 弹吉他的兔子
弹吉他的兔子
1、同时使用中文和拼音分词器
- 拼音分词器
- ik中文分词
# 下载拼音分词器
# 新增分词器后,先加的记录是不能被匹配出来的,要后加的记录才能匹配
# elasticsearch-analysis-pinyin-7.5.2.zip
# 1、下载分词器 Github: elasticsearch-analysis-pinyin
wget https://github.com/medcl/elasticsearch-analysis-pinyin/releases/download/v7.5.2/elasticsearch-analysis-pinyin-7.5.2.zip
# 2、解压分词器到ES的plugins目录下
unzip elasticsearch-analysis-pinyin-7.5.2.zip -d /usr/local/elasticsearch-7.5.2/plugins/pinyin
#3、重启es,测试分词器
GET /_analyze
{
"text":"艾编程",
"analyzer":"pinyin"
}
# 需求场景:我们需要对一个字段既可以进行中文搜索,也可以进行拼音搜索
# index的常规设置mapping
# 一个字段可以给自己设置子字段来增加新的type和分词器
# mapping可以后期修改的
POST /index_customer/_mapping
{
"properties": {
"id": {
"type": "long"
},
"age": {
"type": "integer"
},
"username": {
"type": "keyword"
},
"nickname": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"pinyin": {
"type": "text",
"analyzer": "pinyin"
},
"keyword":{
"type":"keyword",
"ignore_above": 256
}
}
},
"consume": {
"type": "float"
},
"desc": {
"type": "text",
"analyzer": "ik_max_word"
},
"sex": {
"type": "byte"
},
"birthday": {
"type": "date"
},
"city": {
"type": "keyword"
},
"faceimg": {
"type": "text",
"index": false
}
}
}
# 搜索的时候同时支持中文,拼音
GET /index_customer/_search
{
"query":{
"multi_match":{
"query": "chuanzhang",
"fields":["nickname","nickname.pinyin"]
}
}
}
# 在前端调用声明分词器
GET /index_customer/_search
{
"query": {
"match": {
"nickname": {
"query": "太阳",
"analyzer": "ik_max_word"
}
}
}
}
看elasticsearch里安装成功的插件
[esuser@helloworld elasticsearch-9200]$ cd plugins/
[esuser@helloworld plugins]$ ls
ik pinyin
2、深度分页问题分析与解决
什么是深度分页
深度分页就是我们搜索的深浅度,比如第1页,第2页,第100页都是比较浅的,如果第1w页,第2w页这就比较深。
先看一下MySQL
select * from im_order limit 100000,30;
这样就会非常慢,这就涉及深度分页,就会比较慢
慢的原因是什么:MySQL的limit m,n的工作原理是先读取符合where条件的m+n的记录,要把这些数据全拿到内存中,然后抛弃前m条,返回后面的n条,所以m越大,偏移量就越大,性能就越差,大部分ORM框架都是如此
select * from im_order where id>100000 limit 30;
但前提是:
- 主键id一定要连续,否则数据就会出现不连贯的情况
- 不好进行总页数的计算了,只能进行上一页和下一页的操作了
- 进行这样的优化,需要记住上次的点位
解决方案
上一页 1 2 3 4 5 6 7 8 9 10 下一页
ES如何处理深度分页
GET /index_customer/_search
{
"query": {
"match_all": {}
},
"from":0,
"size":12
}
GET /index_customer/_search
{
"query": {
"match_all": {}
},
"from":9999,
"size":10
}
# Result window is too large, from + size must be less than or equal to: [10000] but was [10009]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting.
elasticsearch默认也不允许你查询10000条以后的数据,那么拿后面10条数据的流程如下:
-
ES中每个分片存储不同的数据,所有分片总和是这个集群的完整数据
-
去每个分片上都要拿10009条,然后集合在一起,如果3个分片:3*10009条数据,针对30027进行排序_score,最终取到你想要的10条
-
因此ES默认不支持10000条以上的查询
如果恰巧你的数据就只有12000条
# 先看下这个属性
GET /index_customer/_settings
# 修改深度
PUT /index_customer/_settings
{
"index.max_result_window": "20000"
}
# 注意,这种方式救急可以,但不要拿来常用,这是缓兵之计
滚动搜索scroll
介绍一个滚动搜索
- scroll可以先查询出一些数据,然后依次往下查询
- 在第一次查询的时候会有一个滚动id,这个id就是一个锚标记,每次都需要记录和使用这个锚标记
- 每次搜索都是基于历史的数据快照,查询数据期间,如果数据有变更,快照数据不变
如何使用
# 这个m就是滚动查询的上下文时间,m是分钟的意思
# 这是第一次查询,第一次查询需要设置偏移量:size,就是页容量
POST /index_customer/_search?scroll=1m
{
"query": {
"match_all": {}
},
"sort": ["_doc"],
"size": 3
}

第二次,第三次
# 第二次第三次滚动需要将每次返回的滚动id_scroll_id填入当次查询中,不用写查询条件
# 不要写index名,直接写_search
# 1m是滚动数据的过期时间,每次都要设置,单位是m分钟
POST /_search/scroll
{
"scroll": "1m",
"scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAABcWc2d3clU2QzRSMXFvVjIySHdzZmgzUQ=="
}
如果请求指定了聚合数据(aggregation),仅第一次数据才会包含聚合结果
最大打开scroll上下文数
elasticsearch7.x 开始加上了软限制,max_open_scroll_context默认为500个,这个参数可以理解为数据库可用活跃连接数,虽然scroll id有一个存活时限,过期后会自动被清理,但在高并发情况下还是会有可能达到限制,从而报错
Trying to create too many scroll contexts. Must be less than or equal to 500
可以发送请求来查看es集群的open_context使用情况
GET _nodes/stats/indices/search
查询相关参数解析
"indices": {
"search": {
"open_contexts": 344, //正在打开的查询上下文个数
"query_total": 2040238734, //查询出来的总数据条数
"query_time_in_millis": 123880939, //查询阶段所耗费的时间
"query_current": 2, //当前正在查询个数
"fetch_total": 956587, //
"fetch_time_in_millis": 305711, //Fetch阶段总耗时时间
"fetch_current": 0,
"scroll_total": 1804431262, //通过scroll api查询数据总条数
"scroll_time_in_millis": 16431383028, //通过scroll api总耗时时间
"scroll_current": 0, //当前滚动API调用次
"suggest_total": 0,
"suggest_time_in_millis": 0,//suggest总耗费时间
"suggest_current": 0 //正在执行suggest api的个数
}
}
报错的解决办法,调大打开查询上下文个数:
curl -X PUT http://ip:9200/_cluster/settings -H 'Content-Type: application/json' -d'{
"persistent" : {
"search.max_open_scroll_context": 5000
},
"transient": {
"search.max_open_scroll_context": 5000
}
}
使用查询后,手动清除scroll id
ES 7.15后,官方建议java客户端使用 transportClient
//清除游标
if (searchResponse.getScrollId()!=null && !searchResponse.getScrollId().equals("")){
ClearScrollRequest clearScrollRequest = new ClearScrollRequest();
clearScrollRequest.addScrollId(searchResponse.getScrollId());
ActionFuture<ClearScrollResponse> actionFuture = transportClient.clearScroll(clearScrollRequest);
if (!actionFuture.actionGet().isSucceeded()){
logger.error(actionFuture.toString());
}
}
我习惯使用restHighLevelClient
if (searchResponse.getScrollId() != null && !searchResponse.getScrollId().equals("")){
ClearScrollRequest clearScrollRequest = new ClearScrollRequest();
clearScrollRequest.addScrollId(searchResponse.getScrollId());
ClearScrollResponse clearScrollResponse = restHighLevelClient.clearScroll(clearScrollRequest,RequestOptions.DEFAULT);
if (!clearScrollResponse.isSucceeded()){
logger.info(clearScrollResponse.toString());
}
}
查询时,每次返回的游标都是一样的,所以只需要最后删除一次就可以
3、批量文档操作
批量查询doc
# 只查一个
GET /index_customer/_doc/1001
# 通过DSL可以进行批量查询
POST /index_customer/_search
{
"query":{
"ids":{
"type":"_doc",
"values":["1001","1009","1010"]
}
},
"_source":["id","username","nickname","desc"]
}
使用_mget来进行查询
POST /index_customer/_doc/_mget
{
"ids": ["1001","1009","1010"]
}
批量操作bulk
基本语法
{ action: { metadata}}\n
{ request body }\n
{ action: { metadata}}\n
{ request body }\n
{ action: { metadata}}\n
{ request body }\n
...
- { action: { metadata}}:代表批量操作的类型,可以新增,删除,修改
- \n:每行必须是回车换行,不要用json解析器来格式
- { request body }:就是你的具体doc数据
- post提交的content-type是application/json
批量操作的类型
action必须是以下选项之一
- create:文档不存在则创建,存在则报错,但发生异常不会影响其他行的数据导入
- index:文档不存在则创建,存在则覆盖
- update:部分更新一个文档
- delete:批量删除
create/index操作
# 不用加索引名,直接在路径里写_bulk
POST /_bulk
{"create":{"_index":"index_customer","_type":"_doc","_id":"1013"}}
{"id":1013,"age":30,"username":"wangge","nickname":"大哥就是棒","consume":16899.99,"desc":"就喜欢研究技术,非常喜欢和大家交流","sex":1,"birthday":"1990-10-22","city":"杭州","faceimg":"https://www.icodingedu.com/img/customers/1013/logo.png"}
{"create":{"_index":"index_customer","_type":"_doc","_id":"1014"}}
{"id":1014,"age":28,"username":"lichangming","nickname":"永远光明","consume":14899.99,"desc":"非常喜欢和大家交流Java技术和架构心得","sex":1,"birthday":"1992-09-22","city":"北京","faceimg":"https://www.icodingedu.com/img/customers/1014/logo.png"}
# 注意最后一行也必须有回车
POST /_bulk
{"index":{"_index":"index_customer","_type":"_doc","_id":"1013"}}
{"id":1013,"age":30,"username":"wangge","nickname":"大哥就是棒","consume":16899.99,"desc":"就喜欢研究技术,非常喜欢和大家交流","sex":1,"birthday":"1990-10-22","city":"杭州","faceimg":"https://www.icodingedu.com/img/customers/1013/logo.png"}
{"index":{"_index":"index_customer","_type":"_doc","_id":"1014"}}
{"id":1014,"age":28,"username":"lichangming","nickname":"永远光明","consume":14899.99,"desc":"非常喜欢和大家交流Java技术和架构心得","sex":1,"birthday":"1992-09-22","city":"北京","faceimg":"https://www.icodingedu.com/img/customers/1014/logo.png"}
也可以在index资源路径下来进行操作
# doc类型可以去掉 POST /index_customer/_doc/_bulk
POST /index_customer/_bulk
{"index":{"_id":"1013"}}
{"id":1013,"age":30,"username":"wangge","nickname":"大哥就是棒","consume":16899.99,"desc":"就喜欢研究技术,非常喜欢和大家交流","sex":1,"birthday":"1990-10-22","city":"杭州","faceimg":"https://www.icodingedu.com/img/customers/1013/logo.png"}
{"index":{"_id":"1014"}}
{"id":1014,"age":28,"username":"lichangming","nickname":"永远光明","consume":14899.99,"desc":"非常喜欢和大家交流Java技术和架构心得","sex":1,"birthday":"1992-09-22","city":"北京","faceimg":"https://www.icodingedu.com/img/customers/1014/logo.png"}
# 注意最后一行也必须有回车
update/delete操作
批量更新
POST /index_customer/_doc/_bulk
{"update":{"_id":"1013"}}
{"doc":{"nickname":"一只花骨朵"}}
{"update":{"_id":"1014"}}
{"doc":{"desc":"对架构师课程感兴趣,所以报名艾编程学习"}}
# 注意最后一行也必须有回车
批量删除
POST /index_customer/_doc/_bulk
{"delete":{"_id":"1013"}}
{"delete":{"_id":"1014"}}
# 注意最后一行也必须有回车
所有批量的操作:create、index、update、delete都可以放在一起执行
需要注意的点
-
由于批量操作是加载到内存中的,如果值比较多,会比较慢
-
所有操作在一起只需符合语法规则,内容可以多样
4、Elasticsearch集群构建
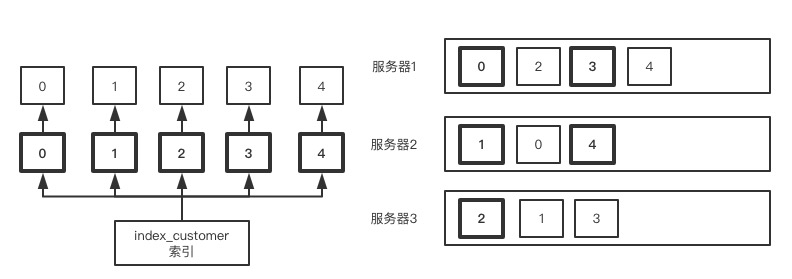
分片原理分析
分布式搜索引擎,如果是单机,那既不能HA,也不能实现分布式
- HA
- 海量数据的水平扩展
- 高并发访问
分片机制
-
通俗来讲就是一个放数据的盒子
- 每个索引都会被分片
- 创建索引的时候会要求制定主分片和副本分片的数量,索引创建后,主分片数不能修改,除非reindex重建索引,副本分片则可以随意修改
分片的逻辑
- 副本分片不允许和主分片在同一个机器上
- 主分片挂了,还有副本分片来进行数据访问
- 所以单机的时候,副本分片不会指定机器,是灰色不可用的
集群搭建
在elasticsearch.yml里进行配置
# elasticsearch.yml
# 1、集群名称,每个集群的机器如果要加入同一个集群,这个名字必须一样
cluster.name: icoding-es
# 节点名,这个必须都不一样
node.name: es-node-1
path.data: /usr/local/elasticsearch/esdata # 数据路径
path.logs: /usr/local/elasticsearch/eslogs # 日志路径
http.port: 9200
transport.tcp.port: 9300
# 2、主节点,设置后在主节点挂掉后有机会升级为master
node.master: true
# 数据节点
node.data: true
# 3、配置ip和域名,配置后ES会通过9300-9305的端口进行数据连接,不配置端口,默认就是9300
discovery.seed_hosts: ["192.168.0.146", "192.168.0.147", "192.168.0.148"]
# 集群初始化设置的master节点
cluster.initial_master_nodes: ["es-node-1"]
# 4、允许跨域
http.cors.enabled: true
http.cors.allow-origin: "*"
# 注意不同局域网的服务器搭建ES集群,需要修改以下参数
# 建议线上要在局域网内搭建ES集群,基于安全和数据传输的考虑
# 参考:https://www.jianshu.com/p/a78b9eba0934
# 自己尝试在腾讯云、阿里云服务器上搭建ES集群失败,节点间无法通信
# 可以在一台服务器上开启多个ES实例构建成集群,只需要修改http和tcp的端口,如 es-node-1: 9200/9300,es-node-2: 9201/9301,
# es-node-3: 9202/9302
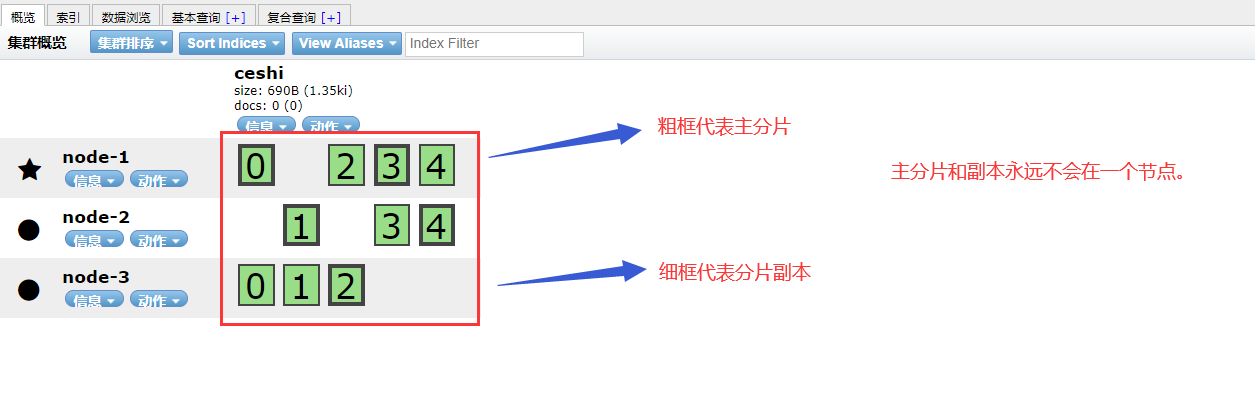 星:代表主节点
星:代表主节点
圆圈:代表从节点
集群配置用户密码访问
# 三个es节点关闭es服务
# 进入es的bin目录
# 1、为集群创建认证机构,依次输入回车(文件使用默认名),密码
[esuser@helloworld bin]$ ./elasticsearch-certutil ca
Please enter the desired output file [elastic-stack-ca.p12]:
Enter password for elastic-stack-ca.p12 :
# 2、为节点颁发证书,回车(文件使用默认名),密码与步骤1的密码相同
# 2.1
[esuser@helloworld bin]$ ./elasticsearch-certutil cert --ca elastic-stack-ca.p12
Enter password for CA (elastic-stack-ca.p12) :
Please enter the desired output file [elastic-certificates.p12]:
Enter password for elastic-certificates.p12 :
Certificates written to /home/esuser/elasticsearch-9200/elastic-certificates.p12
# 2.2 回车(文件使用默认名),密码与步骤1的密码相同
[esuser@helloworld bin]$ ./elasticsearch-keystore add xpack.security.transport.ssl.keystore.secure_password
Enter value for xpack.security.transport.ssl.keystore.secure_password:
# 2.3 回车(文件使用默认名),密码与步骤1的密码相同
[esuser@helloworld bin]$ ./elasticsearch-keystore add xpack.security.transport.ssl.truststore.secure_password
Enter value for xpack.security.transport.ssl.truststore.secure_password:
3、多节点配置
将生成的elastic-certificates.p12、elastic-stack-ca.p12文件mv到config目录下,并连同elasticsearch.keystore 文件 scp到其他节点的config目录中。
scp elastic-certificates.p12 elasticsearch.keystore elastic-stack-ca.p12 root@192.168.1.100:/home/wes/elasticsearch-7.6.1/config/

我这里搭建的单机三个节点的伪集群,使用cp命令复制就行
[esuser@helloworld config]$ cp elastic-certificates.p12 elasticsearch.keystore elastic-stack-ca.p12 /home/esuser/elasticsearch-9201/config/
[esuser@helloworld config]$ cp elastic-certificates.p12 elasticsearch.keystore elastic-stack-ca.p12 /home/esuser/elasticsearch-9202/config/
4、开启证书访问
修改三个节点的配置文件elasticsearch.yml,添加下面内容
# --------------------------------- Security -----------------------------------
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: elastic-certificates.p12
http.cors.allow-headers: Authorization,Content-Type # es-header连接需要配置这个
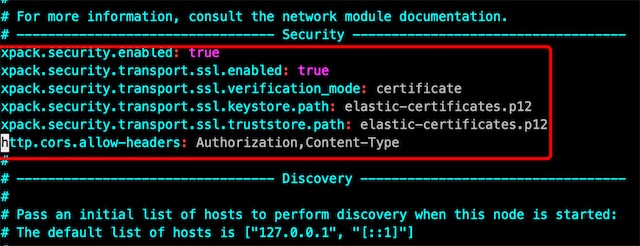
重启3个节点的es服务
5、密码设置
待节点启动完毕之后,进入第一个节点elasticsearch目录,执行以下命令,进行密码设置:
[esuser@helloworld elasticsearch-9200]$ ./bin/elasticsearch-setup-passwords interactive
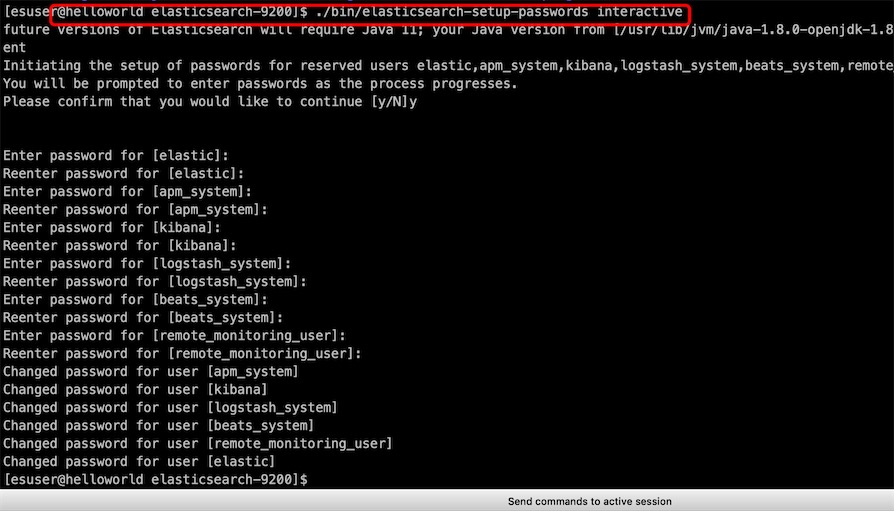
6、访问测试
访问任意一个节点都需要输入elastic的密码
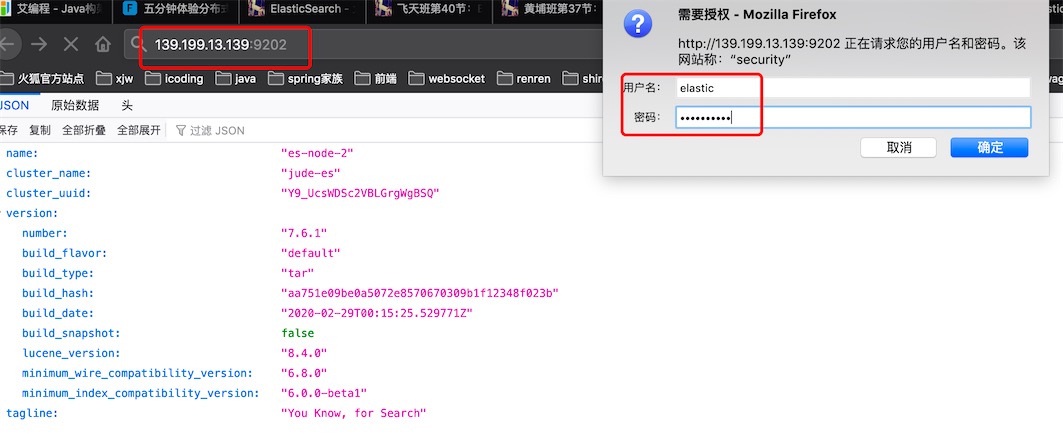
elasticsearch-head访问es集群的用户及密码
url+认证信息方式访问es集群
http://localhost:9100/?auth_user=elastic&auth_password=elastic666
logstash增加访问es集群的用户及密码
output {
if [fields][log_source] == 'messages' {
elasticsearch {
hosts => ["http://192.168.80.104:9200", "http://192.168.80.105:9200","http://192.168.80.106:9200"]
index => "messages-%{+YYYY.MM.dd}"
user => "elastic" # 账号是默认的
password => "elkstack123456" # 密码是上面步骤设置的
}
}
if [fields][log_source] == "secure" {
elasticsearch {
hosts => ["http://192.168.80.104:9200", "http://192.168.80.105:9200","http://192.168.80.106:9200"]
index => "secure-%{+YYYY.MM.dd}"
user => "elastic"
password => "elkstack123456"
}
}
}
kibana组件访问es集群
有两种方法
-
方法1:
配置文件kibana.yml中需要加入用户密码,明文的密码
elasticsearch.username: "elastic" elasticsearch.password: "elastic123456"然后重启kibana服务,再次访问的话就需要输入上述账号密码才能登陆访问了
-
方法2:
通过keystore配置es的加密用户名和密码进行访问
[esuser@helloworld kibana-7.6.1]$ cd bin # 1、创建keystore [esuser@helloworld bin]$ ./kibana-keystore create Created Kibana keystore in /home/esuser/kibana-7.6.1/data/kibana.keystore # 2、设置kibana访问es的用户名 [esuser@helloworld bin]$ ./kibana-keystore add elasticsearch.username Enter value for elasticsearch.username: ******* # 输入用户名 elastic # 3、设置kibana访问es的密码 [esuser@helloworld bin]$ ./kibana-keystore add elasticsearch.password Enter value for elasticsearch.password: **********
节点宕机测试-分片容灾的机制
集群所有Node都启动的状态

我要kill掉es-node-1,es-node-2和es-node-3上的副本分片就升级为主分片
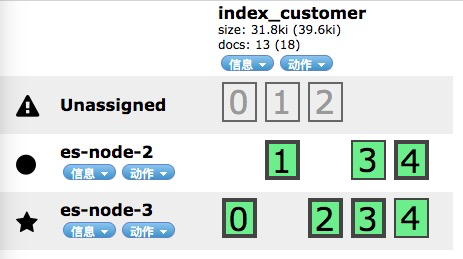
过了一会,刚升级的主分片复制出副本分片
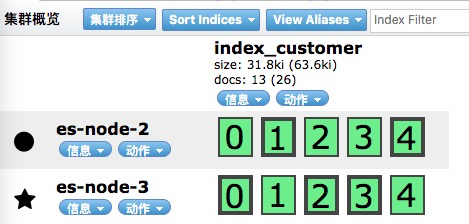
启动刚刚kill掉的es-node-1,数据还没有复制过来

过了一会数据进行了移动,通过9300内部通信端口进行数据的传输的

脑裂问题分析
集群中有一个master节点:相当于一个管理节点
Node:elasticsearch的服务节点,安装ES的机器(主,从)
Index:是我们数据的一个逻辑集合,他拥有数据的结构,以及提前做好的分词内容,主要用来搜索的的对象
Shard:物理分片,进行数据的实际物理存储和管理的地方(主分片数不能修改,但副本分片可以增加)
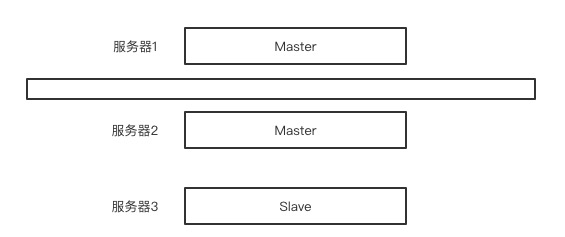
当原来的Master因为网络问题无法和其他slave链接,就出现了其他slave选举出新的master的情况
- 只要最小投票人数1个就能把节点投为master
- 由于和其他节点连接不上,这个节点就把自己投成master
脑裂的解决方案
master主节点应该要经过多个有资格成为master(node.master=true)的节点选举后才能成为新的节点,不是你一个人自己选自己就能决定
-
discovery.zen.minimum_master_nodes=(N/2)+1
- N就是有资格成为master的节点数
- 这个值默认是1
- 在ES7.x以前是这样的
-
在ES7.x版本中,这个参数已经被移除了,这块的内容完全由ES自身做管理,避免了多个脑裂的情况,选举也非常快
文档读写原理
写原理
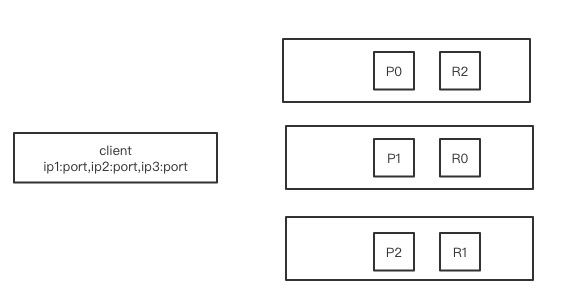
- 客户端连接的时候,首先要连接一个协调节点coordinating node 发送请求
- 协调节点会根据客户端写入的数据来hash判断是写入P0还是P1,P2,只要主分片才能写入数据
- 如果hash后写入到P2分片,会由协调节点来路由转发数据到P2分片
- P2分片数据写入完成后会同步到R2副本分片,会将完成写入的响应返回到协调节点
- 协调节点收到完成操作后返回给客户端,完成了这次写入的操作了
- 客户端每次连接的协调节点coordinating node 都可能会变,也就是每个node都会充当协调节点的角色

读原理
- 客户端读请求会先选择一个协调节点coordinate node
- 由协调节点根据数据的请求hash得知是放在哪个分片上的
- 由于数据在主副本分片上都有,并且数据一模一样,读取操作在主分片和副本分片上是采用轮询的方式,读负载
- 因此副本分片多了后会提升分片的负载能力
- 数据查询完毕后返回document给协调节点,协调节点返回客户端
搜索过程原理
es 最强大的是做全文检索,就是比如你有三条数据:
java真好玩儿啊
java好难学啊
j2ee特别牛Copy to clipboardErrorCopied
你根据 java 关键词来搜索,将包含 java 的 document 给搜索出来。es 就会给你返回:java真好玩儿啊,java好难学啊。过程原理:
- 客户端发送请求到一个 协调节点
coordinate node。 - 协调节点将搜索请求转发到索引所在的shard (
primary shard或replica shard,采取轮询的方式)。 - query phase(查询阶段):每个 shard 分片 将自己的搜索结果(其实就是一些
doc id)返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。 - fetch phase(拿阶段):接着由协调节点根据
doc id去各个节点上拉取实际的document数据,最终返回给客户端。
写的底层原理研究

- 先写入内存 buffer,在 buffer 里的时候数据是搜索不到的;同时将数据写入 translog 日志文件。
- 如果 buffer 快满了,或者到一定时间,就会将内存 buffer 数据
refresh到一个新的segment file中,但是此时数据不是直接进入segment file磁盘文件,而是先进入os cache。这个过程就是refresh,有点类似kafka的Page Cache(页面缓存),其实就是OS的核心缓冲区。 - 每隔 1 秒钟,es 将 buffer 中的数据写入一个新的
segment file( buffer先refresh到os cache,再由os cache 刷到 segment file) ,每秒钟会产生一个新的磁盘文件segment file,这个segment file中就存储最近 1 秒内 buffer 中写入的数据。 - 操作系统里面,磁盘文件其实都有一个东西,叫做
os cache,即操作系统缓存,就是说数据写入磁盘文件之前,会先进入os cache,先进入操作系统级别的一个内存缓存中去。只要buffer中的数据被 refresh 操作刷入os cache中,这个数据就可以被搜索到了。 - 为什么叫es是nrt(
near real-time准实时),就是因为他的每1秒钟refresh一次数据。可以通过 es 的restful api或者java api,手动执行一次 refresh 操作,就是手动将 buffer 中的数据刷入os cache中,让数据立马就可以被搜索到。只要数据被输入os cache中,buffer 就会被清空了,因为不需要保留 buffer 了,数据在 translog 里面已经持久化到磁盘去一份了(每5秒触发一次将os cache的写入操作记录到translog日志文件)。translog 日志文件的作用是什么?你执行 commit 操作之前,数据要么是停留在 buffer 中,要么是停留在 os cache 中,无论是 buffer 还是 os cache 都是内存,一旦这台机器死了,内存中的数据就全丢了。所以需要将数据对应的操作写入一个专门的日志文件translog中,一旦此时机器宕机,再次重启的时候,es 会自动读取 translog 日志文件中的数据,恢复到内存 buffer 和 os cache 中去。但每5秒触发一次,机器宕机会有5秒的数据丢失。 -
重复上面的步骤,新的数据不断进入 buffer 和 translog,不断将
buffer数据写入一个又一个新的segment file中去,每次refresh完 buffer 清空,translog 保留。随着这个过程推进,translog 会变得越来越大。当 translog 达到一定长度的时候,就会触发commit操作。 -
commit 操作发生第一步,就是将 buffer 中现有数据
refresh到os cache中去,清空 buffer。然后,将一个commit point写入磁盘文件,里面标识着这个commit point对应的所有segment file,同时强行将os cache中目前所有的数据都fsync到segment file磁盘文件中去。最后清空现有 translog 日志文件,重启一个 translog,此时 commit 操作完成。这个 commit 操作叫做
flush。默认 30 分钟自动执行一次flush,但如果 translog 过大,也会触发flush。flush 操作就对应着 commit 的全过程,我们可以通过 es api,手动执行 flush 操作,手动将 os cache (translog os cache、segment file os cache)中的数据 fsync 强刷到磁盘上去。
总结:
- es 第一是准实时的,数据写入 1 秒后可以搜索到;可能会丢失数据的。有 5 秒的数据,停留在 buffer、translog os cache、segment file os cache 中,而不在磁盘上,此时如果宕机,会导致 5 秒的数据丢失。
- 数据先写入内存 buffer,然后每隔 1s,将数据 refresh 到 os cache,到了 os cache 数据就能被搜索到(所以我们才说 es 从写入到能被搜索到,中间有 1s 的延迟)。每隔 5s,将数据写入 translog 文件(这样如果机器宕机,内存数据全没,最多会有 5s 的数据丢失),translog 大到一定程度,或者默认每隔 30mins,会触发 commit 操作,将缓冲区(buffer、translog os cache、segment file os cache )的数据都 flush 到 segment file 磁盘文件中。就是说30分钟才将translog文件的数据写到segment file 磁盘文件中,清空现有translog文件
注意:数据写入 segment file 之后,同时就建立好了倒排索引。前面文章内容有讲到
删除、更新数据的底层原理
如果是删除操作,commit 的时候会生成一个 .del 文件,里面将某个 doc 标识为 deleted 状态,那么搜索的时候根据 .del 文件就知道这个 doc 是否被删除了。
如果是更新操作,就是将原来的 doc 标识为 deleted 状态,然后新写入一条数据。所以update其实底层就是删除。
buffer 每 refresh 一次,就会产生一个 segment file (其实数据是在 segment file 的os cache 中,并不在 segment file 磁盘文件中),所以默认情况下是 1 秒钟一个 segment file ,这样下来 segment file 会越来越多,此时会定期执行 merge。每次 merge 的时候,会将多个 segment file 合并成一个,同时这里会将标识为 deleted 的 doc 给物理删除掉,然后将新的 segment file 写入磁盘,这里会写一个 commit point ,标识所有新的 segment file ,然后打开 segment file 供搜索使用,同时删除旧的 segment file 。
如何合理设置分片数和副本数
当你在Elasticsearch中将index的分片设置好后,主分片数量在集群中是不能进行修改的,即便是你发现主分片数量不合理也无法调整,那怎么办?
- 分配分片时主要要考虑的问题
- 数据集的增长趋势
- 很多用户认为提前放大分配好分片的量就能确保以后不会出现新的问题,比如分1000个分片
- 要知道分配的每个分片都是由额外的成本的
- 每个分片其实都是要存数据的,并且都是一个lucene的索引,会消耗文件句柄已经CPU和内存资源
- 当你进行数据访问时,我们的index就会去到所有的分片上去取数据
- 如果要取100条,如果你有100个分片,就会从100个分片上各取出100个数据然后进行排序给出最终的排序结果,取了100*100条数据
- 主分片数据到底多少为宜呢?
- 根据你的节点数来进行分片,3个Node,N*(1.5-3)
- 我们现在3个节点,主分片数据:5-9个分片
总结
- 分片是有相依消耗的,并且持续投入
- 当index拥有多个分片时,ES会查询所有分片然后进行数据合并排序
- 分片数量建议:node*(1.5-3)
# 创建索引过程中进行分片设置
PUT /index_test
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
}
}
# 修改副本分片数量,可以随时修改,副本建议1到2个就好了
# 副本分片如果过多在写入的时候会消耗更多时间来复制数据
PUT /index_test/_settings
{
"number_of_replicas": 2
}