 弹吉他的兔子
弹吉他的兔子
1. kafka的主要特点分析
kafka是一个分布式的发布订阅消息系统,由linkedin开发,现在成为了apache的项目一部分
- 同时可以为发布和订阅提供高吞吐量的访问,kafka每秒可以生产25万消息(50MB),每秒可以处理55万消息(110MB,因为只有读取的操作,没有存储操作所以更快一些)
- 可以进行持久化的操作。将消息持久化大磁盘,因此可以进行批量消息的处理,还提供replcation防止数据丢失
- 分布式系统,易于向外扩展,**所有的producer、broker、consumer都会有多个**,这些都是分布式的,无需停机就可以进行扩展(使用zookeeper)
- **消息的处理状态是在consumer端维护,不是在server端(broker)维护,失败的时候能够自动平衡**
- 支持online 线上和offline 线下场景
- kafka不支持事务,对消息的丢失,错误没有太严格的要求
2. kafka的架构模型分析
kafka的整体架构非常简单,是一种显示分布式架构,数据是从producer(生产者)发送到broker,broker承担了一个中间缓存的分发作用,分发给注册到broker的consumer
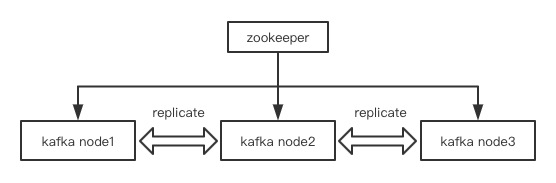
集群结构是什么样的?
整个集群是通过zookeeper进行节点的发现和注册,kafka节点间进行数据的复制备份
- 基本概念:可以对比ElasticSearch的索引index和分片shard来学习,它们是非常相似的,topic就相当于索引,partition就相当于分片
- Topic:是消息的一个分类,你可以理解为他就是不同的队列(queue),kafka是以topic进行消费分类的(对比rabbitmq的topic是exchange的分类,就是对routingkey的模糊匹配分发到不同routingkey对列)
- Partition:topic是一个逻辑上的概念,而partition是topic物理上的一个分组/分区,一个topic可以分为多个partition,每个partition也都是有序的队列,partition中的每个消息都会被分配一个有序ID(offset),分区数量自己指定
- Message:消息体本身
- Producers:消息的生产者
- Consumers:消息的消费者
- Broker:就是kafka的服务本身,缓存代理(落盘与RAM的方式 ,rabbitmq也有这两种方式)
- 发送消息的流程
- producer发送一个message给到指定的topic(理解为队列)
- topic会将接收到消息分配给他的partition进行保存(partition数量是你自己指定的),这点真的像ES的索引和分片
- 如果你设置了follower分区,并且有多个节点的情况下,所有的主分区不在一个机器上
- consumer是进行数据消费的,一个partition只能同时被一个consumer group中的消费者消费,多个分区就有多个消费者消费,这就可以提升消费能力
- 在v0.9版本之前消息的有序ID(offset)是放在zookeeper中,后面放在自己的磁盘上了
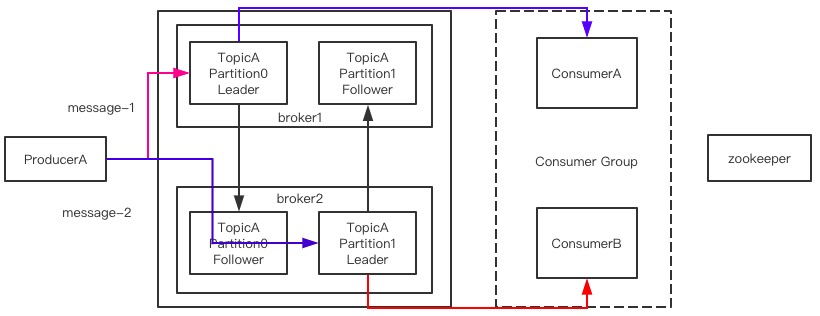
Leader和Follower不会放在同一个broker上,体现HA高可用,一个broker宕机了,我的数据还是完整的。
和ES不同的是,ES的副本分片可以负载均衡分担主分片的读取数据压力(轮询策略),kafka的Follower分区只做备份的作用,不对外提供读取数据的服务,只有在Leader分区挂了后,它才会被选举为新的Leader分区提供写和读的服务。kafka的写读都是在Leader分区
3. kafka的内部设计特点
- 高吞吐能力:为了实现高吞吐能力做了以下设计
- 内存访问,使用pagecache来进行高效缓存
- zero-copy:减少I/O的操作
- 对消息的处理是支持批量发送和压缩的
- topic分区,将消息文件(落盘持久化)分散多个机器上进行存储,这就能利用好分布式的优势,存储也能水平扩展了
- 负载均衡
- producer可以根据用户指定的算法(如果没有指定就是roundrabin 轮询),将消息发送到指定的partition 中
- 每个partition都有自己的replica(follower 分区),replicat分布在不同的broker节点上
- zookeeper可以动态的加入新的broker节点,实现动态水平扩展能力
- 消息拉取
- 数据是通过broker来进行pull的方式
- consumer可以根据消费能力自主控制消息的拉取速度,因为它是拉的方式消费的,是以consumer group的方式消费
- 可扩展性:broker可以通过zookeeper动态增加
4. kafka的应用场景分析
- 消息队列:大规模消息处理应用解决方案,在消息队列领域,kafka足以媲美ActiveMQ、RabbitMQ
- 行为跟踪
- 元信息监控
- 日志收集
- 流处理
- 事件源,程序设计的方式, 按照一定的时间顺序记录相应日志和操作轨迹
- 持久化日志
5. kafka安装部署
安装的前置条件:JDK、zookeeper
安装zookeeper集群
# 由于kafka的服务协调是基于zookeeper实现的,所以要先下载安装zookeeper
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.5.7/apache-zookeeper-3.5.7-bin.tar.gz
# 下面在单机上(不同端口)安装zookeeper集群(伪集群)
# 创建集群文件夹
mkdir zookeeper-cluster
# 1、解压,重命名
tar -zxvf apache-zookeeper-3.5.8-bin.tar.gz
[root@helloworld zookeeper-cluster]# mv apache-zookeeper-3.5.8 zookeeper1
# 提前把data和logs文件创建好
# 2、在conf里修改zoo_sample.cfg为zoo.cfg进行修改
[root@helloworld conf]# cp zoo_sample.cfg zoo.cfg
[root@helloworld conf]# vim zoo.cfg
dataDir=/usr/local/zookeeper-cluster/zookeeper1/data
dataLogDir=/usr/local/zookeeper-cluster/zookeeper1/logs
clientPort=2181 # 每个机器的端口不能一样
#maxClientCnxns=60 # increase this if you need to handle more clients,生产环境中注意一下这个参数
server.1=127.0.0.1:2881:3881
server.2=127.0.0.1:2882:3882
server.3=127.0.0.1:2883:3883 # 增加通信内容三台机器一样:server.服务编号=服务地址:LF通信端口:选举端口
# 在三台机器的data目录dataDir=/usr/local/zookeeper-cluster/zookeeper1/data
# data里创建文件myid,三台分别写入值1、2、3
cd /usr/local/zookeeper-cluster/zookeeper1/data
[root@helloworld data]# vim myid
1
# 3、复制
[root@helloworld zookeeper-cluster]# cp -r zookeeper1/ zookeeper2
[root@helloworld zookeeper-cluster]# cp -r zookeeper1/ zookeeper3
# 修改zoo.cfg和myid
cd /usr/local/zookeeper-cluster/zookeeper2/data
[root@helloworld data]# vim myid
2
cd /usr/local/zookeeper-cluster/zookeeper3/data
[root@helloworld data]# vim myid
3
# 4、创建的sh文件统一启动zookeeper,zookeeper-start.sh
[root@helloworld zookeeper-cluster]# vim zookeeper-start.sh
/usr/local/zookeeper-cluster/zookeeper1/bin/zkServer.sh start
/usr/local/zookeeper-cluster/zookeeper2/bin/zkServer.sh start
/usr/local/zookeeper-cluster/zookeeper3/bin/zkServer.sh start
# 批处理文件授权
chmod 777 zookeeper-start.sh
# 启动zookeeper集群
./zookeeper-start.sh
# 5、服务管理命令
zkServer.sh start|stop|restart|status
# 客户端连接,客户端关闭:quit ,推荐使用界面操作工具zooInspector,因为zookeeper的数据是树形结构存储的,使用界面会更为直观
zkCli.sh -server ${ip}:${port}
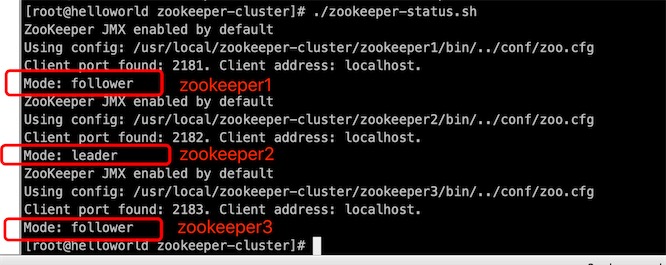
可以看到zookeeper2是leader节点
安装kafka并进行基础配置
# 下载kafka
wget http://mirror.bit.edu.cn/apache/kafka/2.4.0/kafka_2.13-2.4.0.tgz
# 1、解压后移动到/usr/local下
tar -xvf kafka_2.13-2.4.0.tgz
mv kafka_2.13-2.4.0 kakfa
mv kafka /usr/local/
# 2、进入config目录,修改server.properties
[root@helloworld config]# vim server.properties
# kafka的broker编号,必须是一个整数,服务编号,在集群中不能一样
broker.id=11
# topic允许删除的,如果你设置成false,删除topic对kafka是无效的,默认就是true
delete.topic.enable=true
port=9092
# 处理网络请求的线程数量
num.network.threads=3
# 磁盘IO的线程数量
num.io.threads=8
# 发送socket的缓冲区大小
socket.send.buffer.bytes=102400
# 接收socket的缓冲区大小
socket.receive.buffer.bytes=102400
# 请求socket的缓冲区大小
socket.request.max.bytes=104857600
# 是保存消息日志的文件目录,data目录要提前创建好,partition分区就存放在这个目录下
log.dirs=/usr/local/kafka/data
# topic在创建时默认多少个分区
num.partitions=1
# 我们的消息数据默认保存时间长度,单位是小时 168小时=7天,不是永久保存
# The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=168
# 一个log文件的大小,这里默认是1G,如果超过1G就再创建一个新文件
log.segment.bytes=1073741824
# zookeeper的集群地址
zookeeper.connect=127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183
启动和关闭服务
# 启动服务命令,要指定配置文件,后台启动
/usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
# 关闭服务命令
/usr/local/kafka/bin/kafka-server-stop.sh /usr/local/kafka/config/server.properties
单机已经启动了,集群只需要我们和单机一样将新的kafka加入到同一个zookeeper里即可,但broker.id需要和其他机器不一样
进入zookeeper客户端查看kafka节点

把kafka/bin加入环境变量
[root@helloworld local]# vim /etc/profile
export KAFKA_HOME=/opt/kafka
export PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$KAFKA_HOME/bin
# 使配置生效(已连接的会话需要重新连接)
source /etc/profile
# 加入环境变量后,直接使用命令
kafka-server-start.sh
6. kafka内部命令使用
# 0.查看topics命令帮助
kafka-topics.sh --help
# 1.查看当前服务器中所有的topic,需要连接zookeeper节点
kafka-topics.sh --zookeeper 127.0.0.1:2181 --list
# 2.创建topic,--replication-factor
kafka-topics.sh --zookeeper 127.0.0.1:2181 --create --partitions 3 --replication-factor 1 --topic topicfirst
# Error while executing topic command : Replication factor: 2 larger than available brokers: 1.
--topic # topic名称
--partitions # 定义分区数,partition的命名规则<topicName-partiton序号>
--replication-factor # 副本数量,1代表就是当前主分区没有副本,2代表每个主分区有一个副本分区,副本分区和主分区不能在同一个broker
# topic创建后,进入log.dirs=/usr/local/kafka/data 存储目录,发现topicfirst的3个分区文件夹
[root@helloworld data]# ls
topicfirst-0 topicfirst-1 topicfirst-2
[root@helloworld data]# cd topicfirst-0
[root@helloworld topicfirst-0]# ls
00000000000000000000.index 00000000000000000000.log 00000000000000000000.timeindex leader-epoch-checkpoint
# 000000000是偏移量
# 3.删除topic
# 如果配置文件server.properties里delete.topic.enable设为false,删除是无效的
# Note: This will have no impact if delete.topic.enable is not set to true.
kafka-topics.sh --zookeeper 127.0.0.1:2181 --delete --topic topicfirst
# 4.查看topic的详情
kafka-topics.sh --zookeeper 127.0.0.1:2181 --describe --topic topicfirst
# 5.修改topic分区数,注意分区只能增加,不能减少,因为可能会破坏分区数据
kafka-topics.sh --zookeeper 127.0.0.1:2181 -alter --topic topicfirst --partitions 5


发送和接收消息
命令都在kafka/bin目录下,可以通过–help查看命令帮助

[root@helloworld bin]# ./kafka-console-producer.sh --help
# 发送消息,broker是集群多个的话,要用,隔开,如192.168.1.120:9092,192.168.1.130:9093,192.168.1.140:9092
kafka-console-producer.sh --topic topicfirst --broker-list 127.0.0.1:9092
# 接收消息
# --from-beginning 如果加了,会从topic头来接收消息(监听前已发送的消息已持久化,需要加该参数进行接收)
kafka-console-consumer.sh --topic topicfirst --from-beginning --bootstrap-server 127.0.0.1:9092

为什么?因为topicfirst有5个分区,发送消息的时候,消息轮询放入分区,由于一个分区只能同时被一个consumer group中的消费者消费,所以有5个消费者从5个分区里读取数据,基本上都是无序的。想有序读取数据,那就创建topics 时指定只有1个分区,那就只有一个消费者进行消费,就是有序的。
7. kafka内部文件存储结构
在kafka的v0.9版本前,是通过zookeeper来保存我们的消费offset数据的,但zookeeper的读写操作会影响kafka性能,所以在新版本就把消费的offset数据保存到本地的data目录里,这个data目录是你自己指定的log.dirs目录,默认有50个consumer_offsets目录,里面存储的是每个topic消息消费的位移情况

发送的消息数据到底是存放在哪个文件里的?找到topic的分区,默认轮询
[root@helloworld data]# cd topicfirst-0
[root@helloworld topicfirst-0]# ls
00000000000000000000.index # 保存的消息的顺序编号
00000000000000000000.log # 实际保存消息数据的
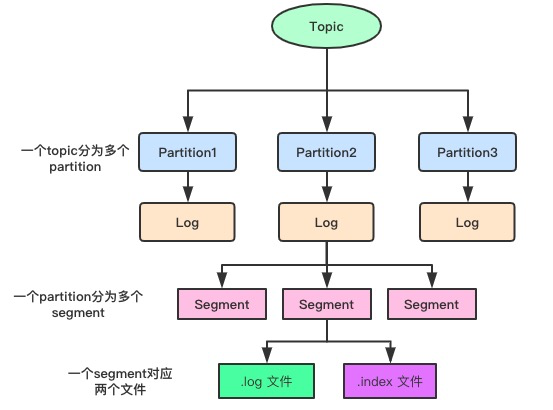
由于生产者生产数据的时候是会不断将数据追加到log文件的末尾,为了防止文件过大,数据定位的效率低下,kafka采用了分片和索引机制,将每个partition分为了多个segment(块),每个segment对应了两个文件index文件和log文件,这些文件都在一个文件夹下
- log文件是具体保存数据的,如果文件超过大小就会生成第二个,文件命名是这样的
- 0000000000000000000.log 这里的0就是文件的offset的起点
- 0000000000000013938.log 这里的13938就是上个文件end_offset+1
- index文件是具体存放消息索引信息的,如果consumer刚好消费时跨了两个log文件,就需要index支持定位了,log和index是成对出现的
8. kafka生产者分析
8.1. 生产者分区的原则
为什么要分区
- 提升了水平扩展能力
- 提供并发能力
分区的原则
- 指明partition的情况下,直降将指明的值作为partition的值(指定存放分区)
- 没有指明partition,但有key的情况下,会将key的hash值与topic的partition数量进行取余得到partition值,具体放入那个分区
- 什么都没有指定,在第一发消息的时候,系统会随机生成一个整数来对topic的partition数量进行取余得到partition值,后面每次都对这个已经生成的随机数进行+1,这就得到了round-robin算法了(轮询的方案)
8.2. Kafka副本的复制方案ISR机制
8.2.1. 副本的复制方式分析
Kafka内部发送响应的机制:为了保证producer的数据能够可靠的发送并保存到topic上,topic的每个partition收到发送的数据后,都需要向生产者发送ACK(确认消息发送到topic),如果生产者收到ACK,就会进行下一轮发送,如果没有收到就会重新发送
副本的复制是如何复制的?
思考一个问题:是数据发送到leader分区就完成返回ACK,还是要同步复制到所有follower完成后才返回ACK ?
Producer—>leader(follower1,follower2)
这个情况下应该如何向Producer发送ACK
方案一:确保半数以上的follower完成同步,就发送ACK,优点是延迟低,在选举新的leader的时候,如果容忍n台节点故障,就需要2n+1个副本
方案二:完成全部follower的同步,才发送ACK,缺点是延迟高,在选举新的leader的时候,如果容忍n台节点故障,只就需要n+1个副本
kafka使用方案二作为follower的同步方式,全部同步完成才返回ACK
- 如果选择方案一:虽然网络延迟低,但数据一致性无法保障,而且需要2n+1个副本,副本过多就会导致数据冗余过大,造成很大浪费
- 虽然方案二延迟高,但对于kafka来说影响不大,
8.2.2. 通过ISR优化副本同步
先看一下topic的详细信息
kafka-topics.sh --zookeeper 127.0.0.1:2181 --describe --topic topicfirst
Topic: topicfirst PartitionCount: 5 ReplicationFactor: 1 Configs:
Topic: topicfirst Partition: 0 Leader: 11 Replicas: 11 Isr: 11
Topic: topicfirst Partition: 1 Leader: 11 Replicas: 11 Isr: 11
Topic: topicfirst Partition: 2 Leader: 11 Replicas: 11 Isr: 11
Topic: topicfirst Partition: 3 Leader: 11 Replicas: 11 Isr: 11
Topic: topicfirst Partition: 4 Leader: 11 Replicas: 11 Isr: 11
这里的11是broker的id,在config/server.properties 配置
可能发送的问题:
如果kafka采用第二种方案进行副本复制后进行ACK响应,会等待所有follower完成同步,这个时候如果有一个follower因为某种原因无法访问,这个时候leader就要一直等着这个follower来完成同步才能发ACK给producer
Kafka的解决方案:Leader维护了一个动态的in-sync replica set(ISR),保持同步的follower集合
-
副本同步机制
- 作用是和leader保持同步的follower集合
- 当ISR中的follower完成数据同步之后,leader就会给follower发送ack(数据是由follower主动从leader那里拉取过来的)
-
ISR是一个动态同步集合:从ISR中移除follower的条件是当follower长时间未向leader拉取数据,该follower就会被剔除出ISR,时间阀值由:replica.lag.time.max.ms=10000 决定 单位ms,心跳
replica.lag.max.messages 这个是leader和follower的消息数的差值,超过就剔除出ISR,这个参数在0.9版本已经移除

-
当leader发生故障了,就会从ISR中选举新leader