 弹吉他的兔子
弹吉他的兔子
线上java应用故障从下面5个方面去排查性能问题:
- CPU
- 磁盘
- 内存
- GC问题
- 网络
1、CPU
一般来讲我们首先会排查cpu方面的问题。cpu异常往往还是比较好定位的。原因包括业务逻辑问题(死循环)、频繁gc以及上下文切换过多。而最常见的往往是业务逻辑(或者框架逻辑)导致的,可以使用jstack来分析对应的堆栈情况。
无限循环会让cpu爆满吗?的确会让cpu过高,但不会100%,
JAVA应用程序中的CPU密集性操作如下:
-
频繁的GC; 如果访问量很高,可能会导致频繁的GC甚至FGC。当调用量很大时,内存分配将如此之快以至于GC线程将连续执行,这将导致CPU飙升。
-
序列化和反序列化
序列化:把内存中的数据对象转化为可传输的字节序列过程称为序列化。
反序列化:把字节序列还原为对象的过程称为反序列化。
为什么需要序列化
1)序列化最终的目的是为了对象可以跨平台存储,和进行网络传输。而我们进行跨平台存储和网络传输的方式就是IO,而我们的IO支持的数据格式就是字节数组,最终存储到硬盘的数据格式就是字节数组。
2)因为我们单方面的只把对象转成字节数组还不行,因为没有规则的字节数组我们是没办法把对象的本来面目还原回来的,所以我们必须在把对象转成字节数组的时候就制定一种规则(序列化),那么我们从IO流里面读出数据的时候再以这种规则把对象还原回来(反序列化)。
3)如果我们要把一栋房子从一个地方运输到另一个地方去,序列化就是我把房子拆成一个个的砖块放到车子里,然后留下一张房子原来结构的图纸,反序列化就是我们把房子运输到了目的地以后,根据图纸把一块块砖头还原成房子原来面目的过程
4)序列化的核心作用是将对象状态保存和重建
什么时候使用序列化
1)凡是需要进行“跨平台存储”和”网络传输”的数据,都需要进行序列化。
2)本质上存储和网络传输都需要经过把一个对象状态保存成一种跨平台识别的字节格式,然后 其他的平台才可以通过字节信息解析还原对象信息。
3)json/xml的数据传递:
在数据传输(也可称为网络传输)前,先通过序列化工具类将Java对象序列化为json/xml文件。
在数据传输(也可称为网络传输)后,再将json/xml文件反序列化为对应语言的对象
-
正则表达式。 我遇到了正则表达式使CPU充满的情况; 原因可能是Java正则表达式使用的引擎实现是NFA自动机,它将在字符匹配期间执行回溯。我写了一篇文章“ 正则表达式中的隐藏陷阱 ”来详细解释原因。
-
线程上下文切换; 有许多已启动的线程,这些线程的状态在Blocked(锁定等待,IO等待等)和Running之间发生变化。当锁争用激烈时,这种情况很容易发生。
-
有些线程正在执行非阻塞操作,例如while (true)语句。如果在程序中计算需要很长时间,则可以使线程休眠。
问题:
1)while的无限循环会导致CPU使用率飙升吗?是
首先,无限循环将调用CPU寄存器进行计数,此操作将占用CPU资源。那么,如果线程始终处于无限循环状态,CPU是否会切换线程?除非操作系统时间片到期,否则无限循环不会放弃占用的CPU资源,并且无限循环将继续向系统请求时间片,直到系统没有空闲时间来执行任何其他操作。
2)频繁的Young GC会导致CPU占用率飙升吗?是
Young GC本身就是JVM用于垃圾收集的操作,它需要计算内存和调用寄存器。因此,频繁的Young GC必须占用CPU资源。
让我们来看一个现实世界的案例。for循环从数据库中查询数据集合,然后再次封装新的数据集合。如果内存不足以存储,JVM将回收不再使用的数据。因此,如果所需的存储空间很大,您可能会收到CPU使用率警报。
3) 具有大量线程的应用程序的CPU使用率是否较高?不一定
如果通过jstack检查系统线程状态时线程总数很大,但处于Runnable和Running状态的线程数不多,则CPU使用率不一定很高。
我遇到过这样一种情况:系统线程的数量是1000+,其中超过900个线程处于BLOCKED和WAITING状态。该线程占用很少的CPU。但是大多数情况下,如果线程数很大,那么常见的原因是大量线程处于BLOCKED和WAITING状态。
4) 对于CPU占用率高的应用程序,线程数是否较大?不是
高CPU使用率的关键因素是计算密集型操作。如果计算密集型任务,线程数不能太多,否则竞争cpu时间片反而更激烈,cpu频繁切换上下文线程,让任务变得更慢
5) 处于BLOCKED状态的线程是否会导致CPU占用率飙升?不会
CPU使用率的飙升更多是由于上下文切换或过多的可运行状态线程。处于阻塞状态的线程不一定会导致CPU使用率上升。
6) 如果分时操作系统中CPU的值us或sy值很高,这意味着什么?
您可以使用top命令查找CPU的值us和sy值top,如以下示例所示:
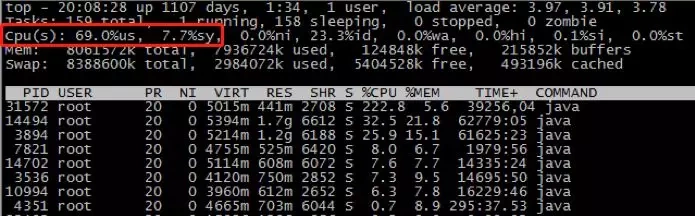
- us:用户空间占用CPU的百分比,us高是由程序引起的,通过分析线程堆栈很容易找到有问题的线程。
- sy:内核空间占用CPU的百分比,当sy高时,如果它是由程序引起的,那么它基本上是由于线程上下文切换的原因导致的
经验
如何找出CPU使用率高的原因?下面简要描述分析过程。
- 请首先检查线程数,JVM,系统负载等参数,然后使用这些参数来证明问题的原因。
- 其次使用jstack打印堆栈信息并使用工具分析线程使用情况(建议使用fastThread,一个在线线程分析工具)
以下是一个真实案例:
一天晚上,我突然收到一条消息,说CPU使用率达到了100%。然后我用jstack导出了线程栈信息。
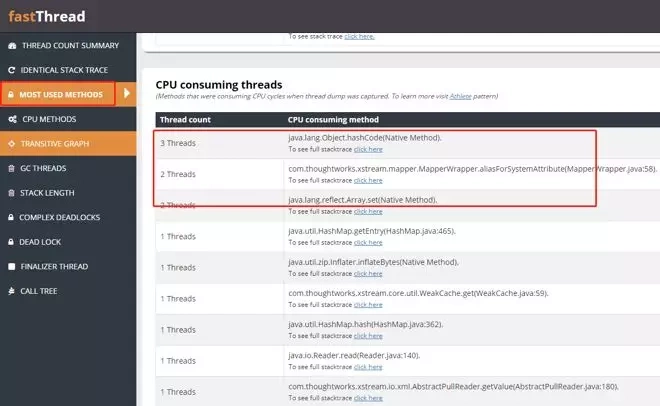
进一步检查日志:
onsumer_ODC_L_nn_jmq919_1543834242875 - priority:10 - threadid:0x00007fbf7011e000 - nativeid:0x2f093 - state:RUNNABLE
stackTrace:
java.lang.Thread.State:RUNNABLE
at java.lang.Object.hashCode(Native Method)
at java.util.HashMap.hash(HashMap.java:362)
at java.util.HashMap.getEntry(HashMap.java:462)
at java.util.HashMap.containsKey(HashMap.java:449)
at com.project.order.odc.util.XmlSerializableTool.deSerializeXML(XMLSerializableTool.java:100)
at com.project.plugin.service.message.resolver.impl.OrderFinishMessageResolver.parseMessage(OrderFinishMessageResolver.java:55)
at com.project.plugin.service.message.resolver.impl.OrderFinishMessageResolver.parseMessage(OrderFinishMessageResolver.java:21)
at com.project.plugin.service.message.resolver.impl.AbstractResolver.resolve(AbstractResolver.java:28)
at com.project.plugin.service.jmq.AbstractListener.onMessage(AbstractListener.java:44)
现在通过这个日志找到了问题:用于反序列化MQ消息实体的方法导致CPU使用率飙升
使用jstack分析cpu问题
jstack命令用于打印出给定的java进程ID或core file或远程调试服务的Java堆栈信息
使用格式:
$jstack [ option ] pid
$jstack [ option ] executable core
$jstack [ option ] [server-id@]remote-hostname-or-IP
参数说明:
pid: java应用程序的进程号,一般可以通过jps来获得;
executable:产生core dump的java可执行程序;
core:打印出的core文件;
remote-hostname-or-ip:远程debug服务器的名称或IP;
server-id: 唯一id,假如一台主机上多个远程debug服务;
# 1、先用jps命令找到java进程的pid
[ccslog@mvxl1842 22]$ jps
# 2、使用top命令找到cpu使用率高的线程
[ccslog@mvxl1842 22]$ top -H
注意看是command列是java

# 将CPU占用率高的pid转nid
[ccslog@mvxl1842 22]$ printf '%x\n' 66
42
# 查看cpu占用率高的进程堆栈信息
[ccslog@mvxl1842 22]$ jstack pid |grep '0x42' -C5

当然更常见的是我们对整个jstack文件进行分析,通常我们会比较关注WAITING和TIMED_WAITING的部分,BLOCKED就不用说了
# 查看jstack日志,如果WAITING之类的特别多,那么多半是有问题啦。
cat jstack.log | grep "java.lang.Thread.State" | sort -nr | uniq -c

频繁GC
# 先确定下gc是不是太频繁,格式,1000表示采样间隔(ms),pid是java进程id,可以通过jps命令获取,或者top命令获取
jstat -gc pid 1000
- S0C/S1C、S0U/S1U、EC/EU、OC/OU、MC/MU分别代表两个Survivor区、Eden区、老年代、元空间MetaSpace的容量和使用量。
- YGC/YGT : 新生区GC的耗时与次数
- FGC/FGCT:养老区GC的耗时与次数
- GCT:总耗时

上下文切换
针对频繁上下文问题,我们可以使用vmstat命令来进行查看
[ccslog@mvxl1842 22]$ vmstat pid
# cs(context switch)一列则代表了上下文切换的次数。

# 对特定的pid进行监控,cswch和nvcswch表示自愿及非自愿切换
[ccslog@mvxl1842 22]$ pidstat -w pid
2、磁盘
# 查看空间的使用情况
df -hl

# 更多时候是性能上的问题,
iostat -d -k -x 1
最后一列%util可以看到每块磁盘写入的程度,而rrqpm/s以及wrqm/s分别表示读写速度,一般就能帮助定位到具体哪块磁盘出现问题了。

3、内存
我们会先用free命令先来检查一发内存的各种情况。

堆内存
通常就是OOM,有6种情况
1、java.lang.StackOverflowError
栈内存溢出,对应-Xss参数设置的栈大小
2、java.lang.OutOfMemoryError: Java heap space
堆内存溢出,这个意思是堆的内存占用已经达到-Xmx设置的最大值,应该是最常见的OOM错误了。解决思路仍然是先应该在代码中找,怀疑存在内存泄漏,通过jstack和jmap(导出内存快照)去定位问题。如果说一切都正常,才需要通过调整Xmx的值来扩大内存。
# 查看java进程
jps -l
# 查看java进程的JVM信息,包括堆的初始,最大值,元空间大小等
jinfo -flags pid

# 打印jvm的垃圾回收详情信息
java -XX:+PrintGCDetails -version

3、java.lang.OutOfMemoryError: Metaspace 元空间报错
这个意思是元数据区的内存占用已经达到XX:MaxMetaspaceSize设置的最大值,排查思路和上面的一致,参数方面可以通过XX:MaxPermSize来进行调整(这里就不说1.8以前的永久代了)。
4、java.lang.OutOfMemoryError: unable to create native Thread
高并发下,线程开太多,没有内存空间分配
基本上还是线程池代码写的有问题,比如说忘记shutdown,所以说应该首先从代码层面来寻找问题,使用jstack或者jmap。如果一切都正常,JVM方面可以通过指定Xss来减少单个thread stack的大小。系统层面,可以通过修改/etc/security/limits.confnofile和nproc来增大os对线程的限制

使用JMAP定位代码内存泄漏
jmap -dump:format=b,file=filename pid来导出dump文件
4、高并发问题场景
- 线上系统CPU、IO、内存突然被打满,接口响应时间过长
- 线上系统突然卡死无法访问,频繁收到GC报警
- 线上系统突然内存溢出OOM,内存泄露无法定位
- 线上生产环境不知道如何设置JVM各种参数
- 线上系统SQL执行缓慢导致系统接口超时
- 线上数据库Mysql并发过高导致死锁
- 线上数据库Mysql莫名抖动无法定位
这些需要性能调优的问题,工作应用中不多见,但都会存在,一定存在,涉及的知识点有:首先Java SE基础、SSM、然后多线程原理、再到JVM基础,这部分打扎实了以后,接下来可以学习上手诸如Spring Boot、Spring Cloud、Redis、MQ等各种应用框架,这部分学完,做一到两个大型高并发项目基本心里就不慌了