 弹吉他的兔子
弹吉他的兔子
1、分布式架构的分析
优点与缺点
分而治之,比一个节点要无论是计算能力还是存储能力,都要提升很多
优点
- 业务解偶
- 系统模块化,可重用化高
- 提升系统的并发量
- 优化了运维部署的效率(Pre,dubbo:Mock)
缺点
- 架构复杂(人员学习成本高)
- 多个子系统部署复杂
- 系统之间通信耗时
- 调试排错复杂
设计原则
- 异步解偶
- 幂等要一致 N*1(定时任务,8点去数据库把A+1):分布式锁来解决
- 拆分原则
- 融合分布式的中间件:Redis、ES、MQ
- 容错高可用
2、分布式缓存分析
什么是NoSQL
- Not Only SQL
- 横向扩展更加方便
- HA(集群)
- 持久化
- NoSQL常见的分类
- key-value:Redis、Memcache
- 列存储:Hbase
- 文档型:MongoDB
- 图形:Neo4J、FlockDB
什么是Redis
- NoSQL
- 分布式缓存中间件
- key-value存储
- 海量数据访问
- 数据是存在内存里的,读取更块
- 支持水平扩展
Ehcache
- 优点
- Java开发的
- 基于JVM缓存
- 简单、方便:hibernate和Mybatis都有集成
- 缺点
- 不支持集群(更适合单机应用)
- 不支持分布式
Memcache
- 优点
- 简单的key-value存储
- 内存使用率高
- 多核,多线程
- 缺点
- 无法容灾
- 无法持久化
Redis
- 优点
- 丰富的数据结构
- 持久化
- 主从同步,故障转移(一台机挂了,访问可以跳到另一台机)
- 支持集群3.x以后
- 缺点
- 单线程(大量数据存储的时候性能会降低)
- 单核(无法充分利用CPU的多核性能,建议使用多实例)
3、Redis单机安装
#下载redis 上传到服务器,解压
tar -zxvf redis-5.0.7.tar.gz
yum -y install gcc-c++
#解压后的根目录
cd redis-5.0.7
make && make install
#/usr/local/bin redis-server /usr/local/redis/redis.conf
# 配置以服务的方式启动redis
#1.在/usr/local下创建redis目录
mkdir /usr/local/redis
#2.复制redis.conf文件,以redis的端口号命名
cd redis-5.0.7
cp redis.conf /usr/local/redis/6379.conf
#3.修改
vi redis.conf
daemonize yes #后台运行
bind 0.0.0.0 #不限制ip访问
requirepass icoding #密码
dir /usr/local/redis/working #工作目录,rdb备份的数据保存目录
#4.将redis安装包util下的redis_init_script
cp redis_init_script /etc/init.d/redisd
vi redisd
CONF="/usr/local/redis/${REDISPORT}.conf" #配置文件的路径
PASSWORD=icoding
$CLIEXEC -p $REDISPORT -a $PASSWORD shutdown
#给redisd授权
chmod 777 redisd
#启动
service redisd start
#关闭
service redisd stop
4、Redis的数据类型命令
String
# 一定不能线上执行,否则key太多占用服务器资源
keys *
keys abc*
#管道命令不在redis-cli客户端下执行,在linux下执行模糊删除
#redis-cli -a icoding keys "a*" | xargs redis-cli -a icoding del
set age 18 #没有则创建,有则覆盖
setnx age 18 #没有则创建,有什么都不做
type age #获取类型
get/del key #获取删除数据
set key value ex time #设置值的时候同时设置过期时间(秒)
ttl key #还剩多久,-1永不过时,-2过去,正数就是还剩多少秒
append age gavin #追加字符串
strlen key #获取字符串长度
incr/decr key #给value+1/-1,如果key不存在则创建并将值设置为1
incrby/decrby key step #不存则创建一个-step/+step
getrange key start end # end=-1 表示到最后
setrange key start newdata # 替换
mset key1 value1 key2 value2 # 不支持过期时间同时设置,批量设置值
mget key1 key2 # 连续取值
msetnx key1 value1 key2 value2 #没有则创建,有什么都不做
#我们的Redis可以当成一个数据库,甲方1,甲方2,甲方3,就可以使用redis的库的概念
#databases 16 #默认从0到15共16个库,配置文件可以配置库的个数
#select 1 选择的2个库
set icoding 7
# 危险命令
keys
flushdb #他是原子性的,一旦执行就无法回头,删除当前db下所有数据
flushall #删除所有数据库的数据
config get port#获取配置的端口信息
config get * #获取所有的配置信息
# 给命令重命名
rename-command CONFIG "icodingconfig"
rename-command KEYS "icodingkeys"
rename-command FLUSHDB "icodingflushdb"
rename-command FLUSHDB "" # 禁用FLUSHDB命令
rename-command FLUSHALL "icodingflushall"
哈希Hash
# 比如对象
user {
name : icoding
age : 18
sex : male
}
# 设置对象
hset/hsetnx user name icoding age 18 sex male
hget user name
hmset user name icoding age 18
hmget user name age sex
# 获取对象所有属性
hgetall user
# 按
hincrby user age 2
hincrbyfloat user age 2.2
hlen user #获取有多少个属性
hexists user age # 判断属性是否存在
hkeys user #获取所有属性
hvals user #获取所有value
hdel user name #删除属性
del user #删除key
列表List
#list对象[]
lpush userList v1 v2 v3 v4 v5 #从左边开始压栈
rpush userList v1 v2 v3 v4 v5 #从右边开始压栈
lpop userlist #从左边出栈
rpop userlist #从右边出栈
llen userList #元素个数
lindex userList index #直接获取下标对应的值
lset userList index value #直接设置下标的值
linsert userList before/after pivot(栈内的具体值) value
lrem userList num value #删除几个相同数据的value
ltrim userList start end #截取
集合Set
sadd userSet v1 v2 v3 v4 val5 val5 #保存集合并去重
smembers userSet #获取值,但顺序和写入不一定相同
scard userSet #获取集合数量
sismember userSet value #看value是否存在于集合中
srem userSet val1 val2 #删除集合值
spop userSet 2 #随机出栈2个,场景:随机抽奖
srandmember userSet 2 #随机展示两个,场景:随机抽奖
smove k1 k2 v2 #将集合k1中的v2移动到k2中
sinter k1 k2 #交集,交叉的值
sunion k1 k2 #并集并去重
有序集合ZSet
场景:排序、评估
zadd zk1 10 apple 20 peach 30 banana 40 pear 50 cherry #设置有分数的集合
zadd zk1 10.8 apple 20.9 peach 30.1 banana 40 pear 50 cherry
zrange zk1 0 -1 withscores #根据位置获取数据并显示分数,-1全部
zcard zk1 #获得集合数量
zrank zk1 banana #获取值的下标
zscore zk1 apple #获取值的分数
zcount zk1 10 30 #统计分数区间有的数据个数
zrangebyscore zk1 10 40 #获取分数内的值
zrangebyscore zk1 10 40 limit 13 #在分数的基础上再进行下标的区间的过滤
zrangebyscore zk1 (10 (40 #获取分数内的值不包含边界
zrem zk1 apple #删除集合中的值
地理位置Geo
它是zset扩展类型,在Redis 3.2版本后提供的,支持存储地理坐标的一个数据结构,可以用来做类似摇一摇,附近的人,周边搜索的功能
# 语法类型
geoadd key 经度 纬度 成员 [经度 纬度 成员...]
# geoadd命令必须以标准的x y member结构来接受参数,必须先输入经度后输入纬度
geoadd能够记录的坐标是有限:
- 非常接近两级的区域无法索引(南北极)
- 精确的坐标限制是由 EPSG:900913等坐标系统定义
- 经度:-180到180度之间
- 纬度:-85.05117878到85.05117878度之间
- 如果超出这个范围则会报错
新增和查询
# 添加一批城市
geoadd china:city 116.408 39.904 beijing 121.445 31.213 shanghai 113.265 23.108 guangzhou 114.109 22.544 shenzhen 108.969 34.285 xian 108.55 34.09 changan
# 查询
geopos china:city beijing shanghai
中国城市经纬度 http://www.hao828.com/chaxun/zhongguochengshijingweidu
获得节点间距离
geodist china:city shanghai beijing km
单位:
- m : 米
- km :千米
- mi :英里
- ft : 英尺
- 默认是m
- 会有0.5%的误差(因为地球是椭球体,不是完全的球体)
周边搜索
# 方圆多少公里内有哪些节点
georadius china:city 121.445 31.213 1300 km withdist withcoord
georadius china:city 121.445 31.213 1300 km withdist withcoord asc count 3
georadiusbymember china:city beijing 1300 km withdist withcoord asc count 3
# 节点hash
geohash china:city xian changan
1) "wqj7p9ku9e0"
2) "wqj1yjgswk0"
- withdist : 返回节点距离
- withcoord : 带上坐标
- asc/desc: 升序/降序
删除节点
zrem china:city changan # zset的删除命令
type china:city # 返回zset类型
业务场景
搜索附近的人,餐饮
x y name1 x y name2
x y canyin:123 x y canyin:456
Hyperloglog
这个数据类型其实就做了一件事,统计不重复的数据量
比如要记录我们网站的UV(user view)量
sadd 20200208 1 2 3 4 5 6 5 4 3 2 1
scard 20200208
它只存放基数,不存放数据
pfadd 20200207 1 2 3 4 5 6 5 4 3 2 1 # 添加记录基数
pfadd 20200206 1 2 3 4 5 6 7 8 9 10
pfcount 20200206 # 返回基数
pfmerge 202002 20200206 20200207 #pfmerge newkey sourcekey1 sourcekey2 合并生成了一个新key,原来的key不会消失
- hyperloglog是一个基数估算算法,有一定误差的
- 误差值在0.81%
- hyperloglog的key占用空间很小只有12K,而你用set就需要把这些value都要保存,set存一年数据有多大
5、Redis的线程模型
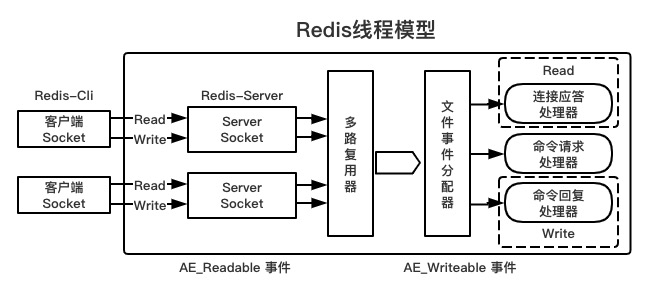
Redis是一个单线程应用
每一条到达服务端的命令都不会立即执行,所有命令都会进入一个队列中,所以Redis不会产生并发问题
为什么Redis是单线程模型效率还这么高
1、纯内存访问:数据放在内存中,内存的响应时间100纳秒
2、非阻塞I/O:Redis采用epoll作为I/O多路复用技术的实现,再加上Redis自身的事件处理模型将epoll中的连接、读写、关闭都转换为事件,不在I/O上浪费过多时间
3、采用单线程,避免了不必要的上下文切换和竞争条件
由于模型的本身机制,因此尽量不要和redis交互大数据量的内容
什么是多路复用
假如你是一个老师,让30个学生回答问题,如何在学生做完后检查是否正确?
1、第一种:A,B,C,D按顺序轮询
2、第二种:老师身上有查克拉会分身,分了30分身去处理(相当于30个进程处理)
3、第三种:你在讲台上问谁回答完毕谁举手,你去回答谁,这就是I/O复用模型了