 弹吉他的兔子
弹吉他的兔子
1、LinkedList链表
ArrayList是动态数组,随着数据量的增大扩容需要重新复制数组的,很耗时间。还有一个弊端,假如现在有 500 万张票据,现在要从中间删除一个票据,就需要把 250 万张票据往前移动一格,那简直是要崩溃的,这时我们应该使用LinkedList链表
链表分为三个层次:
- 第一层叫做“单向链表”,只有一个后指针,指向下一个数据;
- 第二层叫做“双向链表”,有两个指针,后指针指向下一个数据,前指针指向上一个数据。
- 第三层叫做“二叉树”,把后指针去掉,换成左右指针。
Node节点
主要是一个私有的静态内部类,叫 Node,也就是节点
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
它由三部分组成:
- 节点上的元素
- 下一个节点
- 上一个节点
我画幅图给你们展示下吧:

初始化
LinkedList<String> list = new LinkedList();
ArrayList初始化的时候,默认大小为 10,也可以指定大小,依据要存储的元素数量来,LinkedList就不需要。
2、常用操作
add方法增加元素
list.add("沉默王二");
list.add("沉默王三");
list.add("沉默王四");
add 方法内部其实调用的是 linkLast 方法:
/**
* Appends the specified element to the end of this list.
*
* <p>This method is equivalent to {@link #addLast}.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
linkLast(e);
return true;
}
linkLast,顾名思义,就是在链表的尾部链接
/**
* Links e as last element.
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
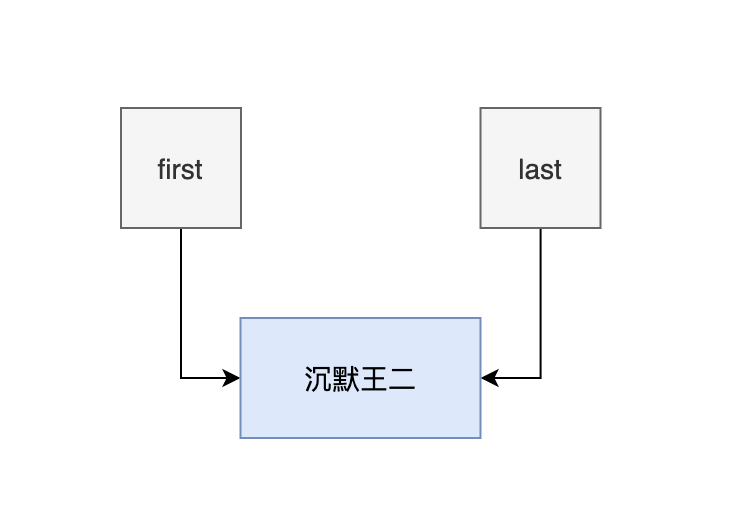
- 添加第一个元素的时候,first 和 last 都为 null。
- 然后新建一个节点 newNode,它的 prev 和 next 也为 null。
- 然后把 last 和 first 都赋值为 newNode。
此时还不能称之为链表,因为前后节点都是断裂的,如下图:
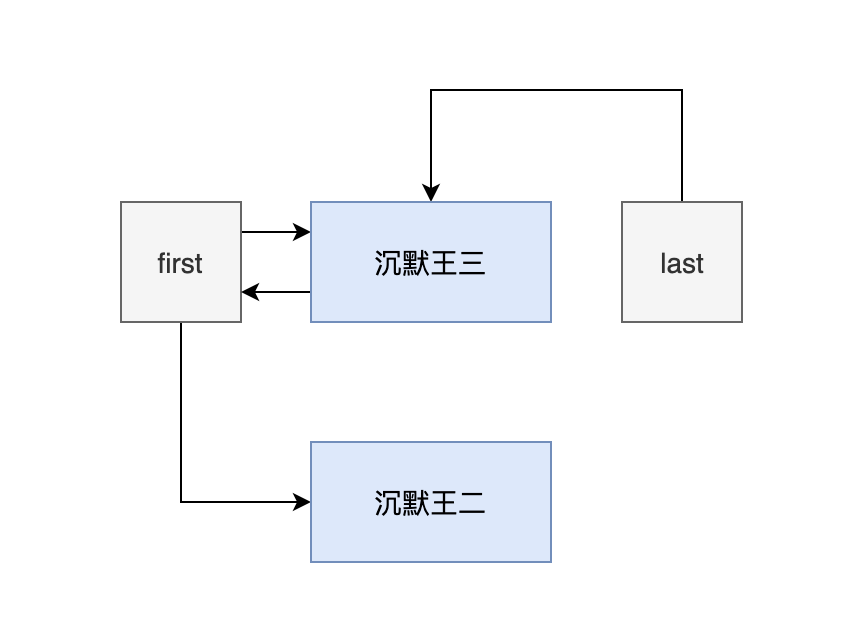
- 添加第二个元素的时候,first 和 last 都指向的是第一个节点。
- 然后新建一个节点 newNode,它的 prev 指向的是第一个节点,next 为 null。
- 然后把第一个节点的 next 赋值为 newNode。
此时的链表还不完整,如下图:
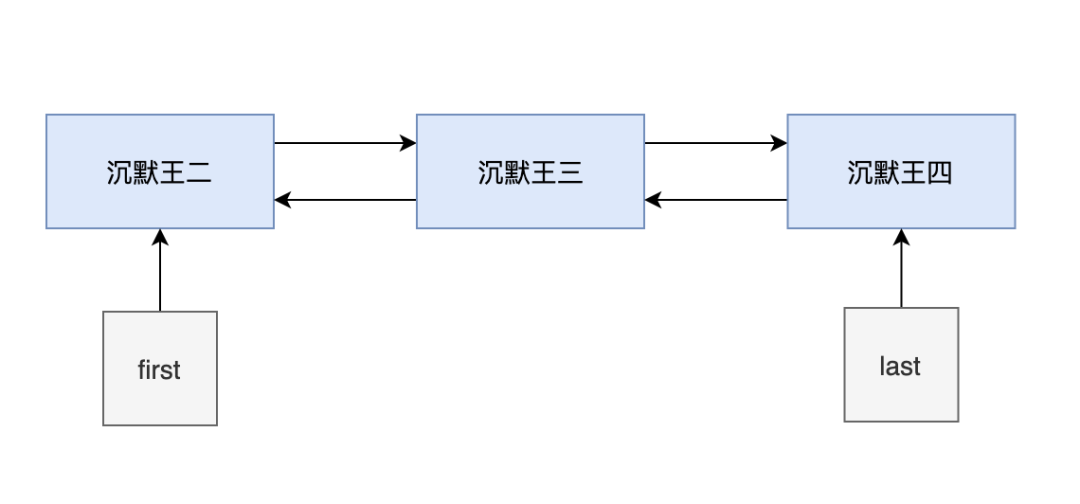
- 添加第三个元素的时候,first 指向的是第一个节点,last 指向的是最后一个节点。
- 然后新建一个节点 newNode,它的 prev 指向的是第二个节点,next 为 null。
- 然后把第二个节点的 next 赋值为 newNode。
此时的链表已经完整了,如下图:
这个增的招式,还可以演化成另外两个:
addFirst()方法将元素添加到第一位;addLast()方法将元素添加到末尾。
addFirst 内部其实调用的是 linkFirst:
/**
* Inserts the specified element at the beginning of this list.
*
* @param e the element to add
*/
public void addFirst(E e) {
linkFirst(e);
}
/**
* Links e as first element.
*/
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
linkFirst 负责把新的节点设为 first,并将新的 first 的 next 更新为之前的 first。
remove方法删除
这个删的招式还挺多的:
-
remove():删除第一个节点 -
remove(int):删除指定位置的节点内部其实调用的是 unlink 方法。
/** * Removes the element at the specified position in this list. Shifts any * subsequent elements to the left (subtracts one from their indices). * Returns the element that was removed from the list. * * @param index the index of the element to be removed * @return the element previously at the specified position * @throws IndexOutOfBoundsException {@inheritDoc} */ public E remove(int index) { checkElementIndex(index); return unlink(node(index)); }unlink 方法其实很好理解,就是更新当前节点的 next 和 prev,然后把当前节点上的元素设为 null
/** * Unlinks non-null node x. */ E unlink(Node<E> x) { // assert x != null; final E element = x.item; final Node<E> next = x.next; final Node<E> prev = x.prev; if (prev == null) { first = next; } else { prev.next = next; x.prev = null; } if (next == null) { last = prev; } else { next.prev = prev; x.next = null; } x.item = null; size--; modCount++; return element; } -
remove(Object):删除指定元素的节点内部也调用了 unlink 方法,只不过在此之前要先找到元素所在的节点:
public boolean remove(Object o) { if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) { unlink(x); return true; } } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) { unlink(x); return true; } } } return false; }这内部就分为两种,一种是元素为 null 的时候,必须使用 == 来判断;一种是元素为非 null 的时候,要使用 equals 来判断。equals 是不能用来判 null 的,会抛出 NPE 错误。
-
removeFirst():删除第一个节点内部调用的是 unlinkFirst 方法:
/** * Removes and returns the first element from this list. * * @return the first element from this list * @throws NoSuchElementException if this list is empty */ public E removeFirst() { final Node<E> f = first; if (f == null) throw new NoSuchElementException(); return unlinkFirst(f); }unlinkFirst 负责的就是把第一个节点毁尸灭迹,并且捎带把后一个节点的 prev 设为 null。
/** * Unlinks non-null first node f. */ private E unlinkFirst(Node<E> f) { // assert f == first && f != null; final E element = f.item; final Node<E> next = f.next; f.item = null; f.next = null; // help GC first = next; if (next == null) last = null; else next.prev = null; size--; modCount++; return element; } -
removeLast():删除最后一个节点
set方法更新元素
list.set(0, "沉默王五");
来看一下方法源码
/**
* Replaces the element at the specified position in this list with the
* specified element.
*
* @param index index of the element to replace
* @param element element to be stored at the specified position
* @return the element previously at the specified position
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
首先对指定的下标进行检查,看是否越界;然后根据下标查找原有的节点:
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
/**
* Tells if the argument is the index of an existing element.
*/
private boolean isElementIndex(int index) {
return index >= 0 && index < size;
}
看一下node方法
/**
* Returns the (non-null) Node at the specified element index.
*/
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
size >> 1:也就是右移一位,相当于除以 2。对于计算机来说,移位比除法运算效率更高,因为数据在计算机内部都是二进制存储的。
换句话说,node 方法会对下标进行一个初步判断,如果靠近前半截,就从下标 0 开始遍历;如果靠近后半截,就从末尾开始遍历。
找到指定下标的节点就简单了,直接把原有节点的元素替换成新的节点就 OK 了,prev 和 next 都不用改动。
indexof和get查找元素
这个查的招式可以分为两种:
- indexOf(Object):查找某个元素所在的位置
- get(int):查找某个位置上的元素
indexOf 的内部分为两种,一种是元素为 null 的时候,必须使用 == 来判断;一种是元素为非 null 的时候,要使用 equals 来判断。因为 equals 是不能用来判 null 的,会抛出 NPE 错误。
/**
* Returns the index of the first occurrence of the specified element
* in this list, or -1 if this list does not contain the element.
* More formally, returns the lowest index {@code i} such that
* <tt>(o==null ? get(i)==null : o.equals(get(i)))</tt>,
* or -1 if there is no such index.
*
* @param o element to search for
* @return the index of the first occurrence of the specified element in
* this list, or -1 if this list does not contain the element
*/
public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}
get 方法的内核其实还是 node 方法,这个之前已经说明过了,这里略过。
/**
* Returns the element at the specified position in this list.
*
* @param index index of the element to return
* @return the element at the specified position in this list
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
查这个招式还可以演化为其他的一些,比如说
getFirst()方法用于获取第一个元素;getLast()方法用于获取最后一个元素;poll()和pollFirst()方法用于删除并返回第一个元素(两个方法尽管名字不同,但方法体是完全相同的);pollLast()方法用于删除并返回最后一个元素;peekFirst()方法用于返回但不删除第一个元素。