 弹吉他的兔子
弹吉他的兔子
1、查询模版search template的使用
什么是查询模版?
对于ES来说,你可以把它理解为一个NoSQL的容器,应用来访问和调用的过程,对于搜索引擎来讲,你的所有业务搜索场景是不是都是相对明确的?
能不能做到ES的业务处理,由ES来做,前端不关心ES的json的语法格式来做到搜索引擎和前端解耦
# 模版结构可以应用到所有的索引上
# 1、创建模版,创建的时候不加索引,tpnick是模版名,可以自定义。当你需要修改模版的时候,再次提交,就会覆盖

# 2、调用模版进行查询
POST /index_customer/_search/template
{
"id": "tpnick",
"params": {
"nick_value": "太阳",
"nick_analyzer": "ik_max_word"
}
}
# 获得模版
GET /_scripts/tpnick
# 删除模版
DELETE /_scripts/tpnick
2、update by query更新索引field分词
索引自更新
# 场景1: 一个field在使用了一段时间后,发现需要增加新的分词器,比如原来是中文,后面要加pinyin
# 1、增加子字段,使用pinyin分词器搜索
POST /index_customer/_mapping
{
"properties": {
"nickname": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"pinyin": {
"type": "text",
"analyzer": "pinyin"
}
}
}
}
}
# 添加分词器后就进行搜索,是搜不到数据的
# 分词器在数据加入后增加,对前面的数据无法进行分词搜索
GET /index_customer/_search
{
"query": {
"match": {
"nickname.pinyin": "taiyang"
}
}
}
# 就要对现有index进行自更新
POST /index_customer/_update_by_query
# 场景2:中文分词器里面,会在数据已经导入后加入新的分词,这个时候这个分词就搜不到以前的数据
# 不是ik分词器的问题,是因为你没有更新索引
# 这里需要注意的点,ES索引中的数据,是在导入时就进行了分词,而不是在查询的时候才进行分词
根据查询条件更新文档
// 1、MYSQL语句
update index_name set name = ‘wb’ where id = ‘20132112534’;
POST /index_name/_update_by_query
{
"query": {
"bool": {
"must": [
{
"term": {
"id": "20132112534"
}
}
]
}
},
"script": {
"ctx._source['name'] = 'wb'"
}
}
// 2、MYSQL语句
update index_name set name = ‘wb’ where (a_time - b_time = 100000)
POST /index_name/_update_by_query
{
"query": {
"bool": {
"must": [
{
"script": {
"script": {
"source": "doc['a_time'].value- doc['b_time'].value == 100000"
}
}
}
]
}
},
"script": {
"source": "ctx._source.name = params.name",
"params": {
"name": "wb"
}
}
}
// 3、MYSQL语句
update index_name set sort_time = update_time where sort_time is null;
POST /index_name/_update_by_query
{
"query": {
"bool": {
"must_not": [
{
"exists": {
"field": "sort_time"
}
}
]
}
},
"script": {
"source": "ctx._source['sort_time'] = ctx._source['update_time']"
}
}
我们把所有的文档都添加一个新的字段contact,并赋予它一个同样的值:
POST /index_name/_update_by_query
{
"script": {
"source": "ctx._source['contact'] = \"139111111111\""
}
}
我们想对所有在北京的文档里的uid都加1,那么可通过如下的方法:
POST /index_name/_update_by_query
{
"query": {
"match": {
"city.keyword": "北京" // 子字段
}
},
"script": {
"source": "ctx._source['uid'] += params['one']",
"params": {
"one": 1
}
}
}
针对大量数据的update
POST blogs_fixed/_update_by_query
{
"query": {
"range": {
"flag": {
"lt": 1
}
}
},
"script": {
"source": "ctx._source['flag']=1"
}
}
我们再次运行上面的_update_by_query时,之前已经处理过的文件将不再被处理了
模糊查询
参考:https://cloud.tencent.com/developer/article/1797423
prefix 前缀查询
GET /my_index/_search
{
"query": {
"prefix": {
"postcode": "W1"
}
}
}
适用于text或keyword字段,举例:
// 帐号不是以:gys_开头的帐号数据,并把帐号于更新为以gys_开头(如将“anhuili”变更成“gys_anhuili”)
POST https://10.213.53.12:19200/index_todo/_update_by_query
{
"query": {
"bool": {
"must": [
{
"term": {
"userType": {
"value": "supplier"
}
}
},
{
"bool": {
"must_not": [
{
"prefix": {
"target": {
"value": "gys_"
}
}
}
]
}
}
]
}
},
"script":{
"source": "ctx._source.target = 'gys_' + ctx._source.target"
}
}
3、reindex重建索引
场景描述
- 我们一个index在创建好mapping后不能对type进行修改,原来是keyword我想改成text?
- 比如我们的存储不够了,加入了新的机器进入集群,主分片我想增加怎么办?
- 可以通过reindex修改列名
# 这个时候就需要使用reindex,相当于索引复制的概念
# 如果你的新索引没有手工创建mapping,那么ES会根据数据来自动生成mapping
# 建议新索引手工创建mapping,分片、副本数、别名的配置
# 1、修改列名
# 下面的script脚本把username改为username1,nickname改为nickname1,索引从index_customer复制到index_test的字段对应
POST /_reindex
{
"source": {
"index": "index_customer"
},
"dest": {
"index": "index_test"
},
"script":{ "inline":"ctx._source.username1=ctx._source.remove(\"username\");ctx._source.nickname1=ctx._source.remove(\"nickname\")"
}
}
# 2、复制索引,过滤数据
POST /_reindex
{
"source": {
"index": "index_customer",
"query": {
"term": {
"name": "shao"
}
},
"_source": ["field_name_1", "field_name_2"],
"sort": { "date": "desc" }
},
"dest": {
"index": "index_test"
}
}
# 3、新index里本来就有数据,只复制不存在的文档,已存在文档跳过
POST /_reindex
{
#"conflicts": "proceed", # 加上这个参数,如文档已存在(冲突),则会跳过继续往下执行,类似于java里的continue
"source": {
"index": "index_customer"
},
"dest": {
"index": "index_test",
"op_type": "create"
}
}
#返回结果
"took": 11, # 耗时
"timed_out": false,
"total": 14,
"updated": 0, # 修改的条数
"created": 0, # 创建的条数
"deleted": 0, # 删除的条数
"batches": 1, # 批处理的个数
"version_conflicts": 14, # 版本冲突的个数
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
# 4、version_type,默认值为internal,即当发生冲突后会覆盖之前的document,设置为external则会新生成一个另外的document
POST /_reindex
{
"source": {
"index": "index_customer",
},
"dest": {
"index": "index_test",
"version_type": "external"
}
}
# 5、多Index、Type数据的reindex,7.x后type默认为doc,应该可以去掉
POST _reindex
{
"source": {
"index": [
"index_name_1",
"index_name_1"
],
"type": [
"type_name_1",
"type_name_2"
],
"query": {//query的条件
"term": {
"user": "kimchy"
}
}
},
"dest": {
"index": "all_together_index_name"
}
}
# 6、跨集群复制索引
# 将索引从集群A复制到集群B,这个要在B集群上执行
# 要给soure设置白名单,在B集群的elasticsearch.yml文件里
# reindex.remote.whitelist: "192.168.0.100:9200,192.168.0.101:9200"
# 可以写DSL查询要复制的数据
POST /_reindex
{
"source": {
"remote": {
"host": "http://192.168.0.100:9200"
},
"index": "index_customer",
"query": {
"match": {
"desc": "艾编程"
}
},
"size": 100
},
"dest": {
"index": "index_test1",
"op_type": "create"
}
}
# 7、异步操作,不影响索引的读写,生产环境上比较有用
POST /_reindex?wait_for_completion=false
# 会返回一个taskId,会创建一个.tasks的索引,可浏览数据根据taskId查看重建索引是否已完成
{
"task": "gIvu5fnXSF22MigqwfDSnA:2270"
}
使用reindex 进行数据迁移,提升效率的方案
-
修改批量写入大小值提升效率
POST _reindex { "source": { "index": "source", "size": 5000 # 默认每批处理1000个文档 }, "dest": { "index": "dest", "routing": "=cat" } } # 建议每批处理5-15MB的数据,如每个文档的大小是1kb,那么1000个文档=1MB,索引这个size设多大跟文档的大小有关 -
修改slices提升写入效率,
# 自动并行化重建索引 # slices 可以设置为auto或者具体值,设置为auto时,如果是单索引重建,slices=分片数;如果是多索引重建,slices=分片的最小值 # slices 大于分片数,性能反而下降 POST _reindex?slices=5 { "source": { "index": "twitter" }, "dest": { "index": "new_twitter" } } -
副本数设置为0
# 新索引的副本数先设置为0 PUT /new_index_name/_settings { "number_of_replicas": 0 } # 重建完索引后,再将新索引的副本数设置为1 PUT /my_logs/_settings { "number_of_replicas": 1 }
4、index alias建立索引别名
场景描述
- 如果在ES中会横向以时间为维度创建很多索引,比如index_0201,index_0202
- 这个时候前端应用不能因为ES名字改了就修改索引名,这个时候就可以通过别名来统一
- 一个别名节点可以关联多个索引
- 别名也不能和现有索引重复,如果别名重复,数据就合并到一起了
# 添加别名
POST /_aliases
{
"actions": [
{
"add": {
"index": "index_customer",
"alias": "index_user",
"filter": {
"range": {
"consume": {
"gte": 2000
}
}
}
}
}
]
}
# 同时创建多个别名,相当于做个了一个逻辑合并,可以支持分词和相关搜索
POST /_aliases
{
"actions": [
{
"add": {
"index": "index_test",
"alias": "index_user"
}
},
{
"add": {
"index": "index_test1",
"alias": "index_user"
}
}
]
}
# 删除别名
POST /_aliases
{
"actions": [
{
"remove": {
"index": "index_test",
"alias": "index_user"
}
},
{
"remove": {
"index": "index_test1",
"alias": "index_user"
}
}
]
}
5、ES的聚合查询
什么是聚合
ES中聚合是对查询出来的数据结果进行分组,相当于sql中的group by
ES中的聚合命令是aggregation[ˌæɡrɪˈɡeɪʃn]
- Bucket Aggregation:一些列满足特定条件的的文档集合(bucket[ˈbʌkɪt])
- Metric Aggregation:一些数学运算,可以对文档字段进行统计分析(metric[ˈmetrɪk])
- Pipeline Aggregation:对聚合结果进行二次聚合(pipeline[ˈpaɪplaɪn])
- Matrix Aggregation:支持对多个字段的操作并提供一个结果矩阵(matrix[ˈmeɪtrɪks])
select count(brand) # 这个就相当于上面的Metric
from cars
group by brand # 这个就相当于上面的bucket(桶)
大多数Metric都是输出一个值
- min / max / sum / avg / cardinality
部分metric支持多个数值
- stats / percentiles(百分比) / percentiles_ranks(百分比范围)
注意:聚合分桶只能对keyword字段进行,对text进行是不行的
如果想要在text字段上进行聚合分桶如何做
- 第一种方式:加个keyword的子字段 nickname.keyword
- 第二种方式:开启字段的fielddata=true ,对text分词进行分桶(不建议)
# 在ES中默认对fielddata是false的
# 因为开启text的fielddata后对内存占用高
# 开启后该field进行分词后桶合并
"nickname": {
"type": "text",
"fielddata": true
}
使用terms分桶加metric数学运算
场景1: 对查询结果进行聚合,得出不同城市的学员数
# size:0 不显示数据,默认返回10条数据
POST /index_customer/_search
{
"query": {
"match_all": {}
},
"size":0,
"aggs": {
"city_count": {
"terms": {
"field": "city"
}
}
}
}
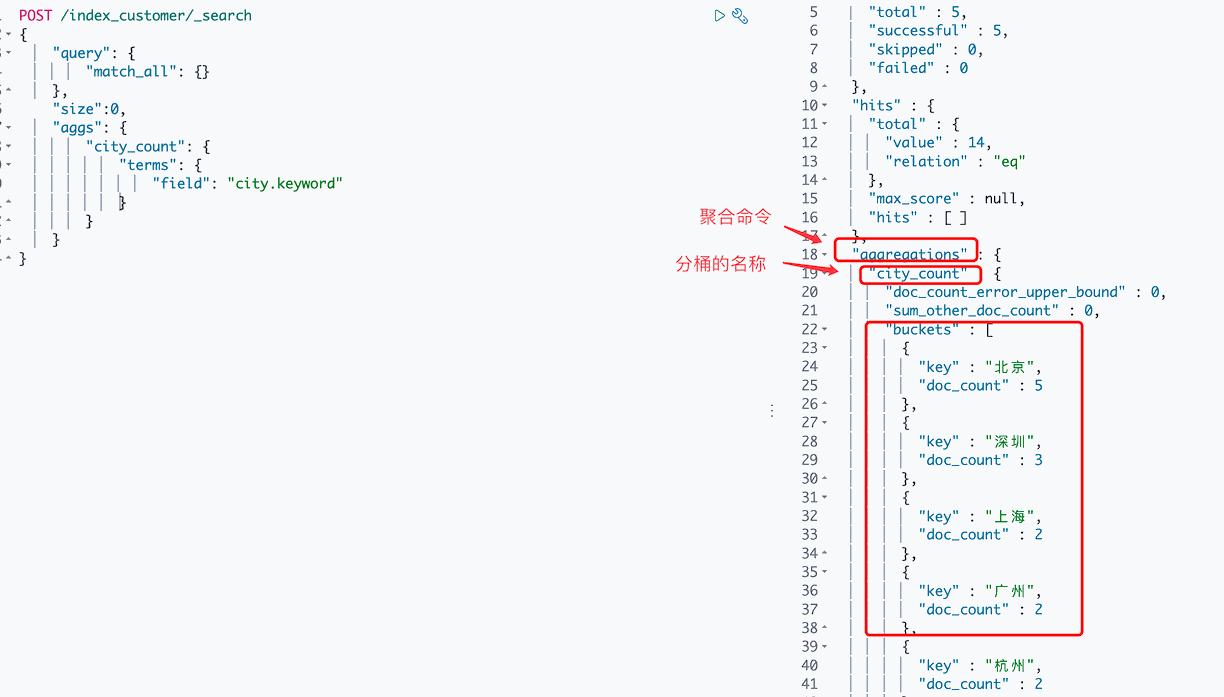
场景2: 对查询结果进行聚合,得出不同城市的学员数,并得出各个城市学员消费的最大最小平均
# 关键字: terms / aggs / min / max / avg
# aggs下面的第一个key是你的分组名
# 跟写sql的group by 分组类似,terms相当于group by,其它都是聚合函数
POST /index_customer/_search
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"city_count": {
"terms": {
"field": "city"
},
"aggs": {
"avg_consume": {
"avg": {
"field": "consume"
}
},
"max_consume": {
"max": {
"field": "consume"
}
},
"min_consume": {
"min": {
"field": "consume"
}
}
}
}
}
}
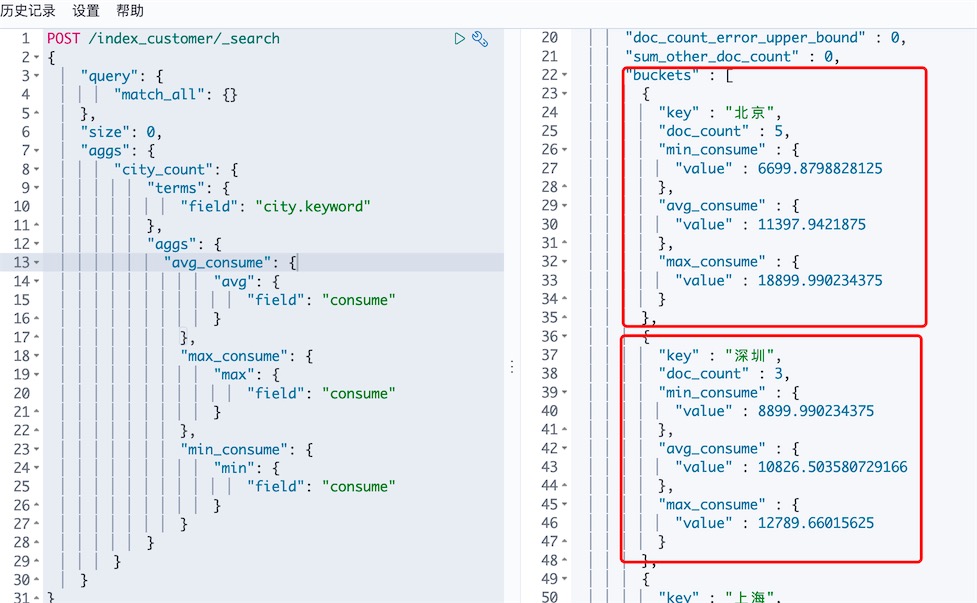
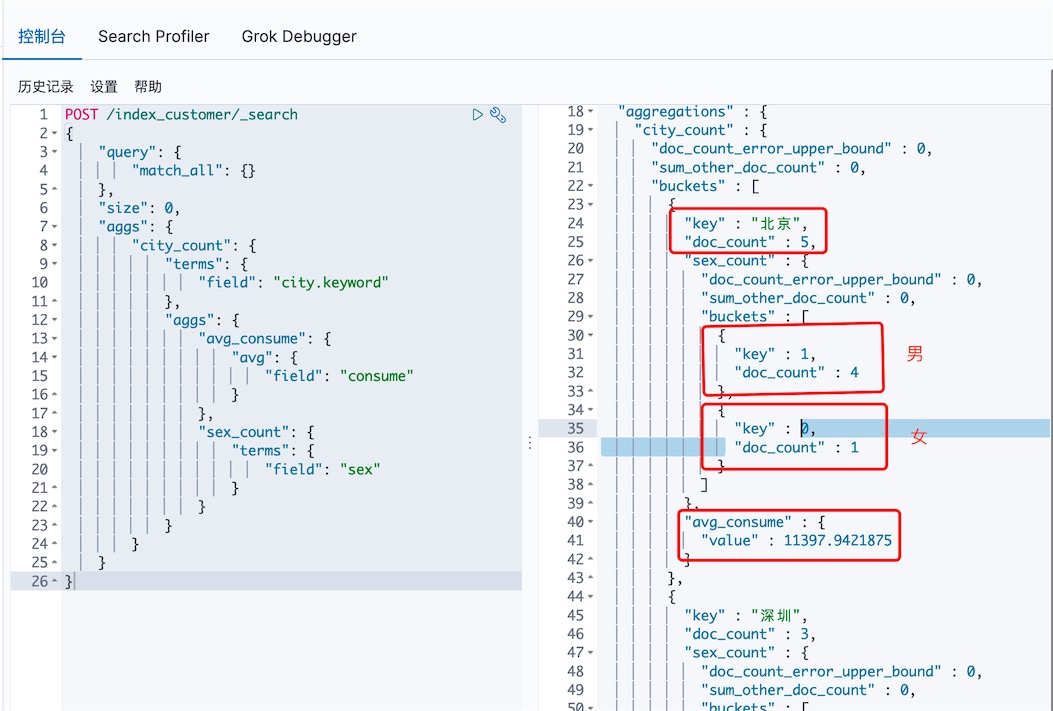
场景3: 对查询结果进行聚合,得出不同城市的学员数,城市的平均消费水平,该城市学院的性别分布
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"city_count": {
"terms": {
"field": "city"
},
"aggs": {
"avg_consume": {
"avg": {
"field": "consume"
}
},
"sex_count": {
"terms": {
"field": "sex"
}
}
}
}
}
}
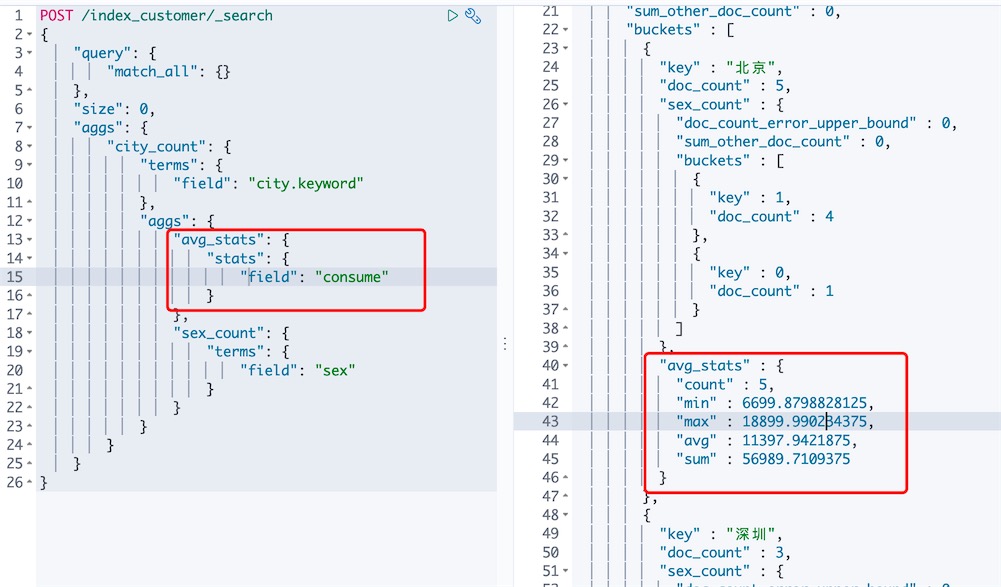
# 将场景3修改为stats的多输出metric
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"city_count": {
"terms": {
"field": "city"
},
"aggs": {
"avg_stats": {
"stats": {
"field": "consume"
}
},
"sex_count": {
"terms": {
"field": "sex"
}
}
}
}
}
}
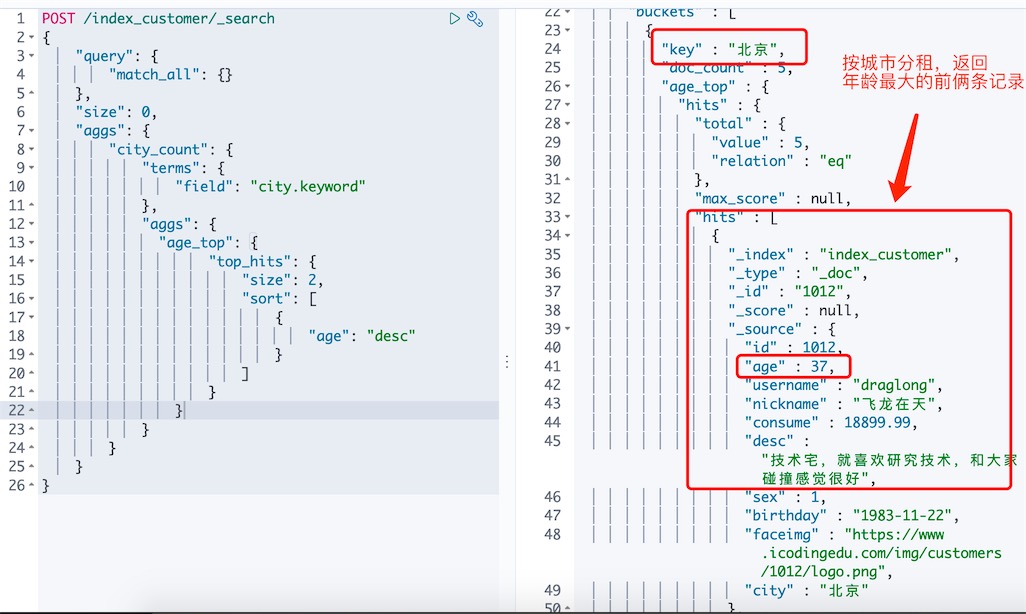
场景4:统计一下各个城市学员,年龄最大排前2的并返回信息
# top_hits,排前的命中
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"city_count": {
"terms": {
"field": "city"
},
"aggs": {
"age_top": {
"top_hits": {
"size": 2,
"sort": [
{
"age": "desc"
}
]
}
}
}
}
}
}
6、基础数据
Elasticsearch安装时要提前把ik分词器,pinyin分词器安装好
mapping
# POST /index_customer/_mapping
{
"properties": {
"id": {
"type": "long"
},
"age": {
"type": "integer"
},
"username": {
"type": "keyword"
},
"nickname": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"pinyin": {
"type": "text",
"analyzer": "pinyin"
}
}
},
"consume": {
"type": "float"
},
"desc": {
"type": "text",
"analyzer": "ik_max_word"
},
"sex": {
"type": "byte"
},
"birthday": {
"type": "date"
},
"city": {
"type": "keyword"
},
"faceimg": {
"type": "text",
"index": false
}
}
}
document
# POST /index_customer/_doc/1001
{
"id": 1001,
"age": 24,
"username": "kingliu",
"nickname": "飞上天空做太阳",
"consume": 1289.88,
"desc": "我在艾编程学习java和vue,学习到了很多知识",
"sex": 1,
"birthday": "1996-12-24",
"city": "北京",
"faceimg": "https://www.icodingedu.com/img/customers/1001/logo.png"
}
# POST /index_customer/_doc/1002
{
"id": 1002,
"age": 26,
"username": "lucywang",
"nickname": "夜空中最亮的星",
"consume": 6699.88,
"desc": "我在艾编程学习VIP课程,非常打动我",
"sex": 0,
"birthday": "1994-02-24",
"city": "北京",
"faceimg": "https://www.icodingedu.com/img/customers/1002/logo.png"
}
# POST /index_customer/_doc/1003
{
"id": 1003,
"age": 30,
"username": "kkstar",
"nickname": "照亮你的星",
"consume": 7799.66,
"desc": "老师们授课风格不同,但结果却是异曲同工,讲的很不错,值得推荐",
"sex": 1,
"birthday": "1990-12-02",
"city": "北京",
"faceimg": "https://www.icodingedu.com/img/customers/1003/logo.png"
}
# POST /index_customer/_doc/1004
{
"id": 1004,
"age": 31,
"username": "alexwang",
"nickname": "骑着老虎看日出",
"consume": 9799.66,
"desc": "课程内容充实,有料,很有吸引力,赞一个",
"sex": 1,
"birthday": "1989-05-09",
"city": "上海",
"faceimg": "https://www.icodingedu.com/img/customers/1004/logo.png"
}
# POST /index_customer/_doc/1005
{
"id": 1005,
"age": 32,
"username": "jsonzhang",
"nickname": "我是你的神话",
"consume": 12789.66,
"desc": "需要抽时间把所有内容都学个遍,太给力料",
"sex": 1,
"birthday": "1988-07-19",
"city": "上海",
"faceimg": "https://www.icodingedu.com/img/customers/1005/logo.png"
}
# POST /index_customer/_doc/1006
{
"id": 1006,
"age": 27,
"username": "abbyli",
"nickname": "好甜的棉花糖",
"consume": 10789.86,
"desc": "还不错,内容超过我的预期值,钱花的值",
"sex": 0,
"birthday": "1993-10-11",
"city": "上海",
"faceimg": "https://www.icodingedu.com/img/customers/1006/logo.png"
}
# POST /index_customer/_doc/1007
{
"id": 1007,
"age": 33,
"username": "jacktian",
"nickname": "船长jack",
"consume": 9789.86,
"desc": "一直想抽时间学习,这下有时间整了,给力",
"sex": 1,
"birthday": "1987-09-16",
"city": "深圳",
"faceimg": "https://www.icodingedu.com/img/customers/1007/logo.png"
}
# POST /index_customer/_doc/1008
{
"id": 1008,
"age": 23,
"username": "feifei",
"nickname": "我爱篮球",
"consume": 6689.86,
"desc": "虽然又一些不太懂,但只要有时间,相信一定能学好的",
"sex": 1,
"birthday": "1997-04-18",
"city": "深圳",
"faceimg": "https://www.icodingedu.com/img/customers/1008/logo.png"
}
# POST /index_customer/_doc/1009
{
"id": 1009,
"age": 25,
"username": "daisyzhang",
"nickname": "一起看日出",
"consume": 6680,
"desc": "学习起来还是很有意思的,值得我多次学习",
"sex": 0,
"birthday": "1995-03-27",
"city": "深圳",
"faceimg": "https://www.icodingedu.com/img/customers/1009/logo.png"
}
# POST /index_customer/_doc/1010
{
"id": 1010,
"age": 29,
"username": "ethenhe",
"nickname": "旋风小子",
"consume": 6699.99,
"desc": "课程严谨,知识丰富,讲解到位,编程给力",
"sex": 1,
"birthday": "1991-06-22",
"city": "广州",
"faceimg": "https://www.icodingedu.com/img/customers/1010/logo.png"
}
# POST /index_customer/_doc/1011
{
"id": 1011,
"age": 27,
"username": "lydiazheng",
"nickname": "跳芭蕾的小妮",
"consume": 8899.99,
"desc": "自己一直都没有动力去系统学习,这次有了老师和大家的督促,非常不错,终于坚持下来了",
"sex": 0,
"birthday": "1993-08-27",
"city": "广州",
"faceimg": "https://www.icodingedu.com/img/customers/1011/logo.png"
}
# POST /index_customer/_doc/1012
{
"id": 1012,
"age": 37,
"username": "draglong",
"nickname": "飞龙在天",
"consume": 18899.99,
"desc": "技术宅,就喜欢研究技术,和大家碰撞感觉很好",
"sex": 1,
"birthday": "1983-11-22",
"city": "广州",
"faceimg": "https://www.icodingedu.com/img/customers/1012/logo.png"
}
7、常用配置参数
cluster.name # 集群名称,相同名称为一个集群
node.name # 节点名称,集群模式下每个节点名称唯一
node.master # 当前节点是否可以被选举为master节点,是:true、否:false
node.data # 当前节点是否用于存储数据,是:true、否:false
path.data # 索引数据存放的位置
path.logs # 日志文件存放的位置
bootstrap.memory_lock # 需求锁住物理内存,是:true、否:false
bootstrap.system_call_filter # SecComp检测,是:true、否:false
network.host # 监听地址,用于访问该es
network.publish_host # 可设置成内网ip,用于集群内各机器间通信
http.port # es对外提供的http端口,默认 9200
transport.tcp.port # TCP的默认监听端口,默认 9300
discovery.seed_hosts # es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点
cluster.initial_master_nodes # es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
http.cors.enabled # 是否支持跨域,是:true,在使用head插件时需要此配置
http.cors.allow-origin # “*” 表示支持所有域名