弹吉他的兔子
弹吉他的兔子
5. MyCat的分片规则
在Mycat上修改逻辑表user_info 添加字段type,会自动同步到物理表的。
5.1. 枚举分片
修改 rule.xml 和 schema.xml
# 1、rule.xml
# columns对应我们的分片列名,要注意列名对应
<tableRule name="sharding-by-intfile">
<rule>
<columns>type</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
# 加入了默认的配置项
<function name="hash-int" class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
<property name="defaultNode">0</property>
</function>
# 2、数据分片节点匹配文件partition-hash-int.txt 枚举规则
vi partition-hash-int.txt
10000=0
10010=0
10020=0
10001=1
10011=1
10021=1
DEFAULT_NODE=0
# 3、修改schema.xml,分片策略为 sharding-by-intfile
<schema name="user_module" checkSQLschema="true" sqlMaxLimit="100">
<!-- 枚举分片-->
<table name="user_info" dataNode="dn213,dn214" rule="sharding-by-intfile" />
# 4、连接mycat的9066管理端,重新加载mycat的配置,
mysql> reload @@config_all;
枚举分片跟分区表的list分区是一样的,要注意三个点:
- 分片列名要与表的列名一致
-
要配置超出规则的默认数据分片节点 defaultNode
- 要修改修改schema逻辑库的逻辑表的分片规则rule
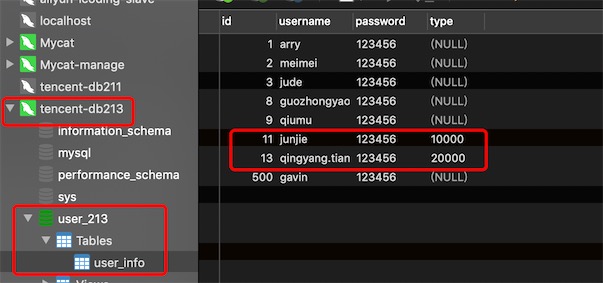
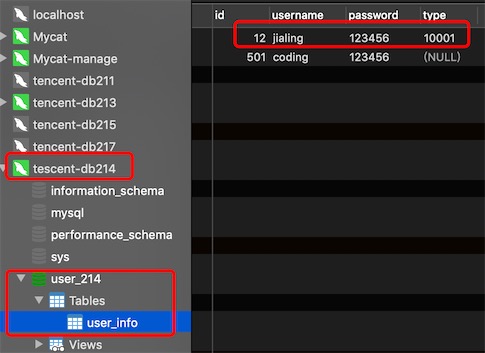
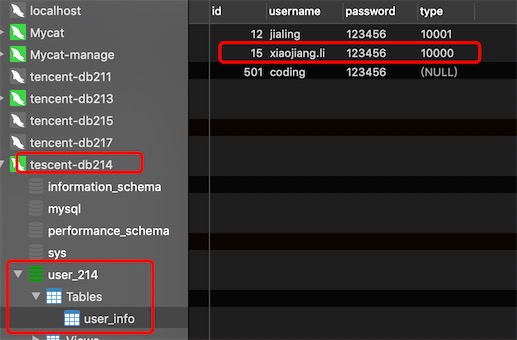
在mycat上插入三条数据type的值分别为:10000,10001,20000
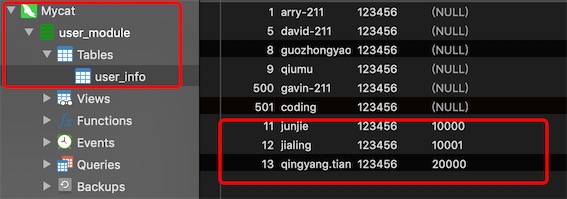
按照分片规则10000和20000分到了db213,10001分到了db214
5.2. 取模分片
修改 rule.xml 和 schema.xml
# 1、rule.xml
# 拿id做取模分片
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
# 根据节点数取模,我们现在有两个数据分片节点dataNode: dn213和dn214
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">2</property>
</function>
# 2、修改schema.xml,分片策略为mod-long
<schema name="user_module" checkSQLschema="true" sqlMaxLimit="100">
<!-- 取模分片-->
<table name="user_info" dataNode="dn213,dn214" rule="mod-long" />
# 3、连接mycat的9066管理端,重新加载mycat的配置,
mysql> reload @@config_all;
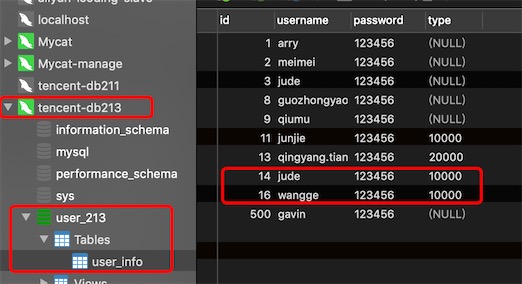
在mycat上插入三条数据id的值分别为:14,15,16
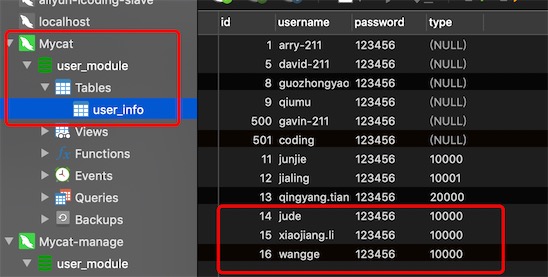
按照分片规则14和16分到了db213,15分到了db214
5.3 .按时间分片
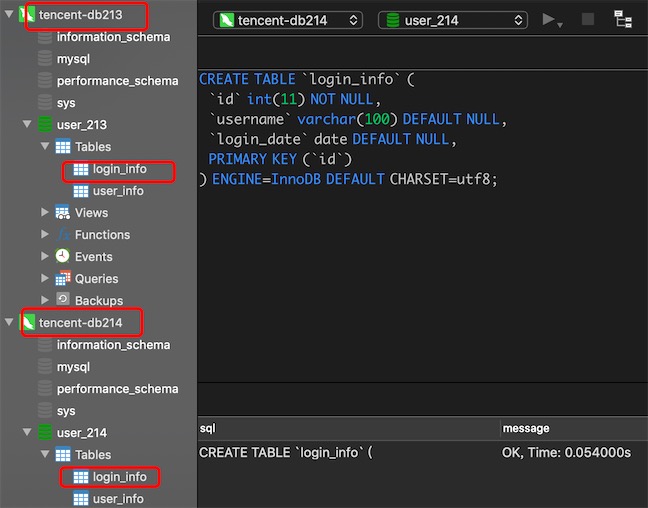
分别在分片主机db213的物理库user_213创建表login_info和分片主机db214的物理库user_214创建表login_info
CREATE TABLE `login_info` (
`id` int(11) NOT NULL,
`username` varchar(100) DEFAULT NULL,
`login_date` date DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
# 1、在rule.xml中创建一个新的时间规则
[root@helloworld conf]# vim rule.xml
<tableRule name="my-sharding-by-date">
<rule>
<columns>login_date</columns>
<algorithm>my-sharding-by-date-func</algorithm>
</rule>
</tableRule>
# 增加一个function
<function name="my-sharding-by-date-func" class="io.mycat.route.function.PartitionByDate">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2020-06-20</property>
<property name="sEndDate">2020-06-23</property>
<property name="sPartionDay">1</property>
</function>
# cloumns:分区字段
# algorithm:指定分片算法
# dateFormat:日期格式
# sBeginDate:开始时间
# sEndDate:结束时间
# sPartionDay:分区的大小,1代表一天分一个,如果超过结束时间则循环写入
# 2、修改schema.xml,表login_info的分片策略为my-sharding-by-date
<schema name="user_module" checkSQLschema="true" sqlMaxLimit="100">
<!-- 时间分片-->
<table name="login_info" dataNode="dn213,dn214" rule="my-sharding-by-date" />
# 3、连接mycat的9066管理端,重新加载mycat的配置,
mysql> reload @@config_all;
启动mycat报错

错误提示很明确,按照分区规则会有4个分区,但我在schema.xml 配置login_info表只有2个datanode: dn213,dn214,所以对不上,我尝试修改sPartionDay=2
# 修改rule.xml
<function name="my-sharding-by-date-func" class="io.mycat.route.function.PartitionByDate">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2020-06-20</property>
<property name="sEndDate">2020-06-23</property>
<property name="sPartionDay">2</property>
</function>
启动成功,在Mycat连接的服务端8066插入数据
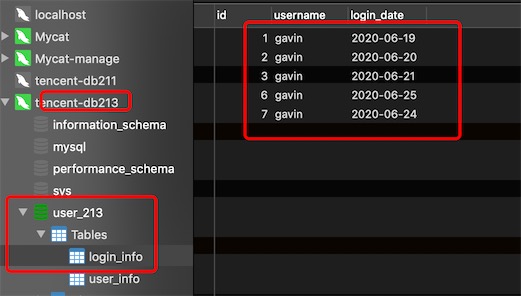
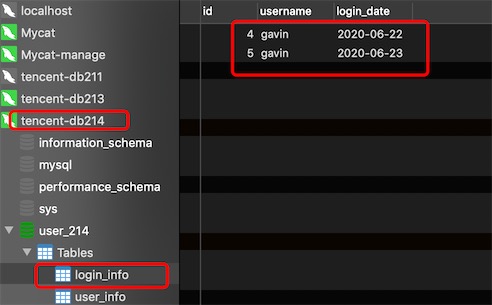
insert into login_info(id,username,login_date) values(1,'gavin','2020-06-19');
insert into login_info(id,username,login_date) values(2,'gavin','2020-06-20');
insert into login_info(id,username,login_date) values(3,'gavin','2020-06-21');
insert into login_info(id,username,login_date) values(4,'gavin','2020-06-22');
insert into login_info(id,username,login_date) values(5,'gavin','2020-06-23');
insert into login_info(id,username,login_date) values(6,'gavin','2020-06-24');
insert into login_info(id,username,login_date) values(7,'gavin','2020-06-25');
分片节点dn213的数据
分片节点dn214的数据
5.4. MyCat全局表的概念
对于数据量不大的基础配置表就没必要横向拆分,在每个数据分片节点上的全局表的数据是一样的,如省市区表,避免了分布式事务,
在2个分片节点dn213,dn214所以对应的物理库创建province_info表
CREATE TABLE `province_info` (
`id` int(11) NOT NULL,
`province_name` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
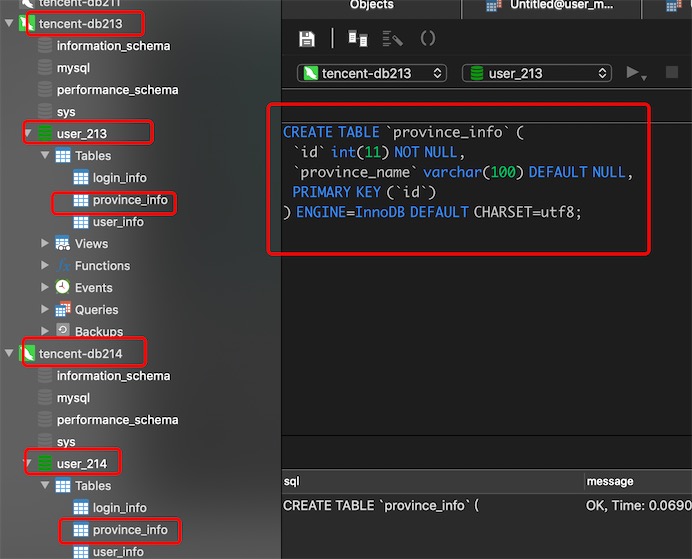
# 1、修改schema.xml,表province_info ,type=global,不分片,全局表
<schema name="user_module" checkSQLschema="true" sqlMaxLimit="100">
<table name="province_info" dataNode="dn213,dn214" type="global"/>
# 2、连接mycat的9066管理端,重新加载mycat的配置,
mysql> reload @@config_all;
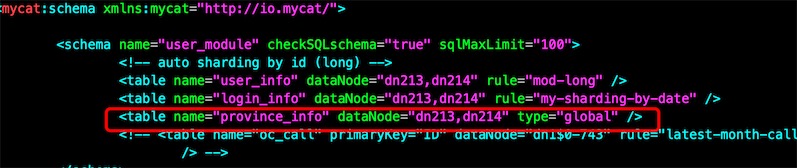
在Mycat连接的服务端8066插入数据
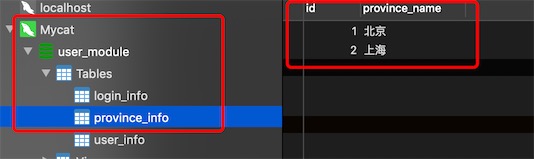
分片节点dn213的数据
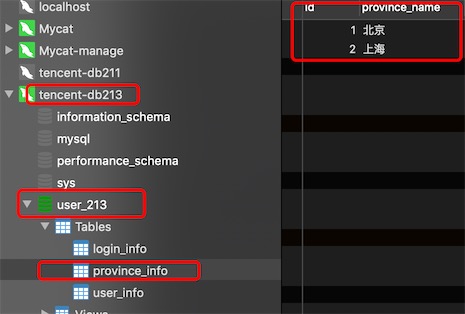
分片节点dn214的数据
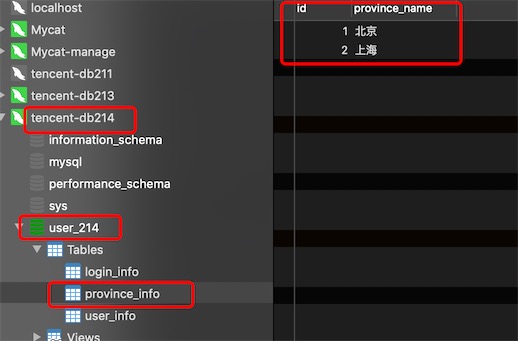
发现数据是一样的,做了全局表,不分库了
5.5. MyCat子表管理
比如我们的订单信息,一般分为订单info表,订单item表,这两个表即便是按照一样的分区规则,也有可能到导致数据去到不同库,这个时候就会导致跨库,如何避免?使用子表关联,让同一个订单id的主表数据和子表数据放在同一个物理库中。
在2个分片节点dn213,dn214所以对应的物理库创建表order_info,order_item
# 创建两个关联表
CREATE TABLE `order_info` (
`id` int(11) DEFAULT NULL,
`order_total` decimal(10,2) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `order_item` (
`id` int(11) DEFAULT NULL,
`order_id` int(11) DEFAULT NULL,
`product_name` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
# 1、修改schema.xml,主表order_info按照字段id进行取模分片,子表不用设置分片规则,因为它跟着主表走,就是主表数据往哪个分片放,# 子表也一样
# joinKey 子表的关联字段
# parentKey 就是子表的joinKey与主表(父表)的哪个字段进行关联
<schema name="user_module" checkSQLschema="true" sqlMaxLimit="100">
<table name="order_info" dataNode="dn213,dn214" rule="mod-long">
<childTable name="order_item" joinKey="order_id" parentKey="id"/>
</table>
# 2、连接mycat的9066管理端,重新加载mycat的配置,mycat不用重启
mysql> reload @@config_all;
在Mycat连接的服务端8066插入数据
insert into order_info(id,order_total) values(10,139.9);
insert into order_item(id,order_id,product_name) values(111,10,'安装牛奶');
insert into order_info(id,order_total) values(11,39.9);
insert into order_item(id,order_id,product_name) values(120,11,'亨利玉米片');
发现id为10的主表数据和它的子表数据都放到了dn213,id为11的主表数据和它的子表数据都放到了dn214,实现了同一个order_id的数据不分离。
6. MyCat安全机制
6.1. 用户权限的配置
# 修改server.xml
[root@helloworld conf]# vi server.xml
<user name="customer">
<property name="password">123456</property>
<property name="schemas">user_module</property>
<property name="readOnly">true</property>
<property name="benchmark">2</property>
</user>
# readOnly只读设置,只能查询
# benchmark:当链接达到这里设置的值就拒绝访问,0或不设置就是不拒绝,至少设置为2,因为Mycat会留一个连接给自己使用。
# 不同用户可以连接同一个逻辑库
# 超出benchmark限制报错
ERROR 1045 (HY000): Access denied for user 'customer', because service be degraded
schema中的表的操作权限
# 修改server.xml
<user name="mycat" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">user_module</property>
<!-- 表级 DML 权限设置 -->
<privileges check="true">
<schema name="user_module" dml="1111" >
<table name="province_info" dml="1110"></table>
<table name="order_info" dml="1101"></table>
</schema>
</privileges>
</user>
# 1111的顺序分别对应 insert(0/1),update(0/1),select(0/1),delete(0/1) 基于schema下的表的具体权限
6.2. 黑白名单
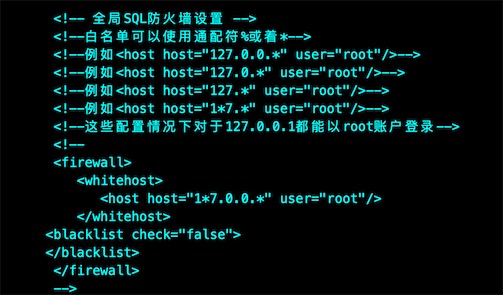
# 跟mysql限制用户的连接ip是一样道理的
# 修改server.xml
# 先设置白名单
<firewall>
<whitehost>
<host host="192.168.0.213" user="mycat"/>
<host host="192.168.0.214" user="customer"/>
</whitehost>
</firewall>
# 黑名单,对dml权限的限制,是基于整个用户的,而上面的是基于schema下的表的具体权限
<firewall>
<whitehost>
<host host="192.168.0.213" user="mycat"/>
</whitehost>
<blacklist check="true">
<property name="deleteAllow">false</property> # 不允许删除
</blacklist>
</firewall>
# 黑名单的权限配置项,是允许用户进行操作
selectAllow true/false
deleteAllow true/false
updateAllow true/false
insertAllow true/false
# 修改后,连接mycat的9066管理端,重新加载mycat的配置,mycat不用重启
mysql> reload @@config;
mysql> reload @@config_all;
# 测试
mysql> delete from login_info where id=7;
3012 - The statement is unsafe SQL, reject for user 'jude', Time: 0.016000s
7. MyCat集群高可用
安装zookeeper
官网:https://zookeeper.apache.org/
zookeeper,中文意思就是动物园管理员,如图所示,通过zookeeper(群)来管理协调各个集群形态的分布式组件。
Zookeeper特性
一致性:数据一致性,数据按照顺序分批入库 原子性:事务要么成功要么失败,不会局部化 单一视图:客户端连接集群中的任一zk节点,数据都是一致的 可靠性:每次对zk的操作状态都会保存在服务端 实时性:客户端可以读取到zk服务端的最新数据

# zk依赖java环境
# 1、下载
wget https://mirrors.bfsu.edu.cn/apache/zookeeper/zookeeper-3.5.8/apache-zookeeper-3.5.8-bin.tar.gz
# 解压
tar -zxvf apache-zookeeper-3.5.8-bin.tar.gz
# 移动到安装目录
mv apache-zookeeper-3.5.8-bin apache-zookeeper-3.5.8
# 2、创建目录
[root@helloworld apache-zookeeper-3.5.8]# mkdir data
[root@helloworld apache-zookeeper-3.5.8]# mkdir logs
# 3、修改zk配置
[root@helloworld apache-zookeeper-3.5.8]# cd conf
[root@helloworld conf]# cp zoo_sample.cfg zoo.cfg
[root@helloworld conf]# vim zoo.cfg
dataDir=/usr/local/apache-zookeeper-3.5.8/data
dataLogDir=/usr/local/apache-zookeeper-3.5.8/logs
# 4、环境变量配置
[root@helloworld local]# vim /etc/profile
export ZOOKEEPER_HOME=/usr/local/apache-zookeeper-3.5.8
export PATH=$PATH:$ZOOKEEPER_HOME/bin
# 使配置生效
source /etc/profile
# 5、服务管理命令
zkServer.sh start|stop|restart|status
# 客户端连接,客户端关闭:quit ,推荐使用界面操作工具zooInspector,因为zookeeper的数据是树形结构存储的,使用界面会更为直观
zkCli.sh -server ${ip}:${port}
# -------配置zk集群---------
# 假设有3个zk服务: 192.168.162.128:2181、192.168.162.129:2181、192.168.162.130:2181
# 1、修改zoo.cfg,增加
[root@helloworld conf]# vim zoo.cfg
server.1=192.168.162.128:2888:3888 # 2888 是集群内通信的端口
server.2=192.168.162.129:2888:3888 # 3888 是集群选举投票的端口
server.3=192.168.162.130:2888:3888
# 2、server.ID,这里的1\2\3其实就是3个zk的id,在集群中为了识别它们,所以要分别在3个zk的dataDir目录下(上面zoo.cfg已配置)创建myid文件,内容分别就是1、2、3
cd /usr/local/apache-zookeeper-3.5.8/data
[root@helloworld data]# vim myid
1
zooInspector 界面工具
下载地址:https://issues.apache.org/jira/secure/attachment/12436620/ZooInspector.zip
# 解压,进入目录ZooInspector\build,运行zookeeper-dev-ZooInspector.jar
java -jar zookeeper-dev-ZooInspector.jar //执行成功后,会弹出java ui client
# 点击左上角连接按钮,输入Zookeeper服务地址:ip:2181
# 点击OK,就可以查看Zookeeper节点信息啦
云服务器要开启安全组和防火墙端口2181
dockerfile创建mycat镜像
1、原材料
jdk-8u201-linux-x64.tar.gz
Mycat-server-1.6.7.3-release-20190927161129-linux.tar.gz
2、编写Dockerfile
FROM centos:7.8.2003
MAINTAINER jude<747463168@qq.com>
COPY readme.md /usr/local/readme.md
ADD jdk-8u201-linux-x64.tar.gz /usr/local
ADD Mycat-server-1.6.7.3-release-20190927161129-linux.tar.gz /usr/local
RUN yum install -y vim
ENV MYPATH /usr/local
WORKDIR $MYPATH
ENV JAVA_HOME /usr/local/jdk1.8.0_201
ENV CLASSPATH $JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
ENV PATH $PATH:$JAVA_HOME/bin
VOLUME /usr/local/mycat/conf
EXPOSE 8066 9066
CMD /usr/local/mycat/bin/mycat start && tail -F /usr/local/mycat/version.txt
3、创建镜像
docker build -t mycat:1.6.7 .
4、启动运行
docker run -d -p 8067:8066 -p 9067:9066 --name mycat2 mycat:1.6.7
# 设置挂载卷,conf下是没有配置文件的,还不知道如何解决
# 不设置挂载卷就正常,conf下有配置文件
zookeeper托管Mycat配置
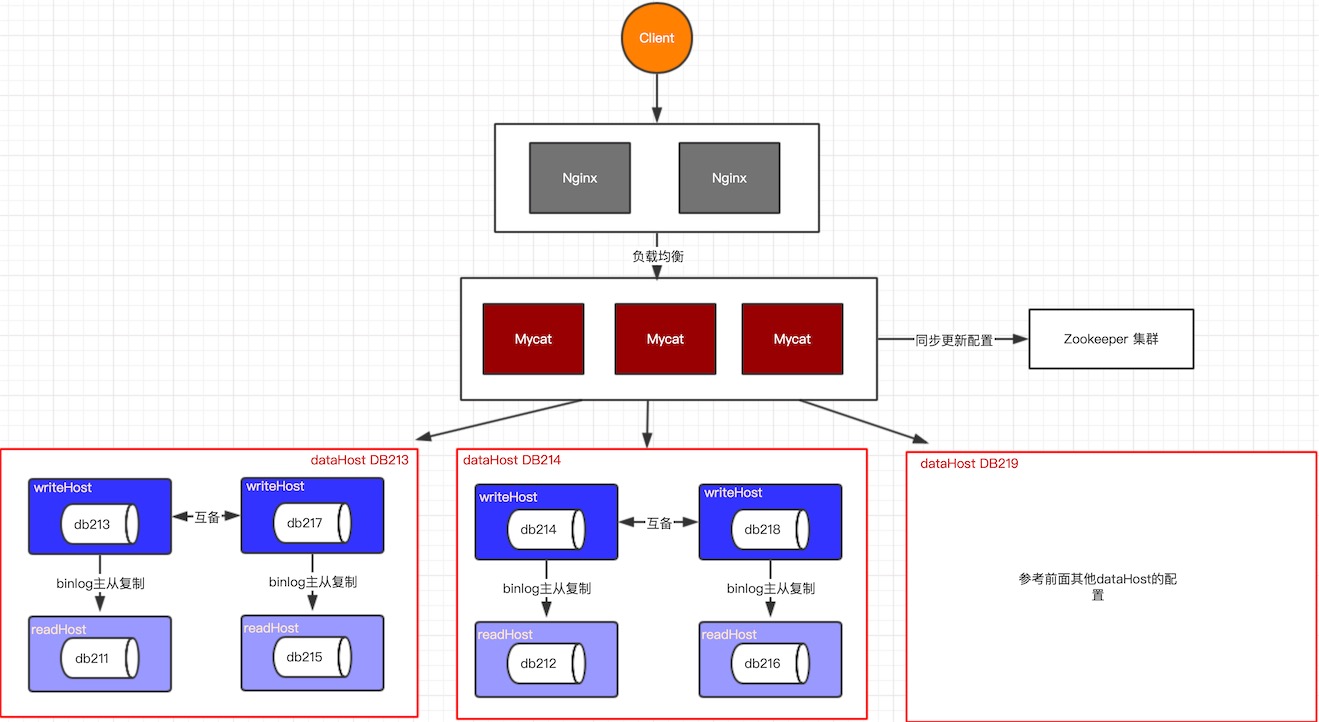
MyCat对于每个数据节点都可以实现HA和负载均衡,所有数据节点形成了一个分布式的数据库
如果MyCat作为一个中间层挂了怎么办?进行集群化
如果要对MyCat进行集群化:MyCat是不是无状态的节点?是的。
Nginx/HAProxy/Lvs/SLB + MyCat
如果多个MyCat,你的配置如何同时更新:zookeeper帮助我们进行配置的统一管理
配置同步
修改Mycat的配置让它同步到zookeeper
# 修改第一个Mycat
# 1.修改conf下的myid.properties
[root@helloworld conf]# vim myid.properties
loadZk=true # 是否从zk下载配置
zkURL=192.168.0.215:2181 # zk的连接
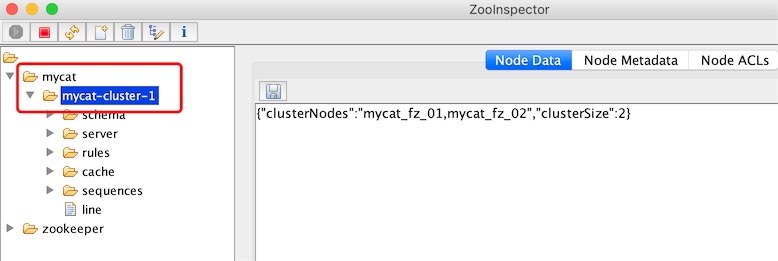
clusterId=mycat-cluster-1 # mycat的集群名称
myid=mycat_fz_01
clusterSize=2 # mycat的节点数
clusterNodes=mycat_fz_01,mycat_fz_02 # mycat集群的节点有哪些
#server booster ; booster install on db same server,will reset all minCon to 2
type=server
boosterDataHosts=dataHost1
# 2.将之前单机的配置 server.xml,schema.xml,rule.xml,autopartition-long.txt
# 将这些修改后的配置文件传输到mycat/conf/zkconf目录下来做上传使用
[root@helloworld conf]# cp server.xml zkconf
cp: overwrite ‘zkconf/server.xml’? y
[root@helloworld conf]# cp schema.xml zkconf/
cp: overwrite ‘zkconf/schema.xml’? y
[root@helloworld conf]# cp rule.xml zkconf/
cp: overwrite ‘zkconf/rule.xml’? y
[root@helloworld conf]# cp autopartition-long.txt zkconf/
cp: overwrite ‘zkconf/autopartition-long.txt’? y
# 3.执行zookeeper配置的同步脚本,在mycat/bin目录下
./init_zk_data.sh
# 报错
-bash: ./init_zk_data.sh: /bin/bash^M: bad interpreter: No such file or directory
# 修改一下命令
sed -i 's/\r$//' init_zk_data.sh
# 再次执行,记得zookeeper要开启
[root@helloworld bin]# ./init_zk_data.sh
o2020-06-30 09:13:49 INFO JAVA_CMD=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.191.b12-1.el7_6.x86_64/bin/java
o2020-06-30 09:13:49 INFO Start to initialize /mycat of ZooKeeper
o2020-06-30 09:13:52 INFO Done
# ---------修改第二个Mycat----------
# 1、修改conf下的myid.properties
[root@helloworld conf]# vim myid.properties
loadZk=true # 是否从zk下载配置
zkURL=192.168.0.215:2181 # zk的连接
clusterId=mycat-cluster-1 # mycat的集群名称
myid=mycat_fz_02
clusterSize=2 # mycat的节点数
clusterNodes=mycat_fz_01,mycat_fz_02 # mycat集群的节点有哪些
zooInspector 连接zookeeper查看mycat的配置是否已经托管上来
启动两个mycat进行测试
连接两个Mycat的服务端口8066,发现数据是一样的,因为底层数据是存储在mysql的。
修改zookeeper的配置,会同步到两个Mycat上
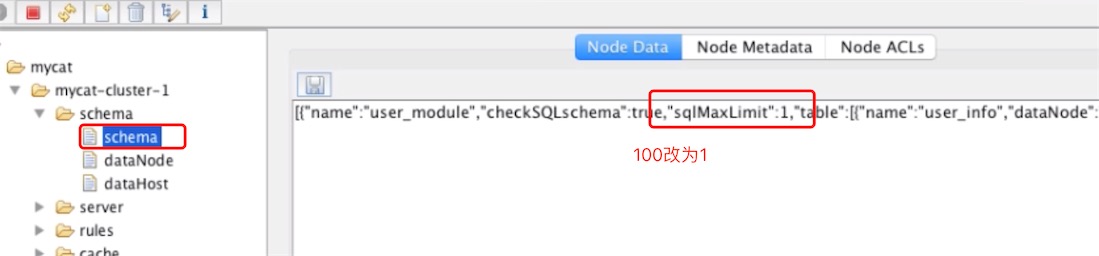
不需要reload config就生效,zookeeper是通过本身内部的监听机制实现的,它监听文件节点的变化,如果变化了,就通知订阅节点的Mycat更新
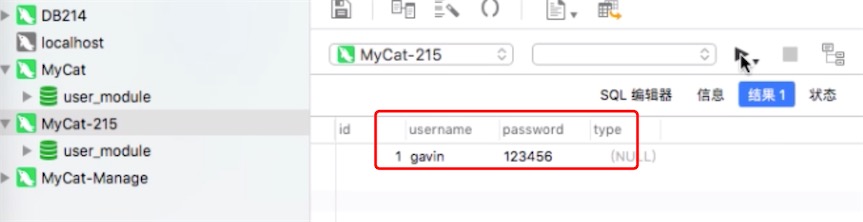
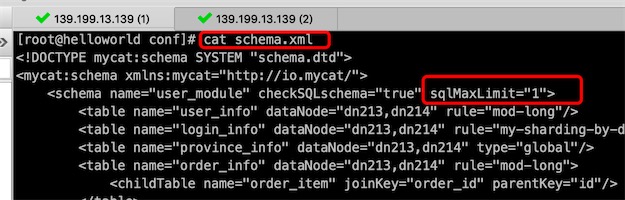
发现两个mycat下的conf/schema.xml文件都已修改
作业:搭建一套HA高可用的MyCat服务,至少两套MyCat对外提供应用,并且有多个用户开启黑白名单和表的DML权限(数据库里要有全局表和子表的设计)
已按照老师课堂上的练习做了一遍
Nginx+Zookeeper+Mycat+Mysql的HA高可用架构: