 弹吉他的兔子
弹吉他的兔子
0. Redis分布式集群搭建
提问:
我们前面讲主从,讲哨兵体现出Redis分布式缓存的特性没?
背景:
主从复制(哨兵),虽然主从能提升读的并发,但是单个master容量是有限的,内存数据达到一定程度就会有瓶颈,无论多少套主从,master的容量都是最终的瓶颈
如何解决:
需要支持内存的水平扩展了,这个时候就需要使用集群了,包含了前面讲的主从,故障转移,监控。
集群解决的问题
- 高可用
- 高并发
- 访问/存储水平扩展
Redis集群配置
# 批量删除旧的redis进程
pkill redis
# redis集群至少三主三从
cd /usr/local/redis-cluster
mkdir 8001
mkdir 8002
mkdir 8003
mkdir 8004
mkdir 8005
mkdir 8006
# redis.conf
# 单机配置
daemonize yes
dir /usr/local/cluster/8001
bind 0.0.0.0
requirepass icoding
masterauth icoding #集群创建会自动搭建主从关系,所以不要手工配置replicaof
port 8001
pidfile /var/run/redis_8001.pid
# 开启集群配置
cluster-enabled yes
# 集群每个节点都需要的配置文件
cluster-config-file nodes-8001.conf
# master超时时间,超过后主备切换
cluster-node-timeout 3000
# 开启AOF
appendonly yes
# 批量修改文件端口
.,$ s/8001/8006/g
# 整个批处理文件
chmod 777 cluster.sh
redis-server /usr/local/redis-cluster/8001/redis.conf
redis-server /usr/local/redis-cluster/8002/redis.conf
redis-server /usr/local/redis-cluster/8003/redis.conf
redis-server /usr/local/redis-cluster/8004/redis.conf
redis-server /usr/local/redis-cluster/8005/redis.conf
redis-server /usr/local/redis-cluster/8006/redis.conf
搭建集群
# Redis 3.x开始有集群,redis-trib.rb
# Redis 5.x使用redis-cli就可以了
# 集群创建的命令
# --cluster-replicas 1 每个master有几个slave
redis-cli -a icoding --cluster create 127.0.0.1:8001 127.0.0.1:8002 127.0.0.1:8003 127.0.0.1:8004 127.0.0.1:8005 127.0.0.1:8006 --cluster-replicas 1
# 查看集群信息
redis-cli -a icoding --cluster check 127.0.0.1:8001
# 查看集群命令帮助
redis-cli -a icoding --cluster help
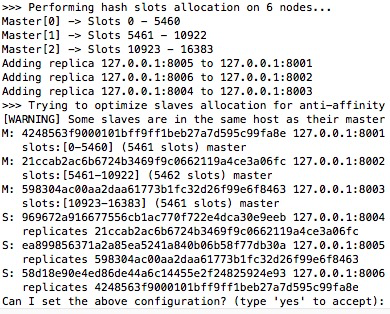
问题:
set key value 所有节点都写的1,写一个节点的2
登录8001节点 set key value 是否一定写入8001,一定1,不一定2
(error) MOVED 12539 127.0.0.1:8003
# 报这个错误的原因是我们以单机方式登录,而不是集群方式
# 单机登录节点
redis-cli -a icoding -p 8001
# 集群登录节点
redis-cli -c -a icoding -p 8001
set key value
get key
127.0.0.1:8001> cluster info
127.0.0.1:8001> cluster nodes
127.0.0.1:8001> keys * # 在集群状态下只能拿到当前节点的所有数据
#-> Redirected to slot [12539] located at 127.0.0.1:8003
Slot槽点
Slot就是支持分布式存储的核心
Redis集群创建后会创建16384个slot(slots不能改就是16384个),并且根据集群的master数据平均分配给master
- 如果有3个master,16384/3=(大约)5460个
- 当你往redis集群中插入数据时,数据只存一份,不一定在你登录节点上,redis集群会使用crc16(key)mod16384来计算这个key应该放在那个hash slot中
- 获取数据的时候也会根据key来取模,就知道在哪个slot上了,也就能redirect了
- 一个slot其实就是一个文件夹,就能存很多key
集群如何实现分布式
-
每个master只保存mod后的slot数据
-
如果要扩展,再加入一个,只需要给这个新节点再分一些slot就行了,但注意无论多少个node,slots总数不变都是16384
-
8g(2460),8g(2460),8g(2460),这个时候加入一个16g(4000) 16g(5000):total-16384
-
slot移动,slot里的数据也跟着移动
-
一个master节点是否内存装满,是slots数量多少还是slot里存放的文件多少导致的?
是文件
集群的搭建建议
- 建议是奇数个,至少3个master节点
- 主从切换:节点间会相互通信,一半以上的节点ping不通某个节点,就认为这个master挂了,这个时候从节点顶上
- 什么时候整个集群不可用
- 如果集群中任意master挂掉,且没有slave顶上,集群就进入fail状态
- 如果超半数以上的master挂掉,无论是否有slave,集群都进入fail状态
- 如果单点单机fail,单机重启后直接利用redis启动命令,重启后会自动回到集群中
- Redis cluster全部宕机后重启会自动恢复集群状态
新增节点Master/Slave
#add-node new_host:new_port existing_host:existing_port
# --cluster-slave
# --cluster-master-id <arg>
# 新增主节点
redis-cli -a icoding --cluster add-node 127.0.0.1:8007 127.0.0.1:8001
# 加入后可以通过cluster nodes来查看
127.0.0.1:8001> cluster nodes
# 给8007分配slot
# --cluster-from 从哪个节点来分配slot,这里只能写node_id,就是cluster nodes获得id,from可以是一个节点也可以是多个节点
# --cluster-to 到8007节点,同样是node_id
# --cluster-slots 从from节点一共分多少slot,并且from中的node是平均分这个总数的 4096/3
# --cluster-yes 不用提示直接执行
redis-cli -a icoding --cluster reshard 127.0.0.1:8001 --cluster-from 4248563f9000101bff9ff1beb27a7d595c99fa8e,21ccab2ac6b6724b3469f9c0662119a4ce3a06fc,598304ac00aa2daa61773b1fc32d26f99e6f8463 --cluster-to 75b831369eedd8b5fe0aee4b2819f573ae0592a2 --cluster-slots 4096 --cluster-yes
# 给8007增加8008的slave节点
redis-cli -a icoding --cluster add-node 127.0.0.1:8008 127.0.0.1:8001 --cluster-slave --cluster-master-id 75b831369eedd8b5fe0aee4b2819f573ae0592a2
节点下线
场景:5组Redis,10个节点,要改成3组,6个节点
# 下线节点,现有考虑把slots分给其他节点,这就是在做数据迁移
# 我这一次分配,也可以分批移动给多个节点,我要下架8001/8006
redis-cli -a icoding --cluster reshard 127.0.0.1:8002 --cluster-from 4248563f9000101bff9ff1beb27a7d595c99fa8e --cluster-to 21ccab2ac6b6724b3469f9c0662119a4ce3a06fc --cluster-slots 4096 --cluster-yes
# 检查一下8001的slot是否全部转移走
127.0.0.1:8002> cluster nodes
# 删除8001节点,这里的节点建议写成删除节点
redis-cli -a icoding --cluster del-node 127.0.0.1:8001 4248563f9000101bff9ff1beb27a7d595c99fa8e
# 删除8006节点,这里的节点建议写成删除节点
redis-cli -a icoding --cluster del-node 127.0.0.1:8006 58d18e90e4ed86de44a6c14455e2f24825924e93
线上保险操作
1、先把集群中的每个节点的RDB,AOF文件备份
2、复制一套同设备和参数的集群,把数据恢复到里面,演练一下(如果可以把演练的结果转正更好)
3、演练没有问题,这个时候进行操作
1. Redis-Cluster常用命令使用
# redis-cli --cluster查看帮助
redis-cli --cluster help
# 给新加入的node分配slot,all代表所有master节点
redis-cli -a icoding --cluster reshard 127.0.0.1:8001 --cluster-from all --cluster-to 60709ef9ee8238811115c38970468af8b611643a --cluster-slots 4000 --cluster-yes
# cluster命令,是执行在redis-cli,一定要先登录到集群中
# 新增master节点
cluster meet 127.0.0.1 8007
# 使用rebalance命令来自动平均分配slot
# --cluster-threshold 1 只要不均衡的slot数量超过1,就触发rebanlance
# --cluster-use-empty-masters 没有slot槽点的节点也参数均分
redis-cli -a icoding --cluster rebalance 127.0.0.1:8001 --cluster-threshold 1 --cluster-use-empty-masters
# cluster命令,是执行在redis-cli,一定要先登录到集群中
# 新增slave节点
# REPLICATE <node-id> -- Configure current node as replica to <node-id>.
# 前提是这个副本节点要先在集群中
cluster meet 127.0.0.1 8008
# 加入后切换到新增的slave 8008
cluster replicate 60709ef9ee8238811115c38970468af8b611643a
2. Springboot整合集群访问
spring:
redis:
password: icoding
cluster:
nodes: 127.0.0.1:8001,127.0.0.1:8002,127.0.0.1:8003,127.0.0.1:8004,127.0.0.1:8005,127.0.0.1:8006,127.0.0.1:8007,127.0.0.1:8008
3.Redis性能监控
# redis-benchmark检查redis的并发性能的
# -c 100个连接
# -n 500个请求
# 主要是测试redis主机的一个本地性能
redis-benchmark -h 127.0.0.1 -p 8001 -a icoding -c 100 -n 500
slowlog慢查询日志
# redis.conf配置
# 设置慢查询的时间下限,超过多少微秒的进行记录
slowlog-log-slower-than 10000
# 慢产讯对应的日志长度,单位:命令数
slowlog-max-len 128
slowlog慢查询日志查看
# redis-cli客户端下
# 查看慢查询
127.0.0.1:6379> slowlog get
# 获取慢查询条目
127.0.0.1:6379> slowlog len
# 重置慢查询日志
127.0.0.1:6379> slowlog reset
4. Redis缓存穿透解决方案
缓存穿透的场景
get传参数,参数一般是id,如果这个id是一个无效id
String key = request.getParameter("key");
List<BuyCart> list = new ArrayList();
//习惯性会用json来保存结构数据
String cartJson = redisOperator.get(key);
if(StringUtls.isBlank(cartJson)){
//redis里面没有保存这个key
list = cartService.getCarts(key);
//从数据库里查出来然后写入redis
if(list!=null&&list.size()>0){
redisOperator.set("cartId:"+key,JsonUtils.objectToJson(list));
}else{
redisOperator.set("cartId:"+key,JsonUtils.objectToJson(list),10*60);
}
}else{
//redis里有值
list = JsonUtils.jsonToList(list));
}
假如我系统被人攻击了,如何攻击?
get传参数,传N个无效的id
5.布隆过滤器bloomfilter
之前讲了一个hyperloglog,保存不重复的基数个数:比如记录访问的UV,我只需要个数
场景描述
比如我们一个新闻客户端,不断的给用户推荐新的新闻,推荐去重,还要高效,比如抖音
这个时候你想到Redis,能实时推送并快速去重
用户A:1 2 3 4 5 6(2 7 9)每个用户都应该有一个浏览的历史记录:一旦时间长了,是不是数据量就非常大
如果用户量也很大怎么办?
这个时候我们的布隆过滤器就登场了
总结一下
- 布隆过滤器可以判断数据是否存在
- 并且可以节省90%以上的存储空间
- 但匹配精度会有一点不准确(涉及空间和时间的转换:0.01%)
布隆过滤器的运行场景
它本身是一个二进制的向量,存放的就是0,1
比如我们新建一个长度为16的布隆过滤器

所以布隆过滤器的精度是取决于bloom的存储大小的的,如果长度越大,精度就越高
布隆过滤器的特征
- 精度是取决于bloom的存储大小的的,如果长度越大,精度就越高
- 只能判断数据是否一定不存在,而无法判断数据是否一定存在
- bloom的存储节点不能删除,一旦删除就影响其他节点数据的特征了
布隆过滤器存储的节点数据一定是历史数据
布隆过滤器的使用
到入google的guava的POM
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.2-jre</version>
</dependency>
BloomFilter的代码测试
public class BloomFilterTest {
public static void main(String[] args) {
//字符集,bf的存储长度一般是你要存放的数据量1.5-2倍,期望的误判率
BloomFilter bf = BloomFilter.create(Funnels.stringFunnel(Charset.forName("utf-8")),100000,0.0001);
for(int i=0;i<100000;i++){
bf.put(String.valueOf(i));
}
int flag = 0;
for(int i=100000;i<200000;i++){
if(bf.mightContain(String.valueOf(i))){
flag++;
}
}
System.out.println("误判了:"+flag);
}
}
Redis集成布隆过滤器
Redis官方提供的布隆过滤器支持的是到了Redis4.x以后提供的插件功能
# 下载bloomfilter的插件
wget https://github.com/RedisLabsModules/rebloom/archive/v1.1.1.tar.gz
# 解压
make
# 去到redis的配置文件对我们的过滤器进行添加
loadmodule /usr/local/software/RedisBloom-1.1.1/rebloom.so
# 创建bloomfilter并添加一个值
# 默认过滤器长度为100,精度0.01 : MBbloom
bf.add users value1 #可以不断添加到同一个key
bf.madd users value1 value2
# 判断一个值是否存在
bf.exists users value1
# 判断多个值是否存在
bf.mexists users value1 value2 value3
# 手工建立bloomfliter的配置
bf.reserve userBM 0.001 10000
Java集成Redis BloomFilter
先导入依赖
<dependency>
<groupId>com.redislabs</groupId>
<artifactId>jrebloom</artifactId>
<version>1.2.0</version>
</dependency>
Java的bloomfilter调用
import io.rebloom.client.Client;
public class RedisBloomFilterTest {
public static void main(String[] args) {
Client bloomClient = new Client("127.0.0.1",6379);
//先创建bloomfilter
bloomClient.createFilter("userFilter",1000,0.001);
bloomClient.add("userFilter","gavin");
System.out.println("bloomfilter:"+bloomClient.exists("userFilter","gavin"));
}
}
布隆过滤器的使用总结
- 布隆过滤器如果初始值过大会占用较大空间,过小会误差率高,使用前估计好元素数量
- error_rate越小,占用空间就越大
- 只能判断数据是否一定不存在,而无法判断数据是否一定存在
- 可以节省90%的存储空间
- 但匹配精度会有一点不准确(涉及空间和时间的转换:0.01%)
- 布隆过滤器只能add和exists不能delete
help @generic
6. Redis雪崩解决方案
什么是Redis雪崩
-
雪崩是基于数据库,所有原理应该到Redis的查询全到DB,并且是同时到达
- 缓存在同一时间大量的key过期(key)
- 多个用户同时请求并到达数据,而且这个请求只有一个是有意义的,其他的都是重复无用功
Redis雪崩解决方案
- 缓存永不过期:冰封了
- 过期时间错开(可以在key创建时加入一个1-10分钟的随机数给到key)
- 多缓存数据结合(不要直接打到DB上,可以在DB上再加一个搜索引擎)
- 在代码里通过锁解决(synchronized,分布式锁zookeeper)
7. Redisson实现分布式锁机制
分布式锁的核心
- 加锁
- 锁删除:一定不能因为锁提前超时导致删除非自己的锁
- 锁超时:如果业务没有执行完就应该给锁延时
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.12.1</version>
</dependency>
Java实现代码
@RestController
public class TestRedisson {
@Autowired
RedissonClient redissonClient;
@GetMapping("redission")
public String testRedison(){
RLock userLock = redissonClient.getLock("userid:1223");
System.out.println("get Lock");
try{
// 如果有锁,等待5秒,如果拿到了锁持有30秒
userLock.tryLock(5,30, TimeUnit.SECONDS);
System.out.println("获取到锁");
TimeUnit.SECONDS.sleep(20);
System.out.println("88");
}catch (InterruptedException e){
e.printStackTrace();
}finally {
System.out.println("释放锁");
userLock.unlock();
}
return "redission";
}
}
启动项目,测试访问http://localhost:8080/redission
后台输出:
redisson默认就是加锁30秒,建议也是30秒以上,默认的lockWatchdogTimeout会每隔10秒观察一下,待到20秒的时候如果主进程还没有释放锁,就会主动续期30秒
8. Redis分区
分区是分割数据到多个Redis实例的处理过程,因此每个实例只保存key的一个子集
查询路由(Query routing) 的意思是客户端随机地请求任意一个redis实例,然后由Redis将请求转发给正确的Redis节点。Redis Cluster实现了一种混合形式的查询路由,但并不是直接将请求从一个redis节点转发到另一个redis节点,而是在客户端的帮助下直接redirected到正确的redis节点。
优点
- 一个key的数据存储到多个redis节点,可以构建更大的数据库
- 通过多核和多台计算机,允许我们扩展计算能力
缺点
- 涉及多个key的操作通常不会被支持,举例来说,当两个set映射到不同的redis实例上时,你就不能对这两个set执行交集操作。
- 同时操作多个Key,就不能使用Redis事务了。
- 当使用分区时,数据处理较为复杂,比如你需要处理多个rdb/aof文件,并且从多个实例和主机备份持久化文件。
9. Redis涉及的面试题分析
-
什么是 Redis?
看第一课,redis的介绍以及它的优势的劣势,他的单线程机制
-
Redis 的数据类型?
string(json)、hash(购物车)、list(队列、栈,lpush,rpop)、set(去重集合)、zset(有权重的排序集合)
-
使用 Redis 有哪些好处?
- 速度快,内存数据库
- 丰富的数据类型
- 支持事务
- 丰富的特性操作:比如缓存和过期时间
-
Redis 相比 Memcached 有哪些优势?
看第一课,对比中有
-
Memcached 与 Redis 的区别都有哪些?
看第一课,对比中有
-
Redis 是单进程单线程的吗?为何它那么快那么高效?
多路复用:多路是指多个网络连接,复用是指复用一个线程
-
一个字符串类型的值能存储最大容量是多少?
512MB,但是不建议存储这么大,复用会阻塞线程
-
Redis 的持久化机制是什么?各自的优缺点?
RDB、AOF
- RDB是定时全量备份,每次都会讲内存中的所有数据写入文件,所以备份比较慢
- 会fork一个新进程进行快照存储
- RDB数据无法保存备份到宕机间的数据:bgsave 1/save 2:bgsave
- AOF的备份相当于一个操作日志备份,只记录写命令,并以追加的方式写入文件
- 同数据量下AOF比RDB要大,这个时候会根据我们配置的重写规则触发fork来压缩AOF文件
- 同时开启RDB和AOF时,优先使用AOF,如果线上没有开AOF,config set appendfile yes
-
Redis 常见性能问题和解决方案有哪些?
建议关闭master的RDB,开启AOF,slave开RDB
master->slave->slave->slave
-
Redis 过期键的删除策略?
定时删除、惰性删除
-
Redis 的回收策略(淘汰策略)?
内存的淘汰机制
-
为什么Redis 需要把所有数据放到内存中?
读写速度快
-
Redis 的同步机制了解么?
第一次连接是全量,后面是增量,RDB同步到slave
-
Pipeline 有什么好处,为什么要用 Pipeline?
将Redis的多次查询放到一起,节省带宽
-
是否使用过 Redis 集群,集群的原理是什么?
Redis Sentinel:HA
Redis Cluster:HA、分布式
-
Redis 集群方案什么情况下会导致整个集群不可用?
- master节点挂掉,并没有slave顶上,slot在线不足16384个
- 半数以上master挂了,无论是否有slave都会fail
-
Redis 支持的 Java 客户端都有哪些?官方推荐用哪个?
jedis、redisson、lettuce,推荐redisson
-
Jedis 与 Redisson 对比有什么优缺点?
redisson更希望大家关注业务,jedis相当于一个java版的redis-cli
-
Redis 如何设置密码及验证密码?
配置文件
auth -a
-
说说 Redis 哈希槽的概念?
redis cluster的时候会通过crc16校验key放在16384个slot中其中一个,get时会根据crc16算出,如果key不在当前节点会redirect到存放节点
-
Redis 集群的主从复制模型是怎样的?
每个节点都至少是N+1
-
Redis 集群会有写操作丢失吗?为什么?
- 过期key被清理
- 内存不足时,被内存规则清理
- 主库写入数据时宕机
- 哨兵切换时(脑裂)
-
Redis 集群之间是如何复制的?
master节点上数据是不进行复制的
master-slave
- 完整同步
- 部分同步
- 都是异步的
-
Redis 集群最大Slot个数是多少?
16384
-
Redis 集群如何选择数据库?
select 0-15
单机默认:16个数据库,可以修改
集群:只有1个数据库
-
怎么测试 Redis 的连通性?
发一个ping 返回 pong
-
怎么理解 Redis 事务?
开我们课件,原子性,watch乐观锁
-
Redis 事务相关的命令有哪几个?
multi、exec、discard、watch
-
Redis key 的过期时间和永久有效分别怎么设置?
expire、persist
-
Redis 如何做内存优化?
尽量使用hash来进行数据结构搭建,而不是string的json
-
Redis 回收进程如何工作的?
取决于maxmemory的设置,如果没有设置,到内存最大值触发maxmemory-policy
-
都有哪些办法可以降低 Redis 的内存使用情况呢?
好好利用hash、list、set、zset
-
Redis 的内存用完了会发生什么?
maxmeory-policy
-
一个 Redis 实例最多能存放多少的 keys?List、Set、Sorted Set他们最多能存放多少元素?
理论上是2的32次方个,其实一般受限于内存大小
-
MySQL 里有 2000w 数据,Redis 中只存 20w 的数据,如何保证Redis 中的数据都是热点数据?
- 业务场景
- 限制内存大小,主动触发allkeys-lru
-
Redis 最适合的场景是什么?
- session会话保存
- 页面数据缓存
- 队列list,只能支持一个消费者
- 计数器
- 订阅机制
-
假如 Redis 里面有 1 亿个 key,其中有 10w 个 key 是以某个固定的已知的前缀开头的,如何将它们全部找出来?
keys abc*
-
如果有大量的 key 需要设置同一时间过期,一般需要注意什么?
可能会雪崩
在加入key 的过期时间时,增加一个随机时间点,让key过期分散一些
-
使用过 Redis 做异步队列么,你是怎么用的?
lpush/rpop:只能支持一个消费者
sub/pub:可以支持多人订阅
-
使用过 Redis 分布式锁么,它是什么回事?
加锁、释放锁、锁超时(redisson)
-
如何预防缓存穿透与雪崩?
看今天上面的内容