弹吉他的兔子
弹吉他的兔子
1、ES桶聚合查询
对text字段聚合
如果想要对text类型的字段进行分桶,有两种方式:
- 第一种方式:给field增加keyword的子字段
POST /index_customer/_mapping
{
"properties": {
"nickname": {
"analyzer": "ik_max_word",
"type": "text",
"fields": {
"pinyin": {
"analyzer": "pinyin",
"type": "text"
},
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
}
}
}
# 在数据添加后增加子字段需要将index进行更新
POST /index_customer/_update_by_query
- 第二种方式:给field增加fielddata(不推荐)
# fielddata是对text文本进行分词后的桶聚合
# 默认是false,打开会比较占内存,所以没有必要的情况
POST /index_customer/_mapping
{
"properties": {
"nickname": {
"analyzer": "ik_max_word",
"type": "text",
"fielddata": true,
"fields": {
"pinyin": {
"analyzer": "pinyin",
"type": "text",
"fielddata": true
},
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
}
}
}
分桶返回的参数分析
-
doc_count_error_upper_bound:可能存在潜在的结果是聚合后结果排行第二的值
- sum_other_doc_count:表示本次聚合中还有多少没有统计展示出
- 桶默认聚合展示10条
- 可以使用size来调整条目数
- 只能指定条目数,不能分页
- buckets:会根据结果的统计降序排列
size进行桶查询的展示
POST /index_customer/_search
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"nickname_term": {
"terms": {
"field": "nickname",
"size": 20
}
}
}
}
当doc频繁有数据加入到文档中,并且这个field会频繁进行分桶,需要添加一个缓存配置
# 频繁聚合查询,索引不断有新的doc加入
# "eager_global_ordinals": true 开启缓存配置
POST /index_customer/_mapping
{
"properties": {
"nickname": {
"analyzer": "ik_max_word",
"type": "text",
"fielddata": true,
"eager_global_ordinals": true,
"fields": {
"pinyin": {
"analyzer": "pinyin",
"type": "text",
"fielddata": true,
"eager_global_ordinals": true
},
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
}
}
}
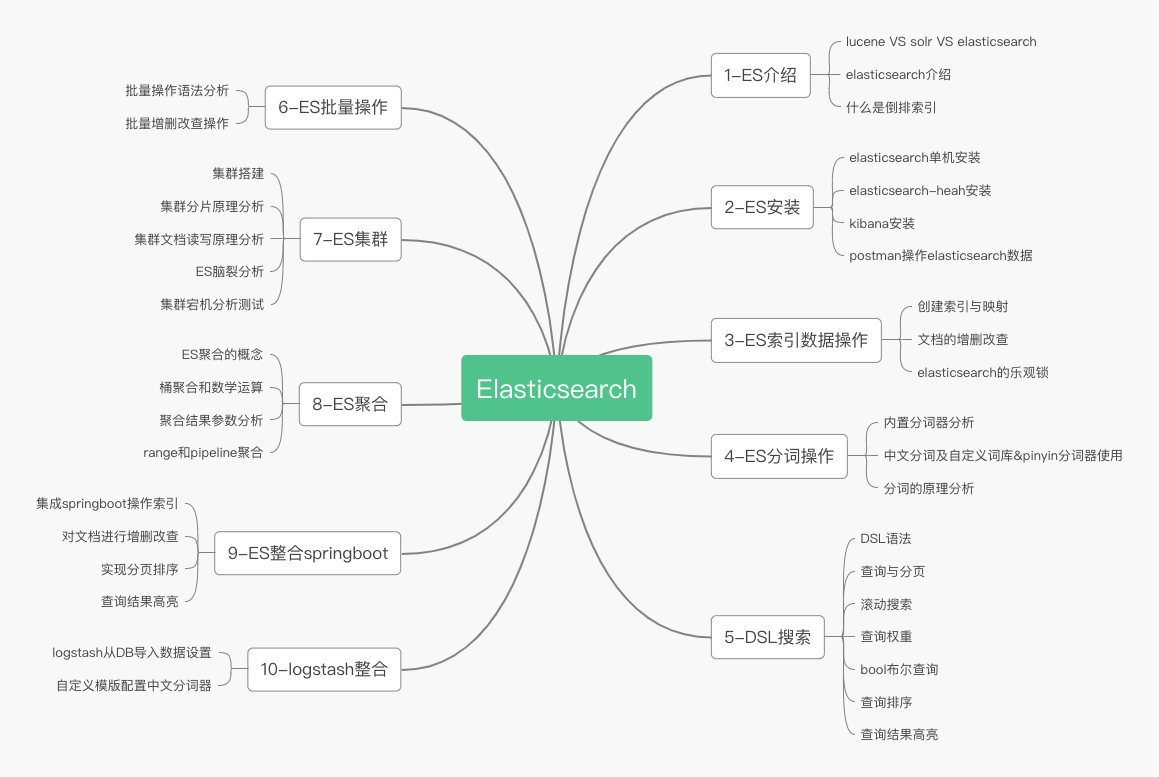
分组基数查询
# cardinality统计桶分词的基数(不同值的数量)
POST /index_customer/_search
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"nickname_term": {
"cardinality": {
"field": "nickname"
}
}
}
}
桶range计算
就是一个区间值的查询
POST POST /index_customer/_search
{
"query": {
"match_all": {}
},
"size": 0,
"sort": [
{
"consume": "desc"
}
],
"aggs": {
"city_count": {
"terms": {
"field": "city"
}
},
"consume_range": {
"range": {
"field": "consume",
"ranges": [
{
"to": 3000
},
{
"from": 3000,
"to": 6000
},
{
"from": 6000,
"to": 9000
},
{
"from": 9000
}
]
}
}
}
}

直方图的聚合
POST /index_customer/_search
{
"query": {
"match_all": {}
},
"size": 0,
"sort": [
{
"consume": "desc"
}
],
"aggs": {
"city_count": {
"terms": {
"field": "city"
}
},
"consume_histogram": {
"histogram": {
"field": "consume",
"interval": 2000,
"extended_bounds": {
"min": 0,
"max": 20000
}
}
}
}
}

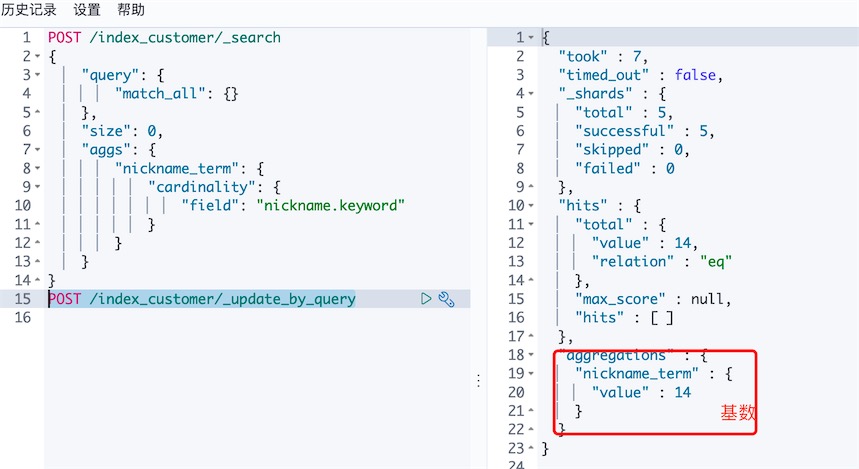
Pipeline聚合计算
pipeline就是对聚合分析再做一次聚合分析场景:从所有城市的平均消费中,拿出消费最低的那个城市
GET /index_customer/_search
{
"query": {
"match_all": {}
},
"size": 0,
"sort": [
{
"consume": "desc"
}
],
"aggs": {
"city_count": {
"terms": {
"field": "city"
},
"aggs": {
"avg_consume": {
"avg": {
"field": "consume"
}
}
}
},
"min_consume_by_city": {
"min_bucket": {
"buckets_path": "city_count>avg_consume"
}
},
"max_consume_by_city": {
"max_bucket": {
"buckets_path": "city_count>avg_consume"
}
}
}
}
# min_bucket / buckets_path 是关键字
# 最大、最小、平均、和、全包含
max_bucket / min_bucket / avg_bucket / sum_bucket / stats_bucket
2、Springboot整合Elasticsearch
springboot应用elasticsearch搜索有两种方式:
- 利用spring-boot-starter-data-elasticsearch进行整合
- 不整合,自己写search template脚本,http调用查询模版,对返回的结果解析
集成
新建一个Springboot项目
1、导入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
注意springboot的版本和es的版本对应,查看pom的依赖
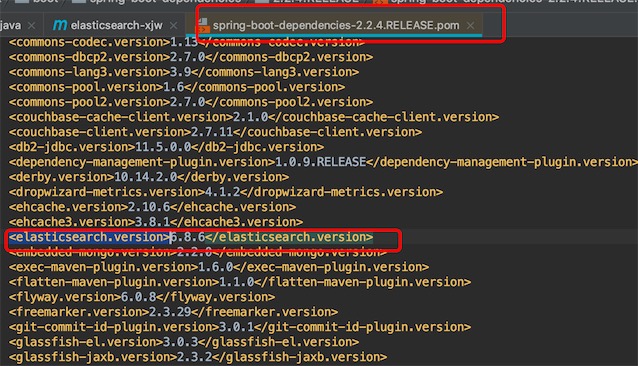
而最新的springboot2.3,es的版本是

所以要知道es的版本
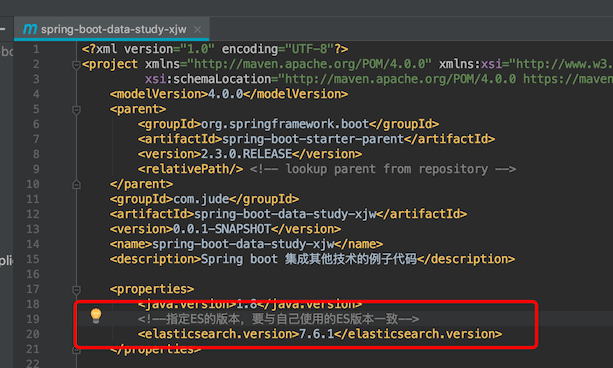
2、application.yml 配置
# 端口一定要9300,适合springboot 2.2.x版本
spring:
data:
elasticsearch:
cluster-name: icoding-es
cluster-nodes: 47.92.163.109:9300
# 自己搭建时发现,上面的连接方式已过时了,可以使用rest连接
spring:
elasticsearch:
rest:
uris: ["http://139.199.13.139:9200"]
如果uris是一个变量值,看下面配置:
bootstrap.yml
spring:
application:
name: mongodb-demo
profiles:
active: local
bootstrap.yml配置文件是springcloud项目才会识别的,如果仅仅是springboot项目,就只会识别application.yml配置文件,所以pom.xml要加入以下maven依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-context</artifactId>
<version>2.2.9.RELEASE</version>
<scope>compile</scope>
</dependency>
application.yml
spring:
session:
store-type: none
elasticsearch:
rest:
uris: ["${ELASTICSEARCH_URIS}"]
username: elastic
password: ${ELASTICSEARCH_PASSWORD}
application-local.yml
spring.profiles.include: local-config,local-secret
application-local-config.yml
ELASTICSEARCH_URIS: https://10.213.53.12:19200,https://10.213.53.13:19200
application-local-secret.yml
ELASTICSEARCH_PASSWORD: PW_2#1changeme
3、使用
创建映射的po
package com.icodingedu.po;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
//indexName相当于给索引明名
//type相当于文档类型,默认_doc
//indexName 能用别名吗,不能
//由于ealsticsearchTemplate的问题,@field的声明不生效
@Data
@Document(indexName = "index_user",type = "_doc",shards = 3,replicas = 1)
public class ESUser {
//index的doc的_id和数据的id一致
@Id
private String id;
//默认不是存储节点,要声明
@Field(store = true,index = true,analyzer = "ik_max_word",searchAnalyzer = "ik_max_word")
private String nickname;
@Field(store = true)
private Integer sex;
@Field(store = true)
private Double consume;
@Field(store = true,index = true,analyzer = "ik_max_word",searchAnalyzer = "ik_max_word")
private String review;
}
创建索引(包括mapping\document)
package com.icodingedu.controller;
import com.icodingedu.po.UserBo;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.data.elasticsearch.core.query.IndexQuery;
import org.springframework.data.elasticsearch.core.query.IndexQueryBuilder;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.ResponseBody;
@Controller
public class ESUserController {
// 依赖spring.data.elasticsearch属性创建es连接来注入的bean,所以没配置spring.data.elasticsearch时spring容器没有这个bean
@Autowired
ElasticsearchTemplate elasticsearchTemplate;
@GetMapping("/create_index")
@ResponseBody
public String createIndex(){
ESUser esuser = new ESUser();
esuser.setId("1001");
esuser.setConsume(1899.66);
esuser.setNickname("空中雄鹰");
esuser.setReview("icoding edu 艾编程课程非常不错,学起来很给力");
esuser.setSex(1);
IndexQuery indexQuery = new IndexQueryBuilder()
.withObject(userBo)
.build();
elasticsearchTemplate.index(indexQuery);
return "index/mapping/document 一起创建完成";
}
}
// elasticsearchTemplate.bulkIndex 批量插入
// elasticsearchTemplate.bulkUpdage 批量更新
更新索引的mapping
// 只需要在po里加上字段既可以
// 创建的时候给赋值
// 更新的时候elasticsearchTemplate会根据po的变化判断是否更新
// 在elasticsearchTemplate.index(indexQuery)操作时如果没有index则新建,如果有就创建数据
删除index
@GetMapping("/delete-index")
@ResponseBody
public String deleteIndex(){
elasticsearchTemplate.deleteIndex(ESUser.class);
return "删除成功";
}
ElasticsearchTemplate一般用于对文档数据进行检索应用
-
对于index的mapping还是使用json来创建(postman或者kibana提交rest api 来创建修改)
-
映射po的部分注解不一定生效
对ES文档进行操作
更新document
@GetMapping("/update")
@ResponseBody
public String updateIndex(){
Map<String,Object> data = new HashMap<String,Object>();
data.put("username","jackwang");
data.put("consume",7888.99);
// 1、创建请求
IndexRequest indexRequest = new IndexRequest();
indexRequest.source(data);
// 2、构建修改
UpdateQuery updateQuery = new UpdateQueryBuilder()
.withClass(ESUser.class)
.withId("1001")
.withIndexRequest(indexRequest)
.build();
// 3、发送请求
elasticsearchTemplate.update(updateQuery);
return "更新成功";
}
删除document
@GetMapping("/delete/{id}")
@ResponseBody
public String deleteDocument(@PathVariable("id") String id){
elasticsearchTemplate.delete(ESUser.class,id);
return "删除id:"+uid;
}
根据id获得doc数据
@GetMapping("/get/{id}")
@ResponseBody
public String getIndex(@PathVariable("id") String uid){
GetQuery query = new GetQuery();
query.setId(uid);
ESUser esuser = elasticsearchTemplate.queryForObject(query,ESUser.class);
return esuser.toString();
}
对ES文档进行分页查询
1、索引po
// ES中已有的index映射对象
package com.icodingedu.po;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
@Data
@Document(indexName = "index_customer",type = "_doc")
public class ESCustomer{
@Id
private String id;
@Field(store=true)
private Integer age;
@Field(store=true)
private String username;
@Field(store=true)
private String nickname;
@Field(store=true)
private Float consume;
@Field(store=true)
private String desc;
@Field(store=true)
private Integer sex;
@Field(store=true)
private String birthday;
@Field(store=true)
private String city;
@Field(store=true)
private String faceimg;
}
2、分页封装类PageUtils
@Data
public class PageUtils implements Serializable {
private static final long serialVersionUID = -503429191696781198L;
/**
* 总记录数
*/
private long totalCount;
/**
* 每页记录数
*/
private int pageSize;
/**
* 总页数
*/
private long totalPage;
/**
* 当前页数
*/
private int currPage;
/**
* 列表数据
*/
private List<?> list;
/**
* 分页
*/
public PageUtils(AggregatedPage<?> page) {
this.list = page.getContent();
this.totalCount = page.getTotalElements();
this.pageSize = page.getSize();
this.currPage = page.getNumber();
this.totalPage = page.getTotalPages();
}
}
3、业务层接口 ESUserService
PageUtils listPage();
4、接口实现类ESUserServiceImpl
@Override
public PageUtils listPage() {
// 4.增加排序
SortBuilder sortBuilder1 = new FieldSortBuilder("consume").order(SortOrder.DESC);
SortBuilder sortBuilder2 = new FieldSortBuilder("age").order(SortOrder.DESC);
// 3.定义分页
Pageable pageable = PageRequest.of(0,5);
// 2.定义searchquery
SearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.matchQuery("desc","艾编程 学习"))
.withPageable(pageable)
.withSort(sortBuilder1)
.withSort(sortBuilder2)
.build();
// 1.先写查询
AggregatedPage<ESCustomer> esCustomers = elasticsearchTemplate.queryForPage(searchQuery,ESCustomer.class);
System.out.println("总页数:"+esCustomers.getTotalPages());
System.out.println("总记录数:"+esCustomers.getTotalElements());
return new PageUtils(esCustomers);
}
5、web层接口的定义ESCodeController
@Autowired
private ESUserService esUserService;
@GetMapping("/list")
public PageUtils list(){
return esUserService.listPage();
}
ES文档实现高亮查询
1、业务层接口 ESUserService
PageUtils listHighLignt();
2、接口实现类ESUserServiceImpl
@Override
public PageUtils listHighLignt() {
// 4.定义高亮字符
String preTags = "<font color='red'>";
String postTags = "</font>";
// 3.定义分页
Pageable pageable = PageRequest.of(0,5);
// 2.定义searchquery
SearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.matchQuery("desc","艾编程 学习"))
.withHighlightFields(new HighlightBuilder.Field("desc").preTags(preTags).postTags(postTags))
.withPageable(pageable)
.build();
// 1.先写查询
AggregatedPage<ESCustomer> esCustomers = elasticsearchTemplate.queryForPage(searchQuery, ESCustomer.class, new SearchResultMapper() {
@Override
public <T> AggregatedPage<T> mapResults(SearchResponse searchResponse, Class<T> aClass, Pageable pageable) {
List<ESCustomer> customerList = new ArrayList<>();
SearchHits hits = searchResponse.getHits();
for(SearchHit h : hits){
HighlightField highlightField = h.getHighlightFields().get("desc");
String desc = highlightField.fragments()[0].toString();
ESCustomer esCustomer = new ESCustomer();
Map<String,Object> sourceMap = h.getSourceAsMap();
sourceMap.put("desc",desc); // 这就是把高亮字段替换原字段
//BeanUtils.copyProperties(sourceMap,esCustomer); 不支持深拷贝,不支持拷贝List,Map, 使用Json转换
esCustomer = JSON.parseObject(JSON.toJSONString(sourceMap),ESCustomer.class);
customerList.add(esCustomer);
}
if(customerList.size()>0){
return new AggregatedPageImpl(customerList,pageable,hits.getTotalHits().value);
}
return null;
}
@Override
public <T> T mapSearchHit(SearchHit searchHit, Class<T> aClass) {
return null;
}
});
return new PageUtils(esCustomers);
}
3、web层接口的定义ESCodeController
@GetMapping("/listHighlight")
public PageUtils listHighlight(){
return esUserService.listHighLignt();
}
ES文档进行数据排序
只需要加入排序的构建就ok了
@GetMapping("/list")
@ResponseBody
public String getList(){
//4.加入排序构建
SortBuilder sortBuilder1 = new FieldSortBuilder("consume")
.order(SortOrder.DESC);
SortBuilder sortBuilder2 = new FieldSortBuilder("age")
.order(SortOrder.ASC);
//3.定义分页
Pageable pageable = PageRequest.of(0,6);
//2.定义query对象
SearchQuery query = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.matchQuery("desc","学习"))
.withPageable(pageable)
.withSort(sortBuilder1)
.withSort(sortBuilder2)
.build();
//1.先写查询
AggregatedPage<CustomerPo> customerPos = elasticsearchTemplate.queryForPage(query,CustomerPo.class);
System.out.println("总页数:"+customerPos.getTotalPages());
System.out.println("总记录数:"+customerPos.getTotalElements());
List<CustomerPo> customerPoList = customerPos.getContent();
for (CustomerPo customerPo:customerPoList) {
System.out.println(customerPo.toString());
}
return "查询完成";
}
3、通过Logstash同步DB数据进ES
什么是Logstash
思考一个场景:
我们现在要对一些数据统一采集并加入到ES中,进行大数据搜索,怎么做?
- 通过手动逐条写入
- 通过Java的程序或其他代码中间件来批量操作,集成到springboot
如果这个时候有一个数据通道能帮我们来做数据的导入,就非常不错,ELK(elasticsearch+logstash+kibana)
logstash是一个数据导入的通道
- 数据库:MySQL/SqlServer/Oracle
- 文件:可以将文件日志进行导入
- Redis:可以导入redis的数据
- MQ:RabbitMQ里的数据进行导入
logstash除了初始化的数据导入以外,还支持增量的自动更新
准备工作
- logstash需要数据库的驱动支持
- logstash要和elasticsearch的版本保持一致
- 安装好jdk来提供代码驱动支持
- 提前要把索引创建好,可以只创建一个空index(没有mapping)
安装Logstash
# 1、根据ES的版本下载
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.5.2.tar.gz
# 2、确保已安装Java,配置环境变量
vi /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_65
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
source /etc/profile
# 3、解压
tar -zxvf logstash-7.5.2.tar.gz
# 移动到/usr/local/logstash
mv logstash-7.5.2 /usr/local/logstash/
定时同步DB数据到ES
[root@helloworld home]# cd /usr/local/logstash/logstash-7.5.2
# 创建同步目录
[root@helloworld logstash-7.6.0]# mkdir sync
[root@helloworld logstash-7.6.0]# cd sync
# 创建一个数据同步的配置文件
[root@helloworld sync]# vim logstash-db-product-sync.conf
logstash-db-product-sync.conf的内容如下:
input {
jdbc {
# 设置 MySql/MariaDB 数据库url以及数据库名称
jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/icoding_mall?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true"
# 用户名和密码
jdbc_user => "root"
jdbc_password => "123456"
# 数据库驱动所在位置,可以是绝对路径或者相对路径
jdbc_driver_library => "/usr/local/logstash/logstash-7.5.2/sync/mysql-connector-java-5.1.9.jar"
# 驱动类名
jdbc_driver_class => "com.mysql.jdbc.Driver"
# 开启分页
jdbc_paging_enabled => "true"
# 分页每页数量,可以自定义
jdbc_page_size => "1000"
# 执行的sql文件路径
statement_filepath => "/usr/local/logstash/logstash-7.5.2/sync/icoding-product-task.sql"
# 设置定时任务间隔 含义:分、时、天、月、年,全部为*默认含义为每分钟跑一次任务
schedule => "* * * * *"
# 索引类型
type => "_doc"
# 是否开启记录上次追踪的结果,也就是上次更新的时间,这个会记录到last_run_metadata_path的文件
use_column_value => true
# 记录上一次追踪的结果值
last_run_metadata_path => "/usr/local/logstash/logstash-7.5.2/sync/track_time"
# 如果 use_column_value 为true, 配置本参数,追踪的column名,可以是自增id或者时间
# 同步更新SQL的那个update的字段是什么就写什么
tracking_column => "update_time"
# tracking_column 对应字段的类型
tracking_column_type => "timestamp"
# 是否清除 last_run_metadata_path 的记录,true则每次都从头开始查询所有的数据库记录
clean_run => false
# 数据库字段名称大写转小写
lowercase_column_names => false
}
}
output {
elasticsearch {
# es地址 不能使用127.0.0.1,使用内网ip或外网ip
hosts => ["192.168.0.146:9200"]
# 同步的索引名
index => "index_products"
# 设置_doc ID和数据相同,如果注释掉就自动生成_doc的ID
document_id => "%{product_id}"
}
# 这里输出调试,正式运行时可以注释掉
stdout {
codec => json_lines
}
}
时间更新字段 tracking_column 与 tracking_column_type
- numeric(默认)
- timestamp:时间字段一定要用这个
执行的sql文件icoding-product-task.sql,sql语句如下:
/** update_time>= :sql_last_value 就是每次更新大于最后一次执行的时间变量 **/
select
product_id,
product_title,
url_handle,
first_image_src,
second_image_src,
original_price,
sale_price,spu,
short_description,
detail_description,
version,
is_delete,
create_emp,
update_emp,
create_time,
update_time
from im_product
where
`status`=1
and
is_delete=0
and
update_time>= :sql_last_value
配置完后,

开始执行logstash
[root@helloworld home]# cd /usr/local/logstash/logstash-7.5.2/bin
[root@helloworld bin]# ./logstash -f /usr/local/logstash/logstash-7.5.2/sync/logstash-db-product-sync.conf
Logstash的数据更新验证
- 根据你自己的数据入库的更新频率修改logstash同步时间频率
- 如果你在数据库中物理删除了记录,是不会同步到ES中
- 可用通过逻辑删除字段的状态来更新数据
自定义Logstash的mapping模版
首先获取一下logstash当前的模版是什么
解决我们首次导入数据时,text字段可以自动添加ik中文分词器,pinyin分词器,可以修改模版
# 向Elasticsearch执行Get请求,获取模版内容
GET /_template/logstash
获取到模版后我们修改一下
# 这里将order设置大一些,在加载mapping时就会从大到小应用模版
{
"order": 9,
"version": 1,
"index_patterns": [
"*"
],
"settings": {
"index": {
"number_of_shards": "1",
"refresh_interval": "5s"
}
},
"mappings": {
"dynamic_templates": [
{
"message_field": {
"path_match": "message",
"mapping": {
"norms": false,
"type": "text"
},
"match_mapping_type": "string"
}
},
{
"string_fields": {
"mapping": {
"norms": false,
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
},
"pinyin": {
"type": "text",
"analyzer": "pinyin"
}
}
},
"match_mapping_type": "string",
"match": "*"
}
}
],
"properties": {
"@timestamp": {
"type": "date"
},
"geoip": {
"dynamic": true,
"properties": {
"ip": {
"type": "ip"
},
"latitude": {
"type": "half_float"
},
"location": {
"type": "geo_point"
},
"longitude": {
"type": "half_float"
}
}
},
"@version": {
"type": "keyword"
}
}
},
"aliases": {}
}
将创建的模版放到一个配置文件logstash-ik.json里
vi logstash-ik.json
logstash-db-product-sync.conf 配置中增加相关模版信息
output {
elasticsearch {
# es地址 不能使用127.0.0.1,使用内网ip或外网ip
hosts => ["192.168.0.146:9200"]
# 同步的索引名
index => "index_products"
# 设置_doc ID和数据相同,如果注释掉就自动生成_doc的ID
document_id => "%{product_id}"
# 模版的自定义名字
template_name => "my-logstash-ik"
# 模版所在位置
template => "/usr/local/logstash/logstash-7.5.2/sync/logstash-ik.json"
# 重写模版项
template_overwrite => true
# false是关闭logstash的自动模版管理,true为按照上面的配置创建mapping模版
manage_template => true
# 这里改为true表示给ES创建一个新模版,这个模版将应用于所有ES的新建索引中(无论是不是logstash创建的)
}
# 这里输出调试,正式运行时可以注释掉
stdout {
codec => json_lines
}
}
更新完毕后要重新启动logstash才能加载新的mapping
正常情况下应该是在后台执行这个命令
nohup ./logstash -f /usr/local/logstash/logstash-7.5.2/sync/logstash-db-product-sync.conf > myout.file 2>&1 &
logstash运行到指定时间后开始导入数据
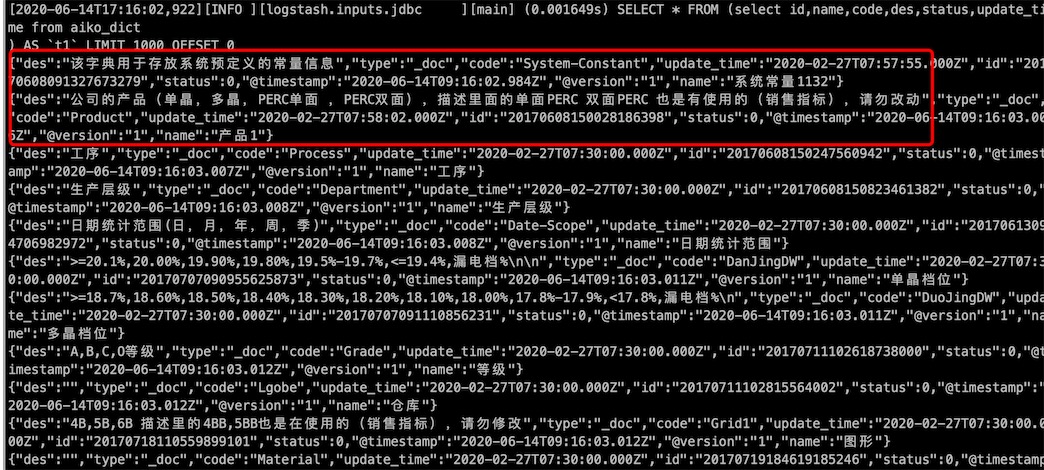
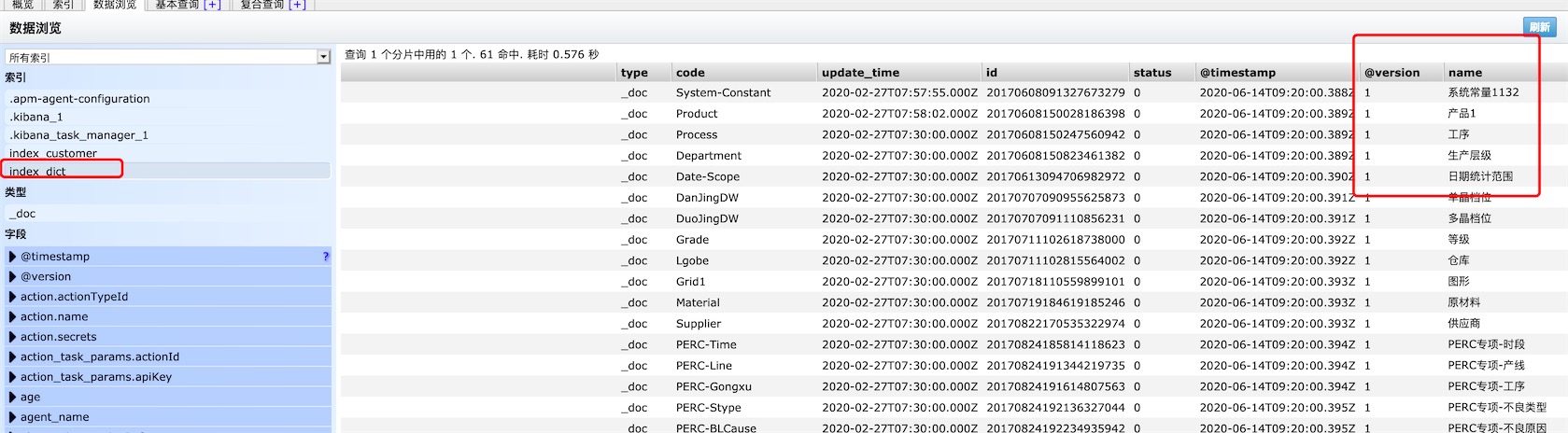
4、整体看一下Elasticsearch都学习了哪些内容