 弹吉他的兔子
弹吉他的兔子
1、Redis主从架构
原理分析
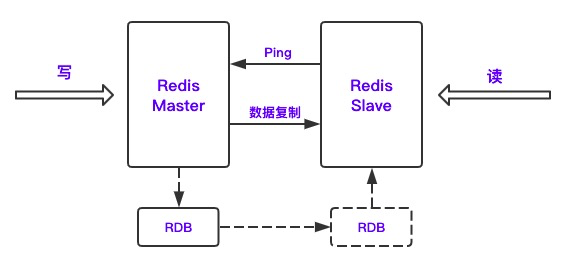
主从出现的原因
- 高并发
- 官方数据表示Redis的读数据11w/s左右,写速度是8w/s左右
- Redis尽量少写多读,符合缓存的适用要求
- 可以通过主从架构来进行读写分离
- HA(高可用)
- 如果有一个以上的从库就会对节点进行备份
同步的过程中一定要开启持久化,原因如下
- 如果master出现宕机内存丢失,从库也会删除
- master进行功能性重启,内存数据丢失,也会同步给slave
主从复制原理
-
当slave第一次连接时,会触发全量同步,如果已经连接过了,只会同步新增数据
-
全量备份分为落盘和不落盘两种形式,默认是落盘(保存文件)
# 不落盘复制配置 yes不落盘,no落盘 repl-diskless-sync no # 等待其他slave连接的一个时间周期,单位是秒 repl-diskless-sync-delay 5 - 支持断点续传
- 如果从库过多会导致占用带宽较大,所以从不易过多
主从的结构除了一对多,还可以是树形的,树形结构用的比较少
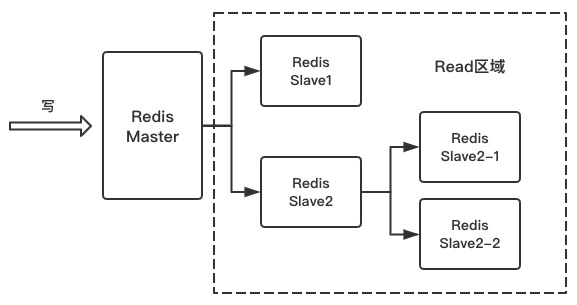
主从设置
考虑主从节点会互相切换的情况,主从节点的配置基本上是一样的
# 可以通过命令看一下主从信息,v5.x版本前从是用slave表示,之后换成replication
# 1、master和slave节点都可以查看
info replication
# 2、修改slave的redis.conf
replicaof 192.168.1.100 6379 #master的ip,master的端口
# 3、在master和slave配置上添加,避免主节点宕机后重启成为从节点,配置文件没有设置密码的话就无法连接到新的主节点了
masterauth icoding #主机的访问密码
# 4、默认开启yes,在slave上配置
# yes 主从复制中,从服务器可以响应客户端请求
# no 主从复制中,从服务器将阻塞所有请求,有客户端请求时返回“SYNC with master in progress”;
replica-serve-stale-data yes
# 5、默认开启并配置为yes,在slave上配置
# slave节点只允许read 默认就是 yes,这个配置只对slave节点才生效,对master节点没作用
replica-read-only yes
# 6、默认没有开启,在slave的配置上打开
# slave根据指定的时间间隔向master发送ping请求,默认10秒,相当于心跳检测
repl-ping-replica-period 10
# 7、默认没有开启,在slave的配置上打开
# 复制连接超时时间。
# master和slave都有超时时间的设置。
# master检测到slave上次发送的时间超过repl-timeout,即认为slave离线,清除该slave信息。
# slave检测到上次和master交互的时间超过repl-timeout,则认为master离线。
# 需要注意的是repl-timeout需要设置为比repl-ping-slave-period更大的值,不然会经常检测到超时。
repl-timeout 60
# 8、是否禁止复制tcp链接的tcp nodelay参数,默认开启并配置为no,在master上配置
# 默认是no,即使用tcp nodelay,允许小包的发送。对于延时敏感型,同时数据传输量比较小的应用,开启TCP_NODELAY选项无疑是一个正确的选择
# 如果master设置了yes来禁止tcp nodelay设置,在把数据复制给slave的时候,会减少包的数量和更小的网络带宽。
# 但是这也可能带来数据的延迟。
# 默认我们推荐更小的延迟,但是在数据量传输很大的场景下,建议选择yes。
repl-disable-tcp-nodelay no
# 9、默认没有开启,在master上配置
# 复制缓冲区大小,这是一个环形复制缓冲区,用来保存最新复制的命令。
# 这样在slave离线的时候,不需要完全复制master的数据,如果可以执行部分同步,只需要把缓冲区的部分数据复制给slave,就能恢复正常复制状态。
# 缓冲区的大小越大,slave离线的时间可以更长,复制缓冲区只有在有slave连接的时候才分配内存。
# 没有slave的一段时间,内存会被释放出来,默认1m。
repl-backlog-size 5mb
# 10、默认没有开启,在master上配置
# master没有slave一段时间会释放复制缓冲区的内存,repl-backlog-ttl用来设置该时间长度。
# 单位为秒。
repl-backlog-ttl 3600
# 11、默认开启,在slave上配置
# 当master不可用,Sentinel会根据slave的优先级选举一个master。
# 最低的优先级的slave,当选master。
# 而配置成0,永远不会被选举。
# 注意:要实现Sentinel自动选举,至少需要2台slave。
replica-priority 100
# 12、默认没有开启,在master上配置
# redis提供了可以让master停止写入的方式,如果配置了min-slaves-to-write,健康的slave的个数小于N,mater就禁止写入。
# master最少得有多少个健康的slave存活才能执行写命令。
# 这个配置虽然不能保证N个slave都一定能接收到master的写操作,但是能避免没有足够健康的slave的时候,master不能写入来避免数据丢失。
# 设置为0是关闭该功能,默认也是0。
min-replicas-to-write 2
# 13、默认没有开启,在master上配置
# 延迟小于min-replicas-max-lag秒的slave才认为是健康的slave。
min-replicas-max-lag 10
2、Redis缓存过期机制
key一般会有两种操作:不设置过期时间,设置过期时间(无论是否设置,只要你的业务内容足够复杂内容足够多,Redis主机的内存是永远的不够的,假定目前你的企业Redis的配置还停留在主从阶段)
-
影响存储大小的是不是你的主机内存?
不是,是主从节点中内存最小的服务器那个决定的。
-
如果内存不够了,放满了,Redis怎么处理?
按过期机制删除key
Redis内存的删除机制
- 主动删除(定期删除)
- 只要设置了expire,redis会默认1秒抽查10次,来巡检这些过期的key,把它删除掉来释放内存
- 在redis.conf文件里有个叫:hz的配置(hz 10)过大CPU负担比较重,这个参数用来配置redis 每隔1秒抽查的次数。
- 被动删除:
- redis内部在访问每个key的时候,会调用一个内部方法:expireIfNeeded(),如果过期就会返回nil,拿空间换时间
- 如果你的key大部分没有设置过期时间,内存满了怎么办?
Redis提供一套内存淘汰机制:MEMORY MANAGEMENT
# master 8G slave 6G
# 服务不是只运行redis这个服务,还有linux本身的内核swap,这个是可以给操作系统留一些余量
# maxmemory <bytes> 设定redis可用内存大小
# 内存淘汰规则
# maxmemory-policy noeviction 但Redis默认就是这个配置
# volatile-lru -> 在那些设置了expire的缓存中,清除最少使用的旧缓存,可以保存新缓存
# allkeys-lru -> 清除最少用的旧缓存:推荐使用
# volatile-lfu -> Evict using approximated LFU among the keys with an expire set.
# allkeys-lfu -> Evict any key using approximated LFU.
# volatile-random -> Remove a random key among the ones with an expire set.过期缓存中随机删除
# allkeys-random -> 在所有缓存中随机删除:不推荐的
# volatile-ttl -> Remove the key with the nearest expire time (minor TTL)
# noeviction -> 缓存永不过期,当内存使用到最大了,使用set,lpush等写命令就会报错,使用get命令可以。
3、哨兵模式
问题:Master挂了,如何保证可用性,实现继续写
现象:slave的数据还有,需要手动把slave升级成master,需要去修改程序的配置了,很不方便,啥时候的挂的?
解决:Redis本身就提供了一个机制-Sentinel哨兵
什么是哨兵
Redis的sentinel机制是用于管理多个redis服务器的,sentinel会执行以下四个任务
- 服务监控:负载监控redis master和slave进程是否正常工作
- 消息通知:master如果挂了,哨兵可以根据你配置的脚本来调用发送通知
- 故障转移:master node挂了,sentinel会从slave里选举一个node成为master,会让剩下的slave follow到新master上并从新master复制数据
- 配置中心:如果故障发生转移了,sentinel可以通知客户端,新的master地址的端口是什么
配置哨兵
# redis的安装根目录下,有个sentinel.conf
# 部署三个哨兵节点(sentinel要从redis的slave里选举一个node成为master,所以至少3个哨兵节点),同时监控一组redis服务(只有一个节点其实也可以,但有风险)
cp sentinel.conf /usr/local/redis-6379
vi sentinel.conf
# bind 127.0.0.1 192.168.1.1
# 测试的时候放开访问保护,
protected-mode no
port 26379 #默认是26379
daemonize yes
pidfile /var/run/redis-sentinel-26379.pid #pid 集群要区分开
logfile /usr/local/redis-6379/sentinel/redis-sentinel.log #日志,非常重要
dir /usr/local/redis-6379/sentinel #工作空间
sentinel deny-scripts-reconfig yes
sentinel config-epoch jude-master 11
# sentinel监控的核心配置
# 1、最后一个2,quorum,>=2个哨兵主观认为master下线了,master才会被客观下线,才会选一个slave成为master
sentinel monitor icoding-master 127.0.0.1 6379 2
# 2、master访问密码
sentinel auth-pass icoding-master icoding
# 3、sentinel主观认为master挂几秒以上才会触发选举切换主节点
sentinel down-after-milliseconds icoding-master 3000
# 4、所有slave同步新master的并行同步数量,如果是1就一个一个同步,在同步过程中slave节点是阻塞的不可用的,同步完了才会放开
sentinel parallel-syncs icoding-master 1
# 5、同一个master节点failover之间的时间间隔,默认3分钟,举个例子,master节点A宕机了,重启后成为slave节点,它要重新成为master节点需要等3分钟
sentinel failover-timeout icoding-master 180000
配置完毕进行启动
# 启动redis
[root@aliserver local]# redis-server redis-6379/redis.conf
# 跟redis-server一样,安装好redis后在/usr/local/bin就有redis-sentinel的启动项
[root@aliserver local]# redis-sentinel sentinel.conf
# 如果要搭建集群,只需要将刚刚配置的sentinel.conf复制到其他节点即可

哨兵集群部署的约定
- 哨兵集群至少3个节点
- 最好三个节点在不同的物理机器上
- 一组哨兵最好只监控一组主从
查看哨兵消息
redis-cli -p 26379 #通过哨兵的端口进入
sentinel master icoding-master
sentinel slaves icoding-master
sentinel sentinels icoding-master #查看哨兵信息
故障转移的原理
- S_DOWN (Subjectively Down) 主观宕机
- 一个哨兵根据配置的主观宕机秒数,认为一个master宕机了,就是主观宕机
- sentinel down-after-milliseconds icoding-master 3000 就是这个配置
- 哨兵ping主机,然后返回超过上面设置的时间就认为主观宕机了
- O_DOWN(Objectively Down) 客观宕机
- 如果quorum数量的哨兵觉得一个master宕机了,就是客观宕机
哨兵集群是如何自动发现
通过pub/sub(发布/订阅)机制来实现的,每个哨兵都会pub一个__sentinel__:hello并通过sub(订阅)来获取和感知有多少个同组redis监控的哨兵
并且信息里会携带host ip runid,并让其他哨兵感知到
查看哨兵的日志
tail -n1000 redis-sentinel.log

redis-cli 进入到客户端,执行monitor
127.0.0.1:6379>monitor

slave->master的选举算法
slave选举master会考虑的信息
- 和master断开的时长
- slave的优先级:replica-priority 100(值越低优先级越高)
- 复制的offset位移程度
- run_id
如果slave和master连接断开超过:down-after-milliseconds icoding-master这个配置的10倍以上绝对不考虑
选举顺序
1、按照slave优先级进行排序,replica priority越低,优先级越高
2、如果replica priority级别相同,看offset越靠后(复制的内容多少),优先级越高
3、如果上面两个条件都一样,这个时候看run_id ,run_id字符排序越靠前越优先
先选一个执行主从切换的sentinel,这个sentinel再根据主从选举算法进行选举
quorum和majority
每次哨兵要做主从切换,首先需要quorum数据的哨兵认为O_DOWN,然后选举一个哨兵来做主从切换,这个哨兵要得到majority数量哨兵的授权,才能正式切换
如果quorum<majority,如果5个哨兵,majority就是3个,quorum就是2个
如果quorum>=majority,必须quorum数量的哨兵都授权
configuration epoch
监控的版本号,这个时候所有的哨兵都会记录一套当前的主从关系,这个关系的变更,切换版本号
一个执行哨兵完成了主从切换后,就会通过pub/sub机制来传播给其他哨兵
故障转移的实现
关闭6379的master服务
查看哨兵的日志

修改config命令,改成imconfig
# 可以通过这个命令来修改成无redis修改后的config命令
# SENTINEL rename-command mymaster CONFIG IMCONFIG
实现切换的机制
1. 通过config命令修改redis.conf的主从关系
修改自己的sentinel.conf的主机监控命令
2. 在sentinel.conf配置的最下端写入当前主从的版本,供所有哨兵进行使用
sentinel leader-epoch icoding-master 1
sentinel known-replica icoding-master 127.0.0.1 7002
sentinel known-replica icoding-master 127.0.0.1 6379
sentinel known-sentinel icoding-master 127.0.0.1 26379 ce3608694909e996b280e8672750b2bd5522945f
sentinel known-sentinel icoding-master 127.0.0.1 26382 a2f203e003ce891a08580104dc2b49a4f6ae187e
sentinel current-epoch 1
故障通知机制
# sentinel notification-script <master-name> <script-path>
# 当我们master出现sdown(主观失效)和odown(客观失效)都会触发
# 会传递两个参数,具体参数值看原sentinel.conf 的注释
sentinel notification-script icoding-master /usr/local/redis/nofity.sh
# sentinel client-reconfig-script mymaster /var/redis/reconfig.sh
# 会带有一些参数:主从切换新旧地址的参数
# <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port>
sentinel client-reconfig-script icoding-master /usr/local/redis/configer.sh
故障转移过程中的问题
-
异步复制的时候,master的数据还没有复制给slave,这个时候哨兵切换slave成为master后就会丢失这些数据(新master会把他的数据同步到其他slave:清空其他slave进行同步)
-
脑裂:哨兵的网络和master断开了,但我们master还在运行,这个时候客户端写入旧master的时候就会丢失
old-master<–>client 是连接的,这个时候old-master就没有slave,可以通过以下两个配置来缓解
- min-replicas-to-write 2
- min-replicas-max-lag 10
new-master—slave1/slave2
注意点
springboot配置redis连接的是哨兵地址,不是redis的主从地址
spring:
redis:
host: 127.0.0.1
password: icoding
sentinel:
master: icoding-master
nodes: 39.99.199.5:26379,39.99.199.5:26381,39.99.199.5:26382
主从模式+哨兵模式,每次重启前一定要检查:
-
每个redis节点的redis.conf的replicaof参数是否正确
-
每个哨兵节点的sentinel.conf的monitor监控的redis主节点是否配置正确,并清除文件最后生成的版本信息,
云服务器要注意使用公网ip,端口策略是否已配置好。