schema)将分开的物理库合并的一个逻辑数据库
2、逻辑表(table)逻辑表就是物理表的总和,Mycat中看到的表就是逻辑表
只要进行了水平切分就是一个分片表,没有切分的就是非分片表
通过冗余方式复制到所有分片表所在库的表就叫全局表
3、分片节点(dataNode)数据表被分片到不同的分片数据库上,每个分片表所在的库就叫数据节点
4、分片主机(dataHost)所有分片数据实际存放的物理数据库
5、分片规则(rule)MyCat有很多分片规则,基本够用,自己本身是用Java开发的
6、全局序列号- UUID 不建议,因为它不能进行索引组织,uuid无序
- Snow ID 雪花算法
3. MyCat安装使用
mycat简介
mycat学习文档:www.mycat.org.cn/document/mycat-definitive-guide.pdf
什么是mycat
-
一个彻底开源的,面向企业应用开发的大数据库集群
-
支持事务、ACID、可以替代MySQL的加强版数据库
-
一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群
-
一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server
-
结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品
-
一个新颖的数据库中间件产品
目标
低成本的将现有的单机数据库和应用平滑迁移到“云”端,解决数据存储和业务规模迅速增长情况下的数据瓶颈问题。
最新版本1.6架构
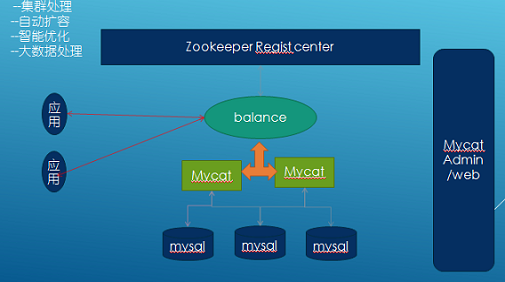
这是MyCat的物理结构,MyCat本身是不存储数据的
每个mysql就是一个分片数据库,合起来才是一个完整的数据,像redis的集群,elasticsearch的分片一样道理,合起来才是所有的数据。
mysql的分库与mysql的分区表在思想上也有一些相同之处,分区表就是把数据切开到不同的文件(一个mysql数据库),分库就是mysql集群,将数据切开放到不同的mysql数据库上。
也可以在每个mysql分库上做主从
2.0规划
-
完全实现分布式事务,完全的支持分布式。
-
通过Mycat web(eye)完成可视化配置,及智能监控,自动运维。
-
通过mysql 本地节点,完整的解决数据扩容难度,实现自动扩容机制,解决扩容难点。
-
支持基于zookeeper的主从切换及Mycat集群化管理。
-
通过Mycat Balance 替代第三方的Haproxy,LVS等第三方高可用,完整的兼容Mycat集群节点的动态上下线。
-
接入Spark等第三方工具,解决数据分析及大数据聚合的业务场景。
-
通过Mycat智能优化,分析分片热点,提供合理的分片建议,索引建议,及数据切分实时业务建议。
docker安装mysql
由于我只有一台云服务器,所以使用docker安装多个mysql实例做测试,生成环境下必须一台服务器一个mysql
# 自定义一个mysql集群网络
[root@alibaba ~]# docker network create --subnet 172.18.0.0/16 --gateway 172.18.0.1 mysql-net
# mysql的配置文件挂载: /opt/mysql213/conf
# mysql的数据存储目录挂载: /opt/mysql213/data
# mysql的日志文件目录挂载: /opt/mysql213/logs
[root@alibaba mysql-slave]# docker run -d -p 3306:3306
-v /opt/mysql213/conf:/etc/mysql/mysql.conf.d
-v /opt/mysql213/data:/var/lib/mysql
-v /opt/mysql213/logs:/var/log/mysql
--net mysql-net --ip 172.18.0.213
-e MYSQL_ROOT_PASSWORD=mysql123456 --name mysql213 mysql:5.7.30
# 再安装另一个mysql实例
[root@alibaba mysql-slave]# docker run -d -p 3307:3306
-v /opt/mysql214/conf:/etc/mysql/mysql.conf.d
-v /opt/mysql214/data:/var/lib/mysql
-v /opt/mysql214/logs:/var/log/mysql
--net mysql-net --ip 172.18.0.214
-e MYSQL_ROOT_PASSWORD=mysql123456 --name mysql214 mysql:5.7.30
mycat安装
# 需要提前安装两个数据库:这两个数据库是独立,不能是主从关系
# 0.下载mycat
wget http://dl.mycat.org.cn/1.6.7.3/20190927161129/Mycat-server-1.6.7.3-release-20190927161129-linux.tar.gz
# 1、解压
tar -xvf Mycat-server-1.6.7.3-release-20190927161129-linux.tar.gz
# 2、Mycat依赖java,服务器要先安装好java环境
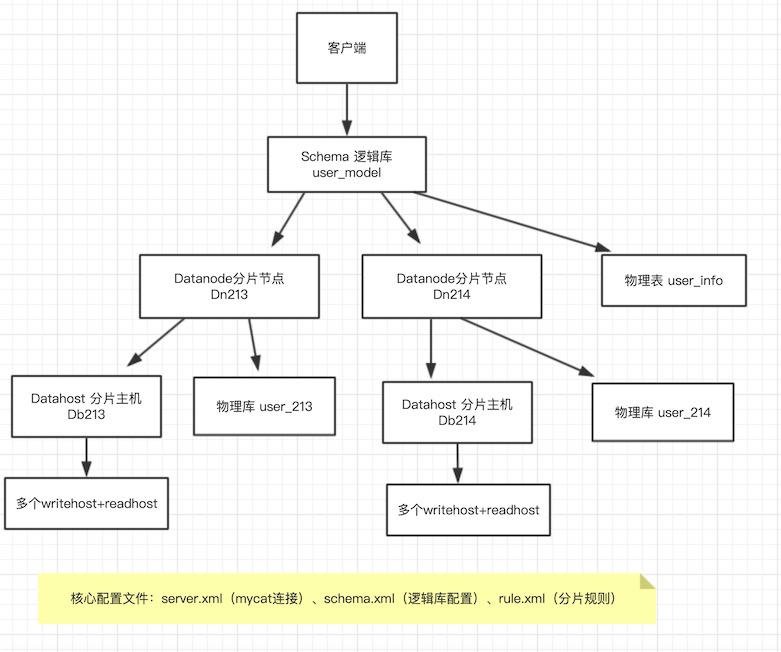
使用mycat 搭建一个简单的mysql集群做数据切分,架构图如下:
进入server.xml我们去到底部先看用户权限
1、配置server.xml
cd /opt/mycat/conf
vi server.xml
先配置mycat的连接逻辑库的用户
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">user_module,cart_module,product_module</property> 连接的逻辑库,可以多个
</user>
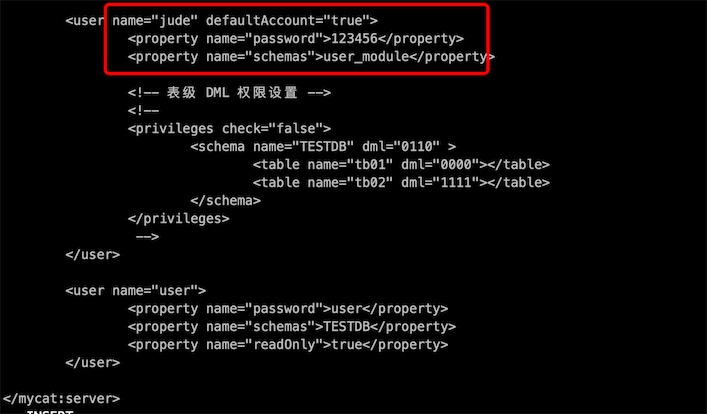
2、配置逻辑库:schema.xml
先配置两个物理主机 dataHost,就是配置两个mysql数据库的物理机信息
<dataHost name="DB213" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="M1" url="192.168.0.213:3306" user="gavin"
password="123456">
</writeHost>
</dataHost>
<dataHost name="DB214" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="M1" url="192.168.0.214:3306" user="gavin"
password="123456">
</writeHost>
</dataHost>
一个dataHost下可以有多个writeHost和readHost,但是mycat只会选择一个writeHost写入数据,所以两个writeHost之间要做双主互备,保证一个writeHost 宕机了,另外一个writeHost数据是完整的。
配置dataNode的数据节点,这里的database是我们的物理存放数据的数据库名
<dataNode name="dn213" dataHost="DB213" database="user_213" />
<dataNode name="dn214" dataHost="DB214" database="user_214" />
配置schema节点,schema节点的name是server.xml里配置逻辑库名,要对应
table节点里配置的name是物理数据库存放的实际表名,rule就是分片规则
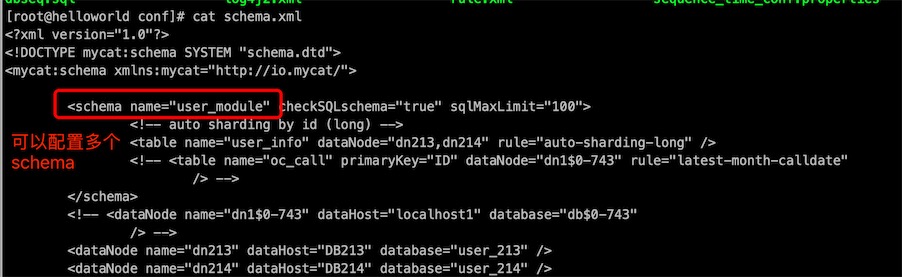
<schema name="user_module" checkSQLschema="true" sqlMaxLimit="100">
<!-- auto sharding by id (long) -->
<table name="user_info" dataNode="dn213,dn214" rule="auto-sharding-long" />
</schema>
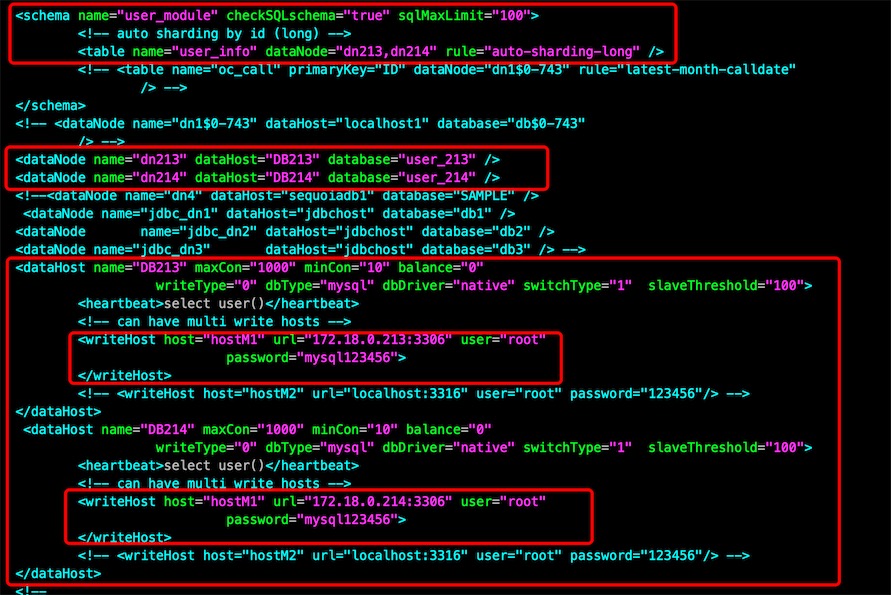
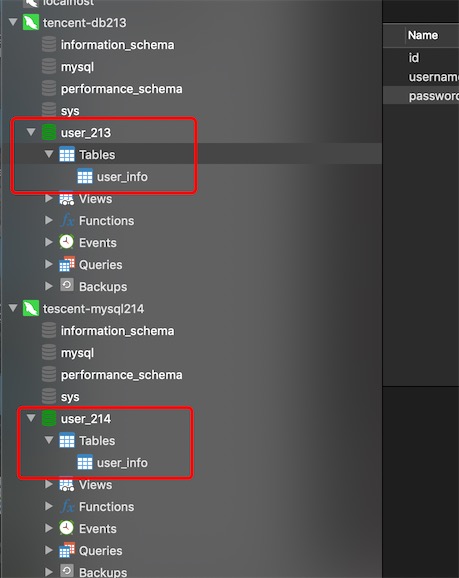
3、现在去两个物理数据库创建两个库user_213,user_214和两个表user_info,id不能自增,使用雪花算法自定义
CREATE TABLE `user_info` (
`id` int(11) DEFAULT NULL,
`username` varchar(255) DEFAULT NULL,
`password` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
4、启动MyCat
# mycat根目录下启动
[root@helloworld bin]# pwd
/opt/mycat/bin
[root@helloworld bin]# ./mycat --help
Usage: ./mycat { console | start | stop | restart | status | dump }
# 控制台输出
[root@helloworld bin]# ./mycat console
# 报错
jvm 1 | Caused by: io.mycat.config.util.ConfigException: Illegal table conf : table [ USER_INFO ] rule function [ rang-long ] partition size : 3 > table datanode size : 2, please make sure table datanode size = function partition size
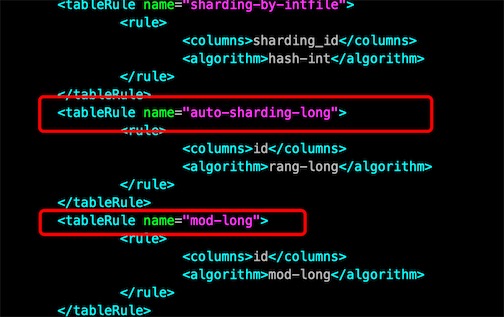
查看schema.xml,分片规则是”auto-sharding-long”
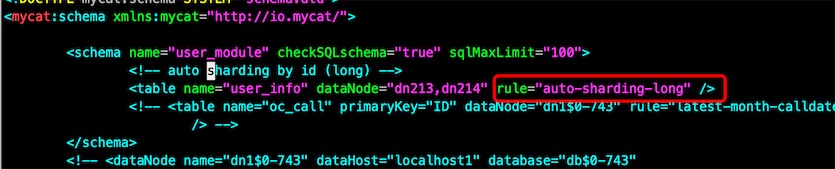
在conf/rule.xml根据分片规则去找具体的分片策略
[root@helloworld conf]# vim rule.xml
# 找到这个规则 auto-sharding-long
# columns 物理表的列名,根据这个id列进行数据切分,分到不同的dataNode
# algorithm 分片策略 rang-long,范围long值
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
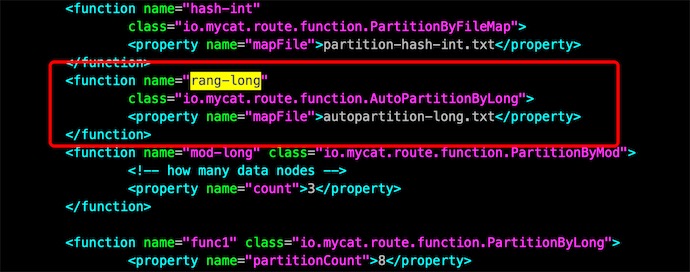
# 在conf/rule.xml 搜索 rang-long,它是一个function,有一个属性文件autopartition-long.txt,里面就是一下策略的配置
<function name="rang-long"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
# 修改策略配置
[root@helloworld conf]# vi autopartition-long.txt
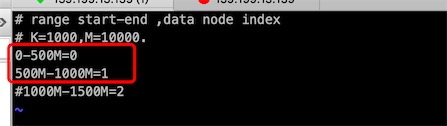
# range start-end ,data node index
# K=1000,M=10000.
0-500M=0
500M-1000M=1
#1000M-1500M=2
# K=1000 (千),M=10000 (万)
# 需要根据dataNode设置节点数,0,1,2说明有三个节点,但实际上我们只陪配置dn213,dn214两个节点,所以只配0,1两个节点
# 按顺序,0就是dn213,1就是dn214
再次启动
# 控制台输出
[root@helloworld bin]# ./mycat console
再次报错

修改 server.xml,注释TESTDB
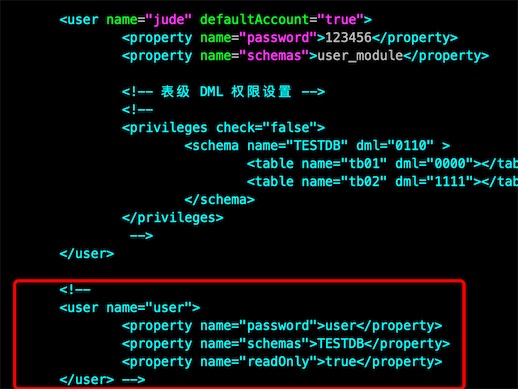
启动成功

5、连接mycat,查看server.xml发现它的服务端口是8066,管理端口是9066

使用Navicat 创建mysql连接Mycat,用户就是上面server.xml的配置的
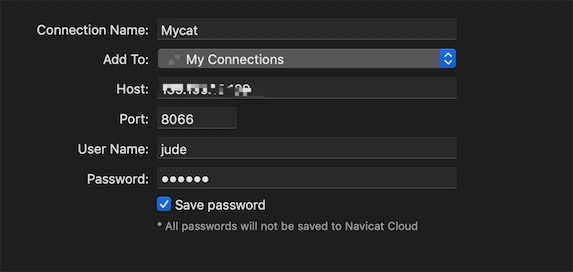

mycat测试
修改一下autopartition-long.txt,
# id 0-500的数据分到分片0上,501-100的数据分到分片1上
[root@helloworld mycat]# vi conf/autopartition-long.txt
0-500=0
500-1000=1
# 重启mycat
[root@helloworld mycat]# ./bin/mycat console
在Mycat的连接中,逻辑表user_info 插入数据
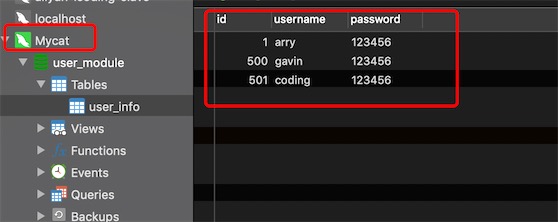
发现id为1和500两条记录切分到物理库user_213上
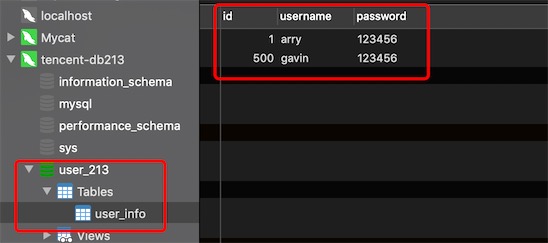
发现id为501的记录切分到物理库user_214上
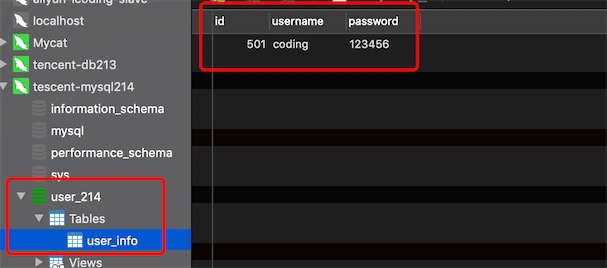
超过id为1000的数据是无法写入的,因为找不到有效的分片节点dataNode,需要配置DEFAULT
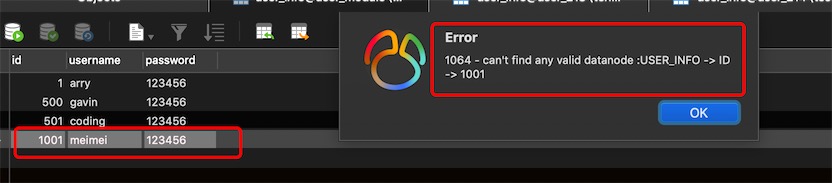
4. MyCat分库分表配置
4.1. server.xml
作用:配置MyCat用户名,密码,权限,Schema关系
如果一个用户下有多个Schema就以csv格式(逗号分隔)来写入
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">user_module,cart_module,product_module</property>
</user>
多个schema就需要在schema.xml里配置多个组schema
# 命令行连接-p 是密码,-P是端口,就像平常mysql数据库一样使用
[root@alibaba ~]# mysql -ujude -p -h139.199.13.139 -P8066
mysql> show databases;
+-------------+
| DATABASE |
+-------------+
| user_module |
+-------------+
1 row in set (0.00 sec)
mysql> use user_module;
mysql> select * from user_info
-> ;
+-----+----------+----------+
| id | username | password |
+-----+----------+----------+
| 1 | arry | 123456 |
| 500 | gavin | 123456 |
| 501 | coding | 123456 |
+-----+----------+----------+
对于我们的开发人员, mycat的底层分片规则根本不用关心, 完全可以当作一个数据库来使用,只是它实现了分布式。
4.2. schema.xml
- 配置dataHost,包括写host和读host
- 配置dataNode,指定具体的数据库,如user_213,user_214
- 配置schema,表名,数据节点,分片规则
dataHost节点
<dataHost name="DB214" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
# name:主机名,自己命名即可
# maxCon:最大连接
# minCon:最小链接
# dbDriver: native,不用自己配置数据库驱动类
# balance:负载均衡策略,值有4个
# 1、balance="0",不开启读写分离,所有的操作都在writeHost上操作
# 2、balance="1",全部的readHost与stand by writeHost(第2个,第3个writehost)参与select数据的负载均衡
# 3、balance="2" 所有的读操作随机分发到全部writeHost和全部readHost
# 4、balance="3" 所有的读操作随机分发到readHost,全部writeHost不参与读操作
双主也需要我们自己进行replica,mycat平时只写入一个主机
# writeType 写数据类型
# 1、writeType="0",所有写操作都会发送到配置的第一个writeHost,如果第一个挂了就会自动切到第二个writeHost配置上
# 2、writeType="1",所有的写操作会随机到writeHost上,1.5版本后不推荐
# switchType 切换类型配套我我们的writeType来进行操作的
# -1 表示写操作不自动进行切换
# 1 默认值,自动切换,从第一个到第二个writeHost
# 2 基于MySQL的主从同步的状态决定是否切换,如果从库是延时复制的话那mycat就暂时切换,此writehost1挂了,就不能写入数据
dataNode节点
<dataNode name="dn213" dataHost="DB213" database="user_213" />
# name:节点名
# dataHost:对应dataHost的名字
# database:是物理数据库的名称
schema节点
<schema name="user_module" checkSQLschema="true" sqlMaxLimit="100">
<table name="user_info" dataNode="dn213,dn214" rule="auto-sharding-long" />
</schema>
# name:在server配置里定义的逻辑库名
# checkSQLschema:如果是true会自动去掉数据库前缀
# sqlMaxLimit:为了减轻数据库压力,做的输出限制,默认限制100行
# sqlMaxLimit仅对分片表有效
# table name:物理表名
# rule就是分片规则
4.3. reloadConfig
看下启动命令
Usage: ./mycat { console | start | stop | restart | status | dump }
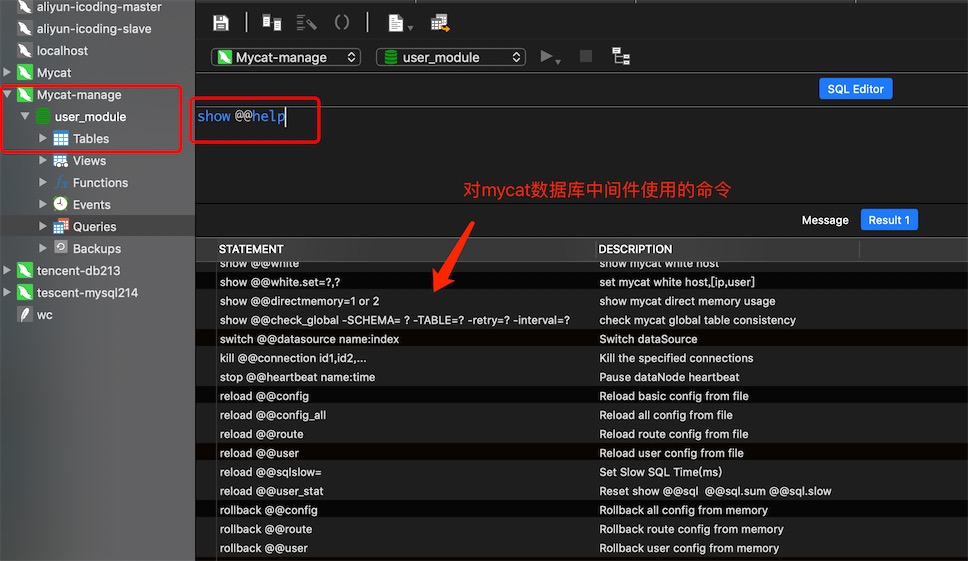
reload @@config; 修改完配置后不需要重启mycat
# 更改一些基本配置可以使用脚本操作
# 比如更改了limit就可以使用
reload @@config;
# 比如更新了数据源就需要通过config_all来进行操作了,但这里是更新所有配置,比较慢,需要多一点时间生效
reload @@config_all;
连接mycat的管理端
更新基本的配置
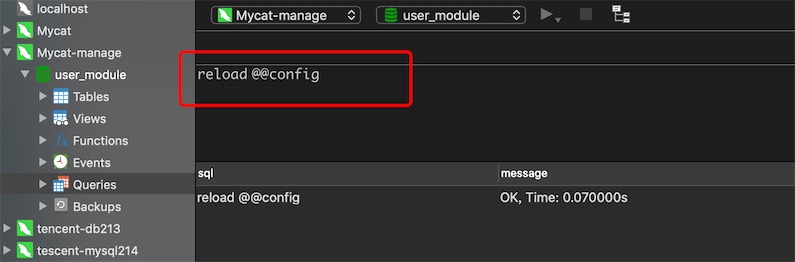
# 同样也可以通过命令行连接mycat管理端
[root@alibaba ~]# mysql -ujude -p -h139.199.13.139 -P9066
4.4. 模拟一个读写分离的操作
使用docker再安装一个mysql
[root@alibaba mysql-slave]# docker run -d -p 3308:3306
-v /opt/mysql211/conf:/etc/mysql/conf.d
-v /opt/mysql211/data:/var/lib/mysql
-v /opt/mysql211/logs:/var/log/mysql
--net mysql-net --ip 172.18.0.211
-e MYSQL_ROOT_PASSWORD=mysql123456 --name mysql211 mysql:5.7.30
1、创建物理库user_213,注意这里的数据库名一定要是user_213,因为数据分片节点dn213指定的物理库名就是user_213,db211作为读的分片主机一定要一个user_213的物理库,否则dn213无法完成读写分离了。
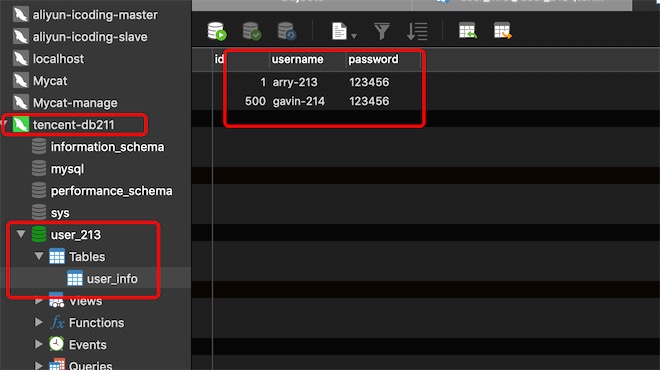
2、修改mycat的schema.xml,db211配置为readHost,注意要在writehost里面,
# 注意要修改balance
# 1、balance="0",不开启读写分离,所有的操作都在writeHost上操作
# 2、balance="1",全部的readHost与stand by writeHost(第2个,第3个writehost)参与select数据的负载均衡
# 3、balance="2" 所有的读操作随机分发到全部writeHost和全部readHost
<dataHost name="DB213" maxCon="1000" minCon="10" balance="2" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="M1" url="192.168.0.213:3306" user="gavin" password="123456">
<readHost host="S1" url="192.168.0.211:3306" user="gavin" password="123456"/>
</writeHost>
</dataHost>
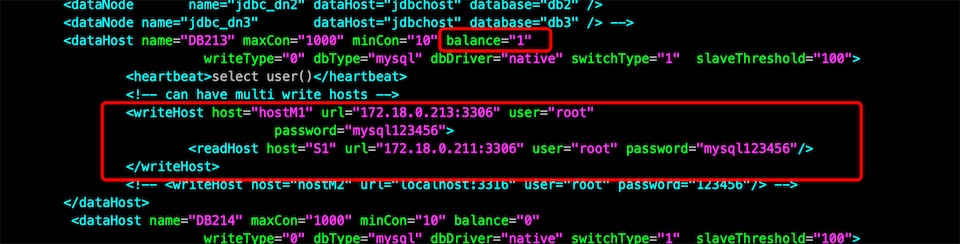
3、重新加载config配置或者重启mycat
mysql> reload @@config_all
现在db211是db213的从库,但是还没有主从复制,配置db211为readHost,且balance=1,说明Mycat会从db211读取数据,写数据则写到db213上
db213上user_213的数据
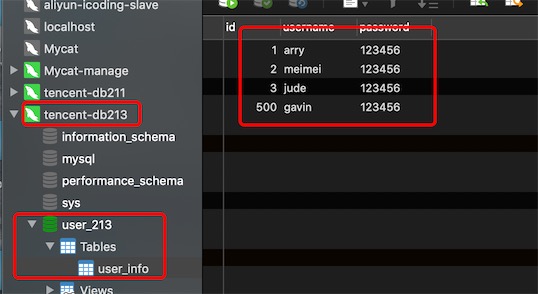
db211上user_213的数据
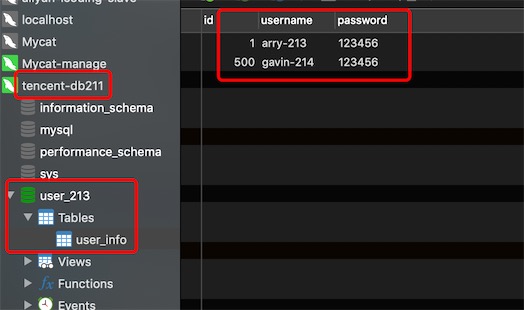
从mycat上的逻辑表user_info读取的数据
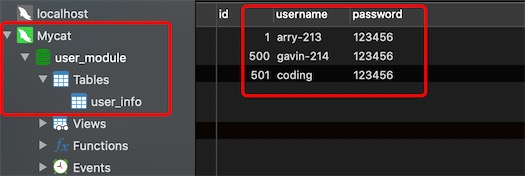
说明设置balance=1,全部的readHost与stand by writeHost(第2个,第3个writehost)参与select数据的负载均衡
如果设置balance=2,你会发现数据会随机从db211和db213的物理库user_213上读取的。
到这里,读写分离完成,db213应该和db211做主从复制,readHost和writeHost数据就保持一致了
4.5. 做一个双主的写操作配置
修改schema.xml,db211的物理库也配置为一个writeHost,writeType=”0”表示mycat的所有写操作都会选择在第一个writeHost上进行,模拟db213挂了,mycat会切换到db211上进行写操作
# 修改schema.xml
# balance 为1 会从readHost和satand by writeHost读取数据
<dataHost name="DB213" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="M1" url="192.168.0.213:3306" user="gavin" password="123456">
</writeHost>
<writeHost host="M2" url="192.168.0.211:3306" user="gavin" password="123456"/>
</dataHost>

# 重新加载所有配置,不用重启mycat
mysql> reload @@config_all
把db213挂了,尝试在mycat进行写操作

第一个writeHost挂了,mycat自动切换将数据被写入了第2个writeHost db211上
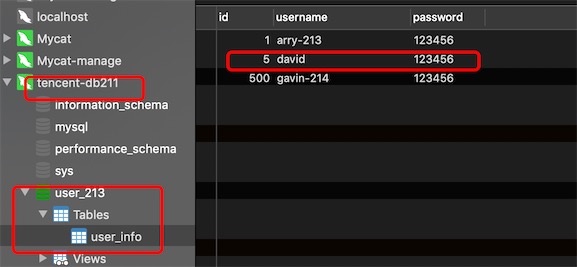
总结
你无论多少个writeHost都只是分片的一部分,mycat才是整体,下面多少writeHost都只是其中一个存储分片,一个数据一次只会写入一条,和writeHost多少没有关系,多个wirteHost,readHost都为了高可用,读写分离+热切换。
5. 作业
作业1:自己配置两个双主的writeHost,每个writeHost上挂载一个readHost
数据库切分架构图:
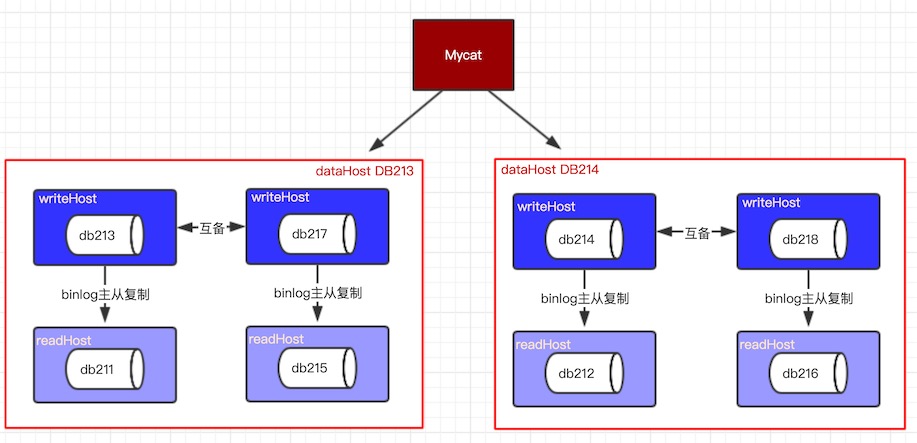
需要8个mysql实例数据库,我这里mysql实例都是使用docker安装的。
实验1: schema.xml的dataHost DB213配置如下
<dataHost name="DB213" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="172.18.0.213:3306" user="root" password="mysql123456">
<readHost host="S1" url="172.18.0.211:3306" user="root" password="mysql123456"/>
</writeHost>
<writeHost host="hostM2" url="172.18.0.217:3306" user="root" password="mysql123456">
<readHost host="S2" url="172.18.0.215:3306" user="root" password="mysql123456"/>
</writeHost>
</dataHost>
测试发现,db217成为了第一个writeHost,db213 是standby writeHost,banlacne=”1”,mycat会随机从db211,db215和db213上读取数据。
db213和db211已配置主从复制:
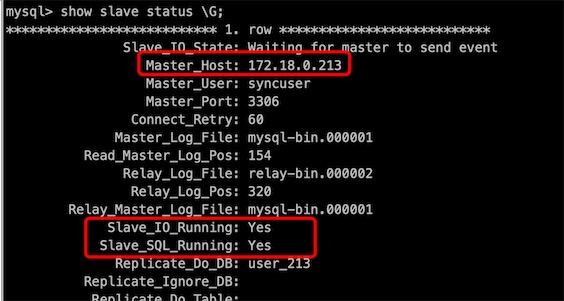
db217和db215已配置主从复制:
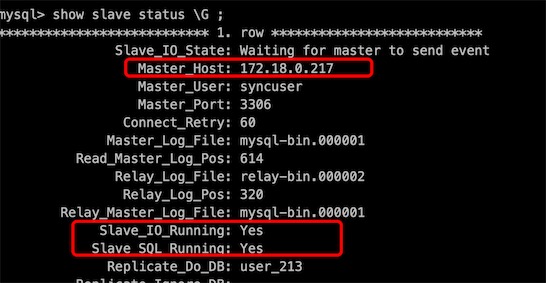
再测试发现,当db217挂了,mycat就会自动切换db213为第一个writeHost, 写操作会选择db213写入数据,然后db213通知db211复制自己的数据; mycat只会从db211读取数据,不再从db215读取。