 弹吉他的兔子
弹吉他的兔子
1. 镜像集群宕机恢复方式
RabbitMQ在镜像集群中,机器其实是平行关系,所有的节点都是互相复制的
场景描述:
A是Master
B是Slave
-
A正常运行,B宕机了,只需要启动B即可,B就会自动加入集群
-
A和B都宕机了,只要A在B之前启动就可以了,B也会自动加入集群
-
A和B都宕机了,A启动不起来了,即便是B启动了,有可能B的rabbitmq服务直接启动不了啦
比如B和C都加入了A为Master的集群,但是A启动不起来了,这个时候都需要将B和C从A的集群中forget,B和C的rabbitmq服务启动不起来了,因为无法寻址到A节点,因为A宕机起不来了
# 在B或C上执行
# 在集群服务都不可用的情况下,这个命令是无法执行的,RMQ146就是A服务器,Master节点,在集群服务不可用的情况下无法忘掉
rabbitmqctl forget_cluster_node rabbit@RMQ146
RabbitMQv3.2版本以后提供了一个离线清除集群节点的命令参数,也就是节点无法启动状态下
# 在B或C上执行
# rabbitmq会在当前这个无法启动的节点上Mock一个虚拟节点来提供服务,实现cluster的forget
rabbitmqctl forget_cluster_node --offline rabbit@RMQ146
2. 使用HAProxy实现镜像集群负载均衡
HAProxy是一款提供高可用的负载均衡器(之前大家都是使用的Nginx居多,upstream反向代理实现负载均衡非常容易),HAProxy可以基于TCP四层(Lvs也是TCP四层的),HTTP七层(Nginx是HTTP七层)的负载均衡应用代理软件,免费高速可靠的一种LBS解决方案
HAProxy的并发连接完全可以支持以万为单位的
HAProxy性能最大化的原因
- 单进程,降低了上下文的切换开销和内存占用,(redis也是单进程的)
- 单缓冲机制能以不复制任何数据的方式下完成读写操作,这会大大节约CPU时钟和内存带宽
- HAProxy可以实现零复制的零启动
- 树形存储,使用弹性二叉树
- 内存分配器在固定大小的内存池中实现即时内存分配,减少创建会话的时长
HAProxy和Nginx的最大区别
Nginx,反向代理服务器
优点:
1、工作在网络7层之上,可针对http应用做一些分流的策略,如针对域名、目录结构,它的正规规则比HAProxy更为强大和灵活,所以,目前为止广泛流行。
2、Nginx对网络稳定性的依赖非常小,理论上能ping通就能进行负载功能。
3、Nginx安装与配置比较简单,测试也比较方便,基本能把错误日志打印出来。
4、可以承担高负载压力且稳定,硬件不差的情况下一般能支撑几万次的并发量。
5、Nginx可以通过端口检测到服务器内部的故障,如根据服务器处理网页返回的状态码、超时等,并会把返回错误的请求重新提交到另一个节点。
6、不仅仅是优秀的负载均衡器/反向代理软件,同时也是强大的Web应用服务器。可作为静态网页和图片服务器,在高流量环境中稳定性也很好。
7、可作为中层反向代理使用。
缺点:
1、适应范围较小,仅能支持http、https、Email协议。
2、对后端服务器的健康检查,只支持通过端口检测,不支持url来检测
3、负载均衡策略比较少:轮询、权重、IP_hash、url_hash
HAProxy,专用的负载均衡
优点:
1、HAProxy是支持虚拟主机的,可以工作在4、7层(支持多网段)
2、HAProxy的优点能够补充Nginx的一些缺点,比如支持Session的保持,Cookie的引导;同时支持通过获取指定的url来检测后端服务器的状态。
3、HAProxy跟LVS类似,本身就只是一款负载均衡软件;单纯从效率上来讲HAProxy会比Nginx有更出色的负载均衡速度,在并发处理上也是优于Nginx的。
4、HAProxy支持TCP协议的负载均衡转发,可以对MySQL读进行负载均衡,对后端的MySQL节点进行检测和负载均衡。
5、HAProxy负载均衡策略非常多,HAProxy的负载均衡算法现在具体有如下8种
- roundrobin:轮询
- leastconn:连接数最少的服务器优先接收连接
- static-rr:每个服务器根据权重轮流使用
- source:对请求源IP地址进行哈希
- uri:表示根据请求的URI左端(问号之前)进行哈希
- url_param:在HTTP GET请求的查询串中查找中指定的URL参数,基本上可以锁定使用特制的URL到特定的负载均衡器节点的要求
- hdr(name):在每个HTTP请求中查找HTTP头
,HTTP头 将被看作在每个HTTP请求,并针对特定的节点;如果缺少头或者头没有任何值,则用roundrobin代替 - rdp-cookie(name):为每个进来的TCP请求查询并哈希RDP cookie
;该机制用于退化的持久模式,可以使同一个用户或者同一个会话ID总是发送给同一台服务器。如果没有cookie,则使用roundrobin算法代替
缺点:
1、不支持POP/SMTP协议
2、不支持SPDY协议
3、不支持HTTP cache功能。现在不少开源的lb项目,都或多或少具备HTTP cache功能。
4、重载配置的功能需要重启进程,虽然也是soft restart,但没有Nginx的reaload更为平滑和友好。
5、多进程模式支持不够好
安装HAProxy
HAProxy+Keepalived(负载均衡节点的高可用)# 安装依赖
yum -y install gcc gcc-c++
# 1、下载安装包
wget https://www.haproxy.org/download/1.6/src/haproxy-1.6.15.tar.gz
# 解压到指定目录
tar -zxvf haproxy-1.6.15.tar.gz -C /usr/local/
[root@helloworld ~]# uname -r
3.10.0-514.26.2.el7.x86_64
# 2、进入安装目录
cd /usr/local/haproxy-1.6.15/
# 安装 linux31可以使用 uname -r 查看,取前面两位31,如果上linux6.x版本的是26
# 在haproxy根目录下执行
make TARGET=linux31 PREFIX=/usr/local/haproxy
make install PREFIX=/usr/local/haproxy
mkdir /etc/haproxy
# 3、赋权用户和组授权
groupadd -r -g 149 haproxy
useradd -g haproxy -r -s /sbin/nologin -u 149 haproxy
# 4、核心配置文件的创建,放在/etc/haproxy目录下
touch /etc/haproxy/haproxy.cfg

haproxy.cfg配置文件编写
内容如下:
global # 全局变量
log 127.0.0.1 local0 info # 日志存储到127.0.0.1,以local0输入info级别
maxconn 4096 # 最大连接数,要考虑到ulimit -n的大小限制
chroot /usr/local/haproxy # haproxy的安装目录
user haproxy
group haproxy
daemon # 后台进程
nbproc 2 # 进程数,这里开启俩个进程
pidfile /var/run/haproxy.pid # pid文件位置
defaults
log global
mode tcp # 使用tcp4层代理模式,
option tcplog
option dontlognull
retries 3
# 在使用基于cookie定向时,一旦后端某一server宕机时,会将会话重新定向至某一上游服务器,必须使用的选项
option redispatch
maxconn 4096 # 最大连接数
timeout connect 5s
timeout client 60s #客户端空闲超时时间
timeout server 15s #服务端超时时间
listen rabbitmq_cluster(自定义名称) # 服务监听,这里监听rabbitmq的服务web请求
bind 0.0.0.0:5672 # 不限制访问的ip,可以设置具体ip(例如应用所在的服务器ip)才可以访问haproxy的5672端口
mode tcp
balance roundrobin #采用轮询机制,还可以是其他的负载均衡方式
#rabbitmq集群节点配置,inter每隔3秒对MQ集群做健康检查,RMQ164,RMQ165就是前面配置rabbitmq镜像集群的服务器名字
# rise 2 重试检查次数 ,fall 2 失败2次后就不检查
server RMQ164 192.168.0.164:5672 check inter 3000 rise 2 fall 2
server RMQ165 192.168.0.165:5672 check inter 3000 rise 2 fall 2
server RMQ166 192.168.0.166:5672 check inter 3000 rise 2 fall 2
#配置haproxy web监控,查看统计信息,如果使用nginx的upstream反向代理就紧紧是路由而已
listen stats (自定义名称)
bind 192.168.0.168:8999 #这里得配置内网IP,然后用外网IP访问即可
mode http
option httplog
stats enable
#设置haproxy监控地址为http://39.101.209.123:8999/rabbitmq-stats
stats uri /rabbitmq-stats
stats refresh 3s # 监控信息每3秒刷新
将上面的配置文件内容放入 /etc/haproxy/haproxy.cfg中
vi /etc/haproxy/haproxy.cfg
启动HAProxy
# 进入安装目录
cd /usr/local/haproxy/sbin
./haproxy -f /etc/haproxy/haproxy.cfg
启动后,访问监控地址http://39.101.209.123:8999/rabbitmq-stats
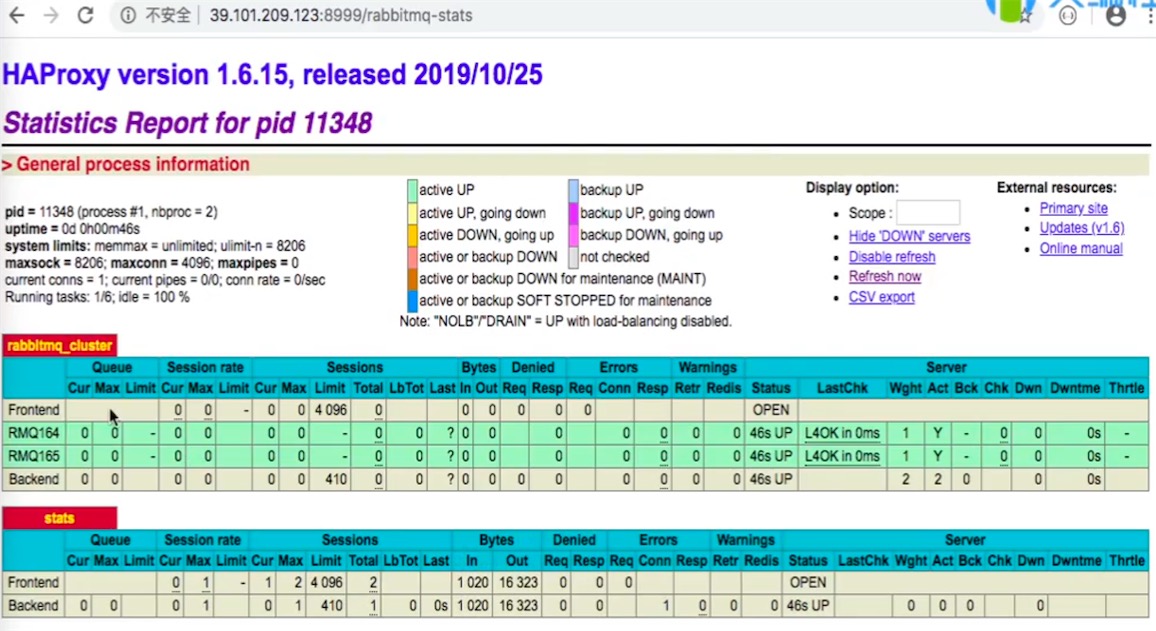
# 停掉一个节点(不要是master节点), 停止rabbitmq服务
rabbitmqctl stop_app
监控界面发生了变化,down掉的节点变为红色
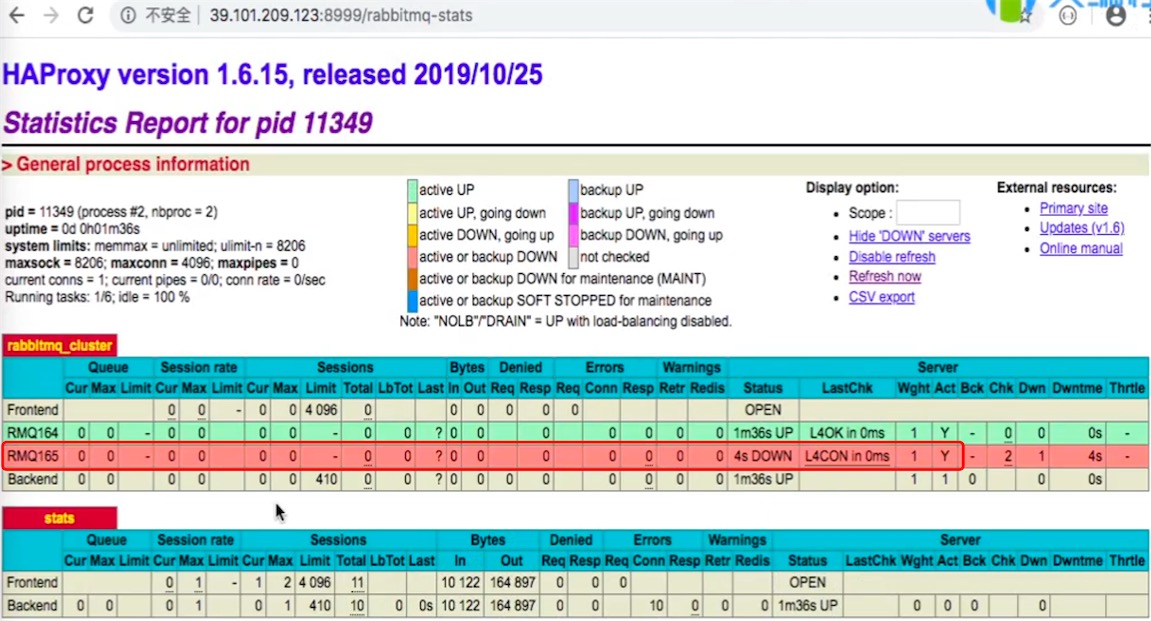
# 重新启动
rabbitmqctl start_app
测试
springboot项目改为连接Haproxy而不是具体的某个rabbitmq节点,继续使用前面博客使用的工程
修改application.yaml
spring:
rabbitmq:
host: 39.101.209.123 # haproxy 节点
port: 5672 # 默认5672
username: guest # 访问的用户密码
password: guest
virtual-host: / # exchange 和 queue所在的虚拟空间目录
connection-timeout: 15000 # 连接超时时间15秒
3. 使用Federation跨机房多活集群模式
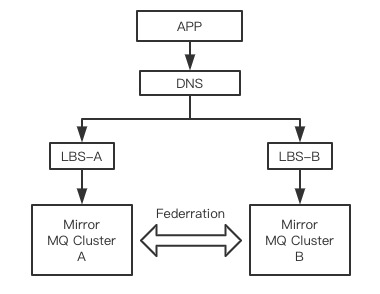
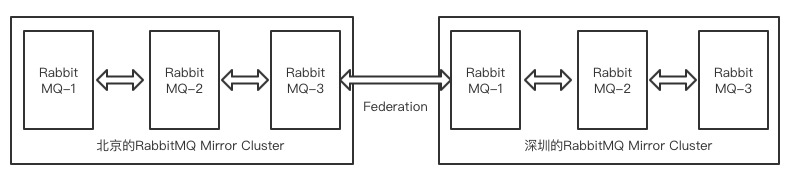
federation就是一个数据通道,在两个不同机房的镜像集群各选1个节点来做连接(信使),然后数据再同步复制到同集群下的其他镜像节点
搭建多活模式
# 首先准备两个非集群节点,后面可以自己搭建两个镜像集群包含两个federation通信的节点
# 看插件
[root@helloworld ~]# rabbitmq-plugins list
rabbitmq_federation
rabbitmq_federation_management
# 两台联通的机器(rabbitmq 节点)都要启动这两个插件
rabbitmq-plugins enable rabbitmq_federation
rabbitmq-plugins enable rabbitmq_federation_management
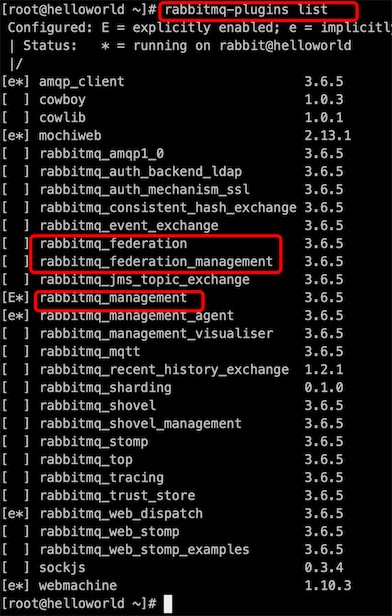
启用成功后可以登录rabbitmq控制台进行验证
通过federation的配置来进行数据通道搭建
注意:
这个时候你需要自己定义一个上游节点upstream(166节点),一个下游节点downstream(167节点),federation是单向发送的,相当于消息发送到upstream的一个exchange上,然后转发到downstream的queue上,其实就是跨网络的消息转发(对比一下局域网内的镜像集群节点间互相复制数据 )
步骤:
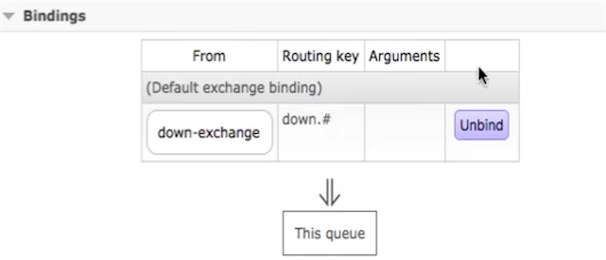
1、在下游节点创建一个exchage和一个queue和binding的routingkey,用来进行数据接收
在下游节点167创建down-exchange和down-queue,绑定routingkey为down.#
2、在下游节点建立federation upstream规则和上游节点进行数据同步
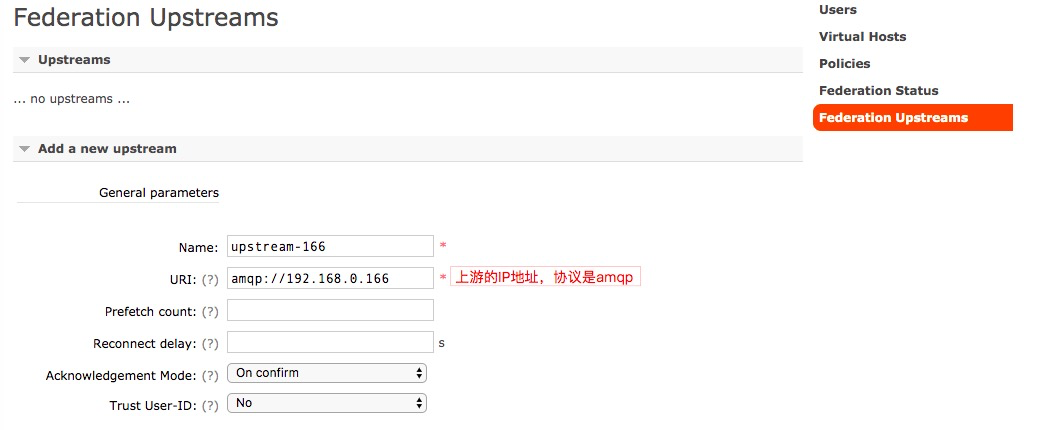

3、进入下游节点的federation status没有任何数据,需要建立策略来保证通道连通
4、进入下游节点的Policy菜单,Pattern是个正则表达式,这里表示以down开头的exchange和queue都匹配
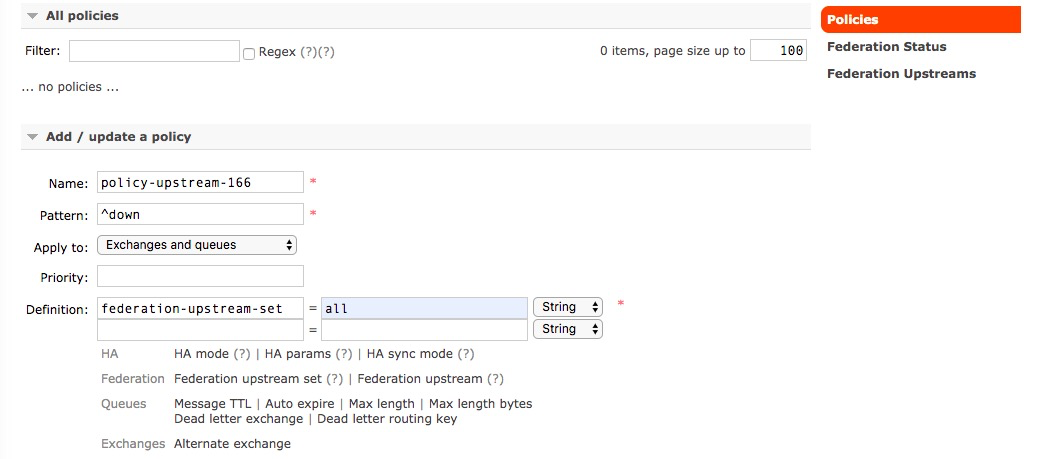
Pattern: 正则表达式, ^down,表示down开头的exchange和queue都匹配
Apply to:Exchanges and queues 交换机和对列都匹配
5、这个时候看exchange和queue,规则就应用上了

6、这个时候去federation status看,发现上游连接已经连接上了

7、这个时候我们先去看上游节点(166)的overview,有两个连接,两个会话channel刚好对应下游节点(167)的down-exchange和down-queue的连接,1个consumer就是下游

8、再看上游的exchange和queue就已经根据下游配置的upstream和policy规则将exchange和queue创建好了(自动创建,但是没有做routing key binding )


灰色的这个重定向exchange不能直接发送消息,如果要发送则在down-exchange上进行发送。上游不需要做配置,只需发送消息到down-exchange
9、在上游控制台的down-exchange发送一条消息,进行测试
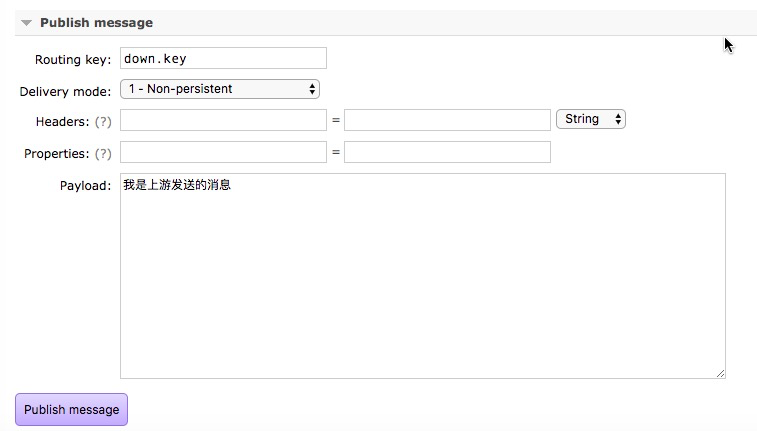
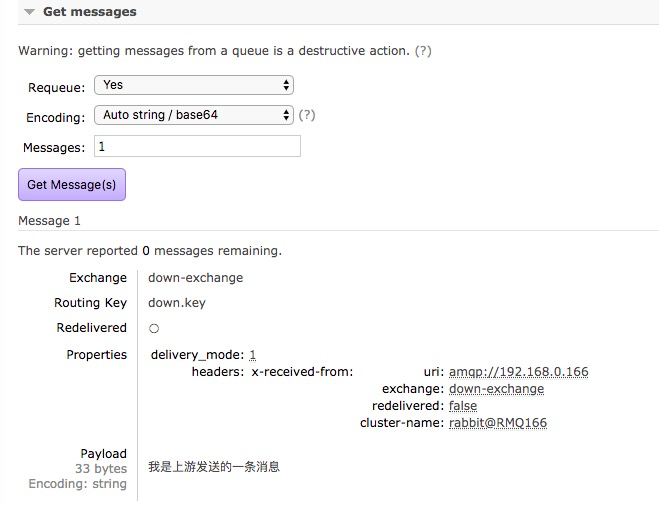
可以在下游控制台查看这条消息
10、因为上游节点只是一个中转,如果上游节点也要消费 down-exchange里的消息怎么办?
点进上游节点的down-exchange,发现它binding的是下游节点的down-exchange,所以消息转发了
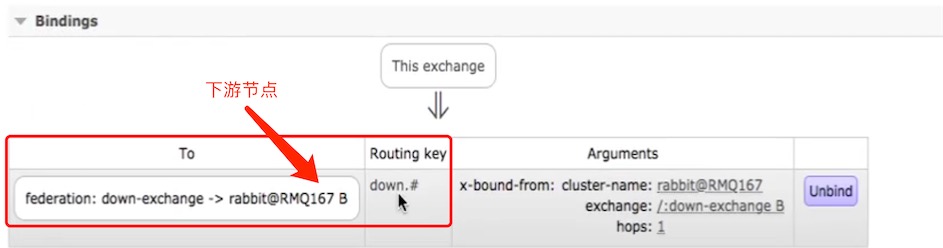
上游节点的down-exchange都bingding了down-queue和下游的down-exchange,这样上游节点也可以消费down-exchange的消息
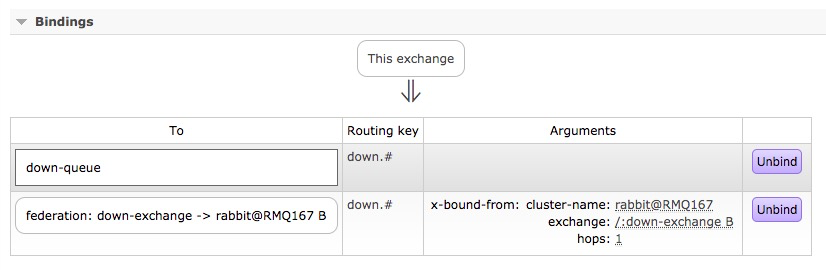
消息发送到了本地queue和远程queue。
测试,发送第二条消息
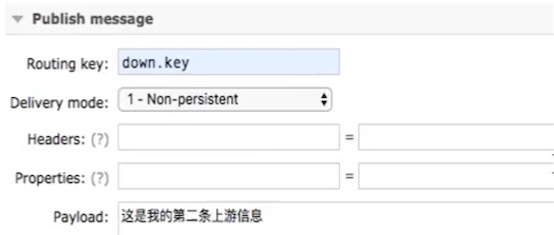
查看本地queue,发现有消息了
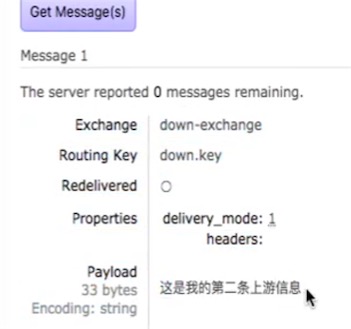
查看远程queue,发现有消息了
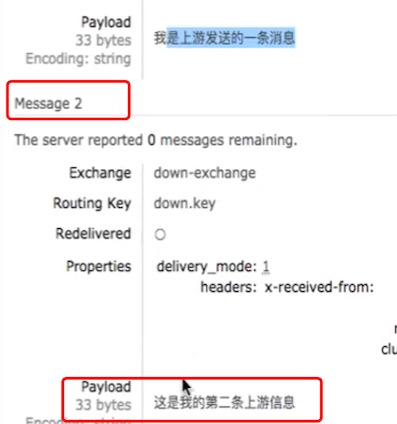
上下游数据的消费是否互相影响
上游同时接收到的数据消费后不影响下游发送过去的信息,就是说消费不会同步,因为是两个不同的镜像集群,federation只是单向发送消息。
4. 消息延迟发送机制的实现
Delay的应用场景:用户下了个单,30分钟后如果没有支付,我就将订单关闭,5分钟一轮询(29分钟+5)
实现有两种方式:
通过死信队列来实现
在消息发送的时候设置消息的TTL,并将该消息发送到一个没有人消费的队列上,将这个没有人消费的队列配置成死信触发队列:x-dead-letter-exchange、x-dead-letter-routing-key 当消息超过TTL后转发发给一个具体的执行队列,这个执行队列的消息需要监听和消费,当消息一进来就消费掉,这个消息的TTL就是delay的时长
通过延时插件实现消息延时发送
延时插件的配置
# 1、这个插件默认是不带的,需要下载,需要确保大版本和rabbitmq一致,我这里rabbitmq使用的版本是3.6.5
wget https://dl.bintray.com/rabbitmq/community-plugins/3.6.x/rabbitmq_delayed_message_exchange/rabbitmq_delayed_message_exchange-20171215-3.6.x.zip
# 解压
unzip rabbitmq_delayed_message_exchange-20171215-3.6.x.zip
# 2、移动到rabbitmq的插件目录下
mv rabbitmq_delayed_message_exchange-20171215-3.6.x.ez /usr/lib/rabbitmq/lib/rabbitmq_server-3.6.5/plugins/
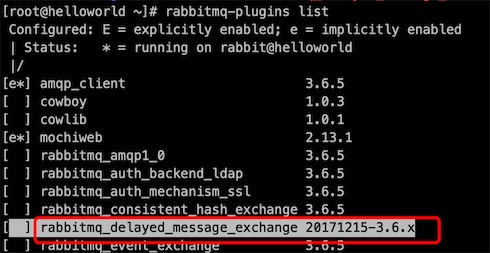
# 3、解压并移动到plugins目录后先看一下是否成功,插件是热加载的,不用停服务
[root@helloworld ~]# rabbitmq-plugins list
# 4、启动插件
[root@helloworld ~]# rabbitmq-plugins enable rabbitmq_delayed_message_exchange
应用完毕后看是否加载成功,登录控制台add exchange发现type多了一个x-delayed-message

注意:如果是集群需要所有机器节点都加载这个插件
创建延时exchange
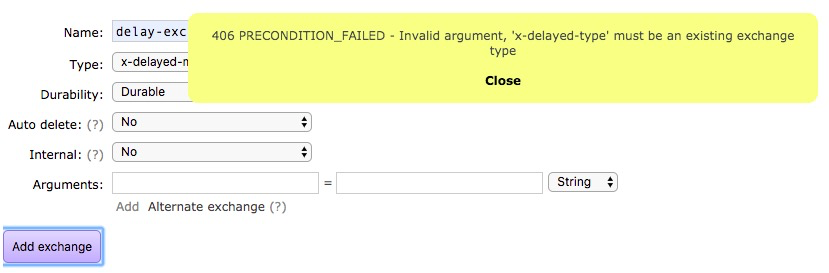
出现的提示意思是需要你通过arguments来指定延迟交换机的type匹配类型,如下配置
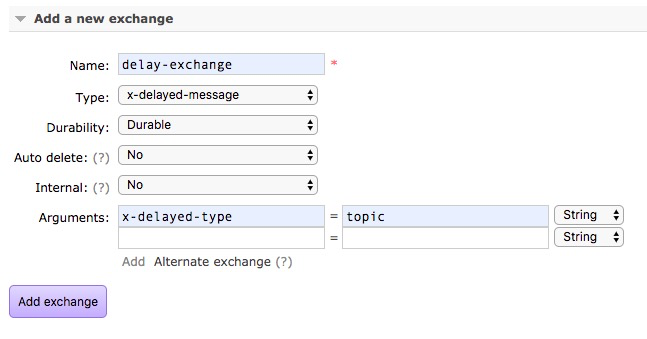
创建queue
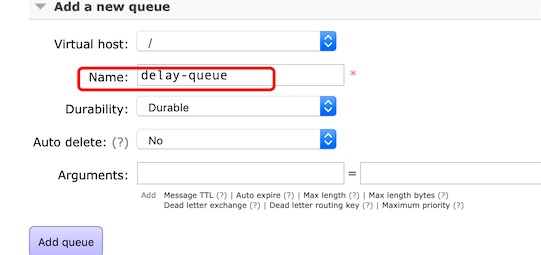
binding

测试延时消息
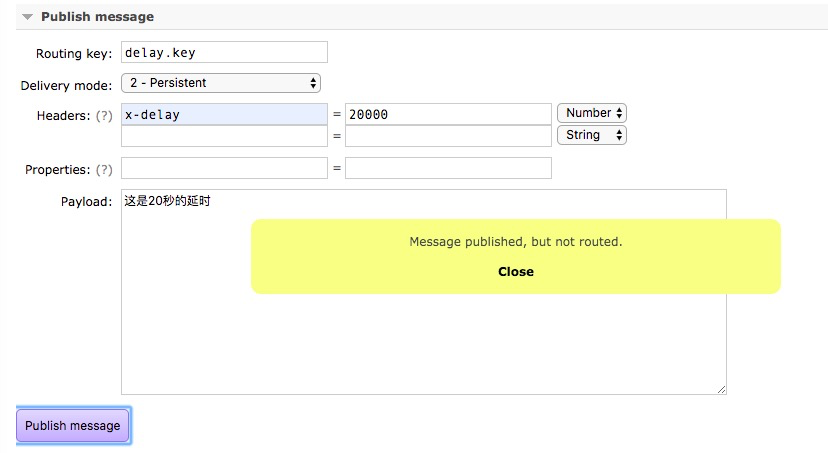
点击发送,20秒后,delay-queue得到消息

,20秒后数据是能进入队列的,为什么提示not routed?
因为是延时队列,是发送到exchange成功了,但还没有到时间的时候exchange没有进行routing操作,这时数据还在exchange里,没有到queue里
应用场景
消息延时发送到对列,邮箱从对列中获取消息发送,实现延时发送邮件
5. springboot实现延时信息的收发
发送方
import com.icoding.basic.po.OrderInfo;
import org.springframework.amqp.AmqpException;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.core.MessagePostProcessor;
import org.springframework.amqp.rabbit.connection.CorrelationData;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class OrderSender {
@Autowired
RabbitTemplate rabbitTemplate;
public void sendOrder(OrderInfo orderInfo) throws Exception{
/**
* exchange: 交换机名字
* routingkey: 队列关联的key
* object: 要传输的消息对象
* correlationData: 消息的唯一id
*/
CorrelationData correlationData = new CorrelationData();
correlationData.setId(orderInfo.getMessage_id());
MessagePostProcessor messagePostProcessor = new MessagePostProcessor() {
@Override
public Message postProcessMessage(Message message) throws AmqpException {
message.getMessageProperties().getHeaders().put("x-delay",20000);
return message;
}
};
rabbitTemplate.convertAndSend("delay-exchange-other","delay.key",orderInfo,messagePostProcessor,correlationData);
}
}
// lambda表达式的写法
public void sendOrder(OrderInfo orderInfo,String ttl){
CorrelationData correlationData = new CorrelationData();
correlationData.setId(orderInfo.getMessageId());
// 支持函数式接口
rabbitTemplate.convertAndSend("delay-exchange-other","delay.key",orderInfo,message -> {
//message.getMessageProperties().setExpiration(ttl);
message.getMessageProperties().getHeaders().put("x-delay",20000);
return message;
},correlationData);
}
接收方
import com.icoding.basic.po.OrderInfo;
import com.rabbitmq.client.Channel;
import org.springframework.amqp.rabbit.annotation.*;
import org.springframework.amqp.support.AmqpHeaders;
import org.springframework.messaging.handler.annotation.Headers;
import org.springframework.messaging.handler.annotation.Payload;
import org.springframework.stereotype.Component;
import java.util.Map;
@Component
public class OrderReceiver {
int flag = 0;
@RabbitListener(bindings = @QueueBinding(
value = @Queue(value = "delay-queue-other",durable = "true",autoDelete = "false"),
exchange = @Exchange(value = "delay-exchange-other",durable = "true",type = "x-delayed-message",arguments = {
@Argument(name = "x-delayed-type",value = "topic")
}),
key = "delay.#"
)
)
@RabbitHandler
public void onOrderMessage(@Payload OrderInfo orderInfo, @Headers Map<String,Object> headers, Channel channel) throws Exception{
System.out.println("************消息接收开始***********");
System.out.println("Order Name: "+orderInfo.getOrder_name());
Long deliverTag = (Long)headers.get(AmqpHeaders.DELIVERY_TAG);
//ACK进行签收,第一个参数是标识,第二个参数是批量接收为fasle
channel.basicAck(deliverTag,false);
}
}