 弹吉他的兔子
弹吉他的兔子
1. Kafka生产者的ACK机制(可靠性)
ACK(在rabbitmq里面,我们producer和broker的一个反馈是什么?confirmCallback(识别到exchange层),returnCallback(routingkey不正确才有返回))
对于Kafka不太重要的数据是不是就不需要可靠性很高了
副本机制,Topic的主分区–副本分区
Producer发送给Broker–>Partition(leader)–>Replication(2)
这个时候,我们思考生产者的ACK机制,producer通过一个配置项ACKS查看kafka生效的是那个机制,有3个值:
- acks = 0 : Producer只要给到Broker就返回ack,不用等待放入Partition,当Broker接收到数据后,有可能Broker故障导致数据丢失
- acks =1 : Partition的Leader落盘成功后才返回ACK,不关心Follower,当我们的partition的leader挂掉后数据就无法同步到follower,注意数据是follower拉取leader的,不是leader主动推的(leader挂了,要从ISR的分区中选举生成新的leader,有可能新leader 和 follower的数据刚好不一致)
- acks = -1 : 所有ISR列表中的Follow分区都同步成功才会返回ACK给Producer
Kafka的Producer在没有接收到ACK后会重试,这个重试是有次数的,这个次数是你配置的
看官方文档的配置项:http://kafka.apache.org/23/documentation.html#producerconfigs
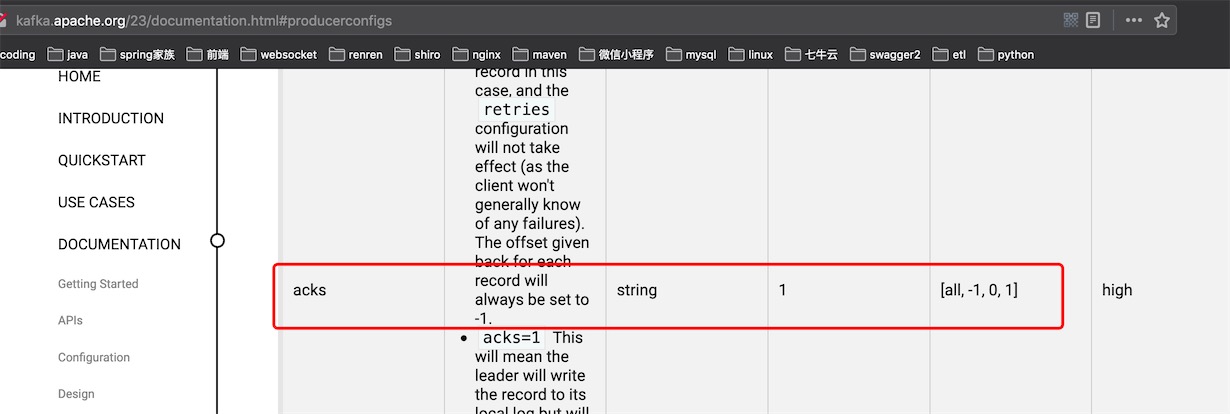
可以看到默认值是1,只要Partiton的Leader收到数据就返回ACK
2. Kafka分布式保存数据一致性问题
producer有一个重试机制,如果数据没有接收到ACK的情况下,重新再次发送
场景分析:如果有一个leader,两个follower,当leader宕机了
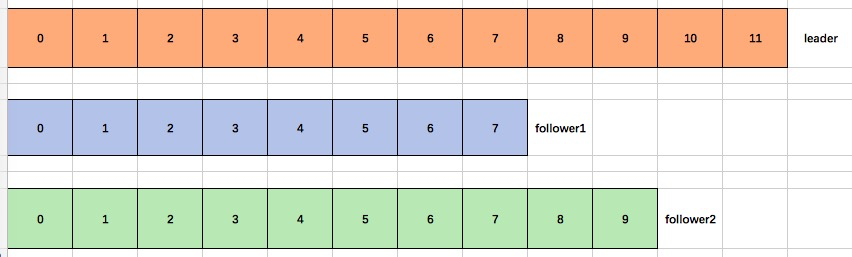
LEO(Log End Offset):每个副本最后一个offset
HW(High Watermark):所有副本中最小的那个LEO(7)
数据一致性的执行细节:
1、follower故障
follower发生故障就会被剔除出ISR,待follower恢复后,follower会读取本次磁盘上上次记录的HW(7),将log文件中高于HW部分截取掉(不要了),从HW开始向leader进行同步,确保数据的完整性,正确性,待follower的LEO大于等于Partition副本的HW,当follower追上leader以后,就可以重入ISR
2、leader故障
leader故障之后,会从ISR中选一个follower成为leader,为保证多个副本间的数据一致,将所有的副本follower各自的高于HW的数据部分截取掉,从新的leader同步数据
注意:这个只能保证数据一致性,不能保证数据不丢失或者不重复3. Kafka的Exactly Once实现
保证数据不丢失
-
将Producer的ack设置为-1(同步到ISR列表的所有follower),保证数据producer到partitons的数据不丢失,就是At Least Once
-
将Producer的ack设置为0(到broker),可以保证每条消息只会发送一次,即At Most Once
比较:
- At Least Once可以保证数据不丢失,但不能保证数据不重复,
- At Most Once可以保证数据不重复,但不能保证数据不丢失
每个 Partition 都至少得有 1 个 Follower 在 ISR 列表里,跟上了 Leader 的数据同步。
每次写入数据的时候,都要求至少写入 Partition Leader 成功,同时还有至少一个 ISR 里的 Follower 也写入成功,才算这个写入是成功了。
如果不满足上述两个条件,那就一直写入失败,让生产系统不停的尝试重试,直到满足上述两个条件,然后才能认为写入成功。
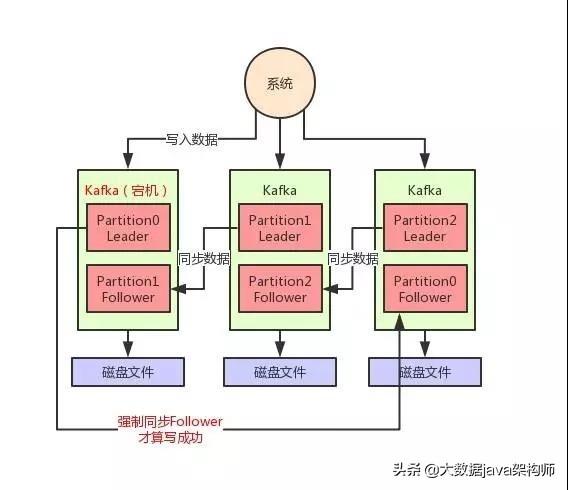
如上图所示,假如现在 Leader 没有 Follower 了,或者是刚写入 Leader,Leader 立马就宕机,还没来得及同步给 Follower。在这种情况下,写入就会失败,然后你就让生产者不停的重试,直到 Kafka 恢复正常满足上述条件,才能继续写入。这样就可以让写入 Kafka 的数据不丢失
保证数据不重复
Exactly Once = At Least Once + 幂等性
At Least Once 可以通过Producer的ACKS设置为-1来解决,在kafka的v0.11(含)之后引入了一个新特性:producer端的幂等性,无论Producer发给broker多少次,只要数据重复,broker只会持久化一条给到topic (相当于队列)
在Producer端通过参数enable.idempotence设置为true即可,相当于开起了producer端的幂等性:Producer在初始化的时候会被分配一个PID,发往同一个Partition的消息会附带Sequence Number 序列号。
Broker端会对<PID,Partition,Sequence Number>做主键缓存,当有相同主键信息只会持久化一条了
但是:系统只要重启就会更新PID,在不同的Partition上会有不同的主键,所以Producer的幂等无法保证跨分区跨会话的Exactly Once
如何保证数据不丢失,有不重复,Exactly Once?
第1步将Produce端的ack设置为-1
第2步将Produce端的enable.idempotence设置为true
4. Kafka生产者的事务机制
kafka的数据可以有很多的partition
场景:当producer个p0,p1,p2写入数据,0分区10条,1分区15条,正要给2分区写数据broker挂了,如果acks=1,有主分区没有写入完成没有返回ack,重启后producer会重试发送,那么就会与0分区和1分区的数据重复。
为了避免重复数据的问题,在kafka的v0.11版本之后引入了transactionID,将transactionID和PID(分区ID)绑定并保存事务状态到一个内部的topic中,当服务重启后该事务状态还能获取。前提要开启enable.idempotence
5. Kafka发送消息的流程
kafka的producer发送消息采用的是异步发送模式,一个main一个sender还有一个线程共享变量(RecordAccumulator)
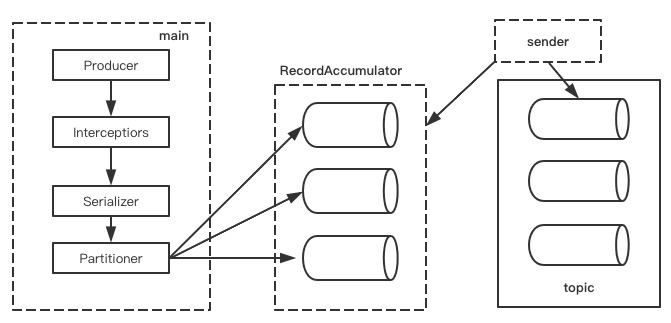
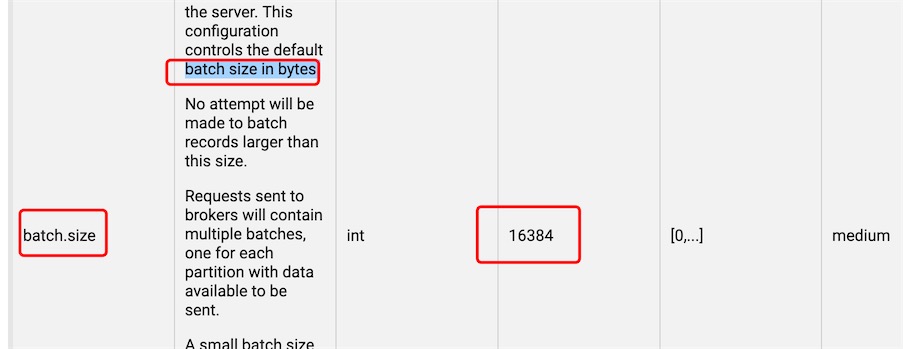
batch.size : 数据积累到多大以后,sender才会发送
linger.ms :单位毫秒, 如果一直没有达到batch.size,sender会等待linger.ms时间后就发送
查看官方文档http://kafka.apache.org/23/documentation.html

6. Kafka消费方式分析
kafka里consumer采用的是pull的方式从broker里取数据,topic的分区leader同步复制到follower也是拉取的方式
- push推的方式很难适应消费速率不同的消费者,消息发送速率是有broker决定的,典型的问题表现是消费端拒绝访问和网络堵塞
- pull的方式的消费速率是由consumer来确定,如果kafka的topic里没有数据,consumer会长期获取空数据,kafka会在消费时传入一个timeout,如果拉取没有数据,就会等待timeout时长后再返回
息队列的消费者都是以拉取数据的方式消费的
7. Kafka消费分区访问策略
一个consumer group中有多个consumer,一个topic里有多个partition,这就涉及了partition的分配问题,确定那个partition由哪个consumer来消费
kafka有三种分配策略:range(范围模式,默认的),roundrobin(均衡),sticky(粘性方式v0.11新增)
官方文档看Consumer 的配置http://kafka.apache.org/23/documentation.html

可以看到默认的消费策略是范围分区
range:默认的分区消费策略
无论多少个分区,只有一个消费者,那么所有分区都分配给这个消费者
每次新的消费者加入消费者组都会触发新的分配分配策略:
-
按照topic进行一组来分配给订阅了这个topic的consumer group中的consumer
-
n=分区数/消费者数量,m=分区数%消费者数量,第一个消费者分配n+m个分区,后面的分配n个分区
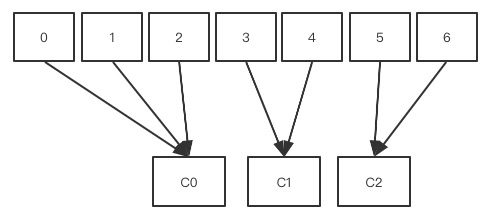
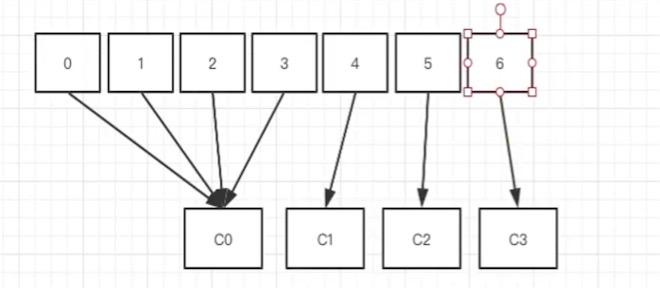
# 0~6 7个分区 读写都是leader分区, C0,C1,C2都是消费者(可动态加入,加入后重新分配消费者连接的分区),分配分区的算法:7/3 每人2个,多余的都给了C0 ,
# 例1,假设消费者组有两个消费者c0,c1,都订阅了t0和t1(topic),每个topic都有4个分区
c0: t0p0,t0p1,t1p0,t1p1
c1: t0p2,t0p3,t1p2,t1p3
# 例2,假设消费者组有两个消费者c0,c1,都订阅了t0和t1,每个topic都有3个分区
c0: t0p0,t0p1,t1p0,t1p1
c1: t0p2,t1p2
roundrobin:负载均衡的方式
按照消费者组里的消费者进行平均分配
Consuemer端可以通过配置:partition.assignment.strategy 修改值为 class org.apache.kafka.clients.consumer.RoundRobinAssignor
负载均衡也要看是否订阅了这个topic
每次新的消费者加入消费者组都会触发新的分配# 例1: 假设消费者组有两个消费者c0,c1,都订阅了t0和t1,每个topic都有3个分区
c0: t0p0,t0p2,t1p1
c1: t0p1,t1p0,t1p2
# 例2: 3个消费者c0,c1,c2, 有三个topic,每个topic有3个分区,对于消费者而言,c0订阅的t0,c1订阅的t0和t1,c2订阅的t0,t1,t2
c0: t0p0
c1: t0p1,t1p0,t1p2
c2: t0p2,t1p1,t2p0,t2p1,t2p2
Sticky:粘性策略
kafka的v0.11版本引入的:class org.apache.kafka.clients.consumer.StickyAssignor
Consuemer端可以通过配置:partition.assignment.strategy 修改值为 class org.apache.kafka.clients.consumer.StickyAssignor
上面两个策略每次新的消费者加入消费者组都会触发新的分配,其实是浪费性能的和可能造成不均匀的
主要实现的目的
- 分区的分配要尽可能的均匀
- 分区的分配尽可能的和上次分配保持一致
- 当两者冲突时,第一个目标优先第二个目标
# 例1:三个消费者c0,c1,c2,都订阅了4个主题,t0,t1,t2,t3,每个topic有两个分区
c0: t0p0,t1p1,t3p0
c1: t0p1,t2p0,t3p1
c2: t1p0,t2p1
# 这个分配很像负载均衡
如果这时c1退出消费者组,会触发新的分配,但要尽量保持均匀
# roundrobin策略下
c0: t0p0,t1p0,t2p0,t3p0
c2: t0p1,t1p1,t2p1,t3p1
# sticky策略下
c0: t0p0,t1p1,t3p0,t2p0
c2: t1p0,t2p1,t0p1,t3p1